Inbound email looks deceptively simple from a distance. A message arrives, you parse a few fields, and you post JSON to an application. In production, that mental model breaks down fast. Real messages include multipart bodies, attachments, forwards, bounces, machine-generated reports, and authentication context that all affect how safely a system can interpret and act on what arrived. The gap between receiving an email and emitting a trusted webhook event is larger than it first appears.
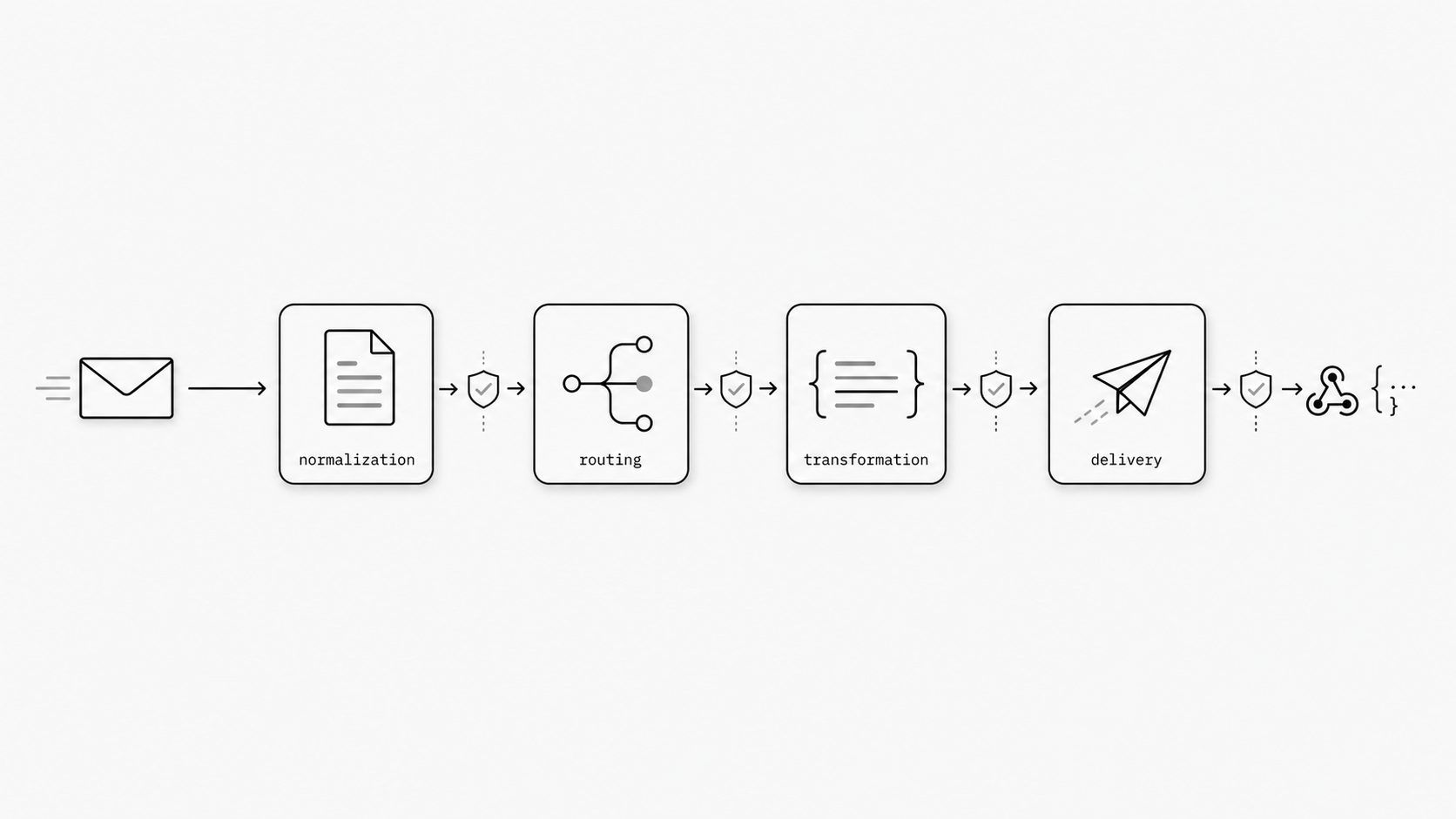
In this post, I use a simple architectural frame to make that gap easier to reason about. I break inbound email handling into four responsibilities: normalization, routing, transformation, and delivery. First, I explain why those responsibilities exist independent of any product choice, so you can use the model to evaluate an inbound email system on its own merits. Then I map that same model onto MailWebhook to show how a mailbox becomes an application-ready webhook event in practice. If you are designing or assessing an inbound email system, this is the lens I would start with.
The message arrives. The real system starts after that.
I have seen teams treat inbound email like a finished input the moment it lands in a mailbox. That assumption feels reasonable right up until the first strange forward, bounce, auto-reply, or multipart message hits production. Email already has formal structure - header fields and an optional body - yet real messages still arrive in many shapes that application code does not want to handle directly. Delivery status notifications add another machine-readable format of their own, which means even a message that looks like “just email” may follow different rules under the hood. So when someone says they want an email webhook, my first question is simple: what exact thing are we promising to deliver - the raw message, or a dependable event your system can trust? (RFC 5322 - Internet Message Format)
That is where this architecture model starts. I break the mailbox-to-application path into four stages because each stage solves a different failure mode that shows up in real systems.
First comes normalization. Internet email has a defined message format, but defined does not mean uniform in practice. Messages can carry different header patterns, nested content types, attachments, forwarded text, and machine-generated variants such as delivery reports. Normalization gives the system one stable internal representation before any business logic starts. I think of it as the moment we stop arguing with the raw message and start working with something our platform can reason about. (RFC 3464 - An Extensible Message Format for Delivery Status Notifications)
Then comes routing. Once the message is represented consistently, the platform can decide which workflow should receive it. This sounds small. It rarely is. A support reply, an order update, and a bounced notification may all enter through the same mail surface while needing completely different handling paths. Routing is where the system answers, “What kind of event is this, and who should own it?”
After that comes transformation. Different downstream systems want different payloads. One service may need sender, subject, and cleaned body text. Another may care about attachments, thread identifiers, or selected headers. Transformation shapes the normalized message into the contract each application expects. This is the point where inbound email parsing becomes useful in a practical sense, because the parsed material is no longer floating as raw email parts. It becomes an intentional payload for a real workflow.
Last comes delivery. The event still has to reach an endpoint in a way the receiving system can operate safely. A structured payload that never arrives cleanly does not create value. Delivery is where retries, endpoint behavior, and event posting discipline become part of the architecture rather than an afterthought.
I like this model because it is technology-neutral first. You can use it to evaluate any email to webhook design, including your own, before you ever compare vendors or implementation details. Then, once the model is clear, you can map a product onto it. In MailWebhook, this becomes a concrete operational path from message receipt to route selection to payload construction to webhook delivery. The product matters there. The architecture comes first.
The practical insight is this: the hard part of inbound email is not receiving the message. The hard part is preserving trust as the message crosses each boundary in the system. If normalization is weak, routing decisions drift. If routing is vague, transformation shapes the wrong payload. If transformation is loose, delivery sends something technically valid but operationally wrong. That is why I use the four-stage inbound email pipeline as the frame for the rest of this post. It gives backend engineers and platform architects a clean way to inspect where reliability is created, where ambiguity enters, and where an inbound email webhook either becomes production-grade or stays fragile. In the sections that follow, I will use that frame twice - first as an architecture lens, then as the way MailWebhook implements the mailbox-to-webhook path in practice.
So why do these stages exist in the first place?
When teams first look at inbound email parsing, they often picture one clean motion: receive a message, extract a few fields, send JSON to an app. That sounds efficient, but production email is shaped by formal message structure, uneven real-world inputs, and policy context, so a system has to preserve meaning before an application can safely act. (RFC 7489 - Domain-based Message Authentication, Reporting, and Conformance (DMARC))
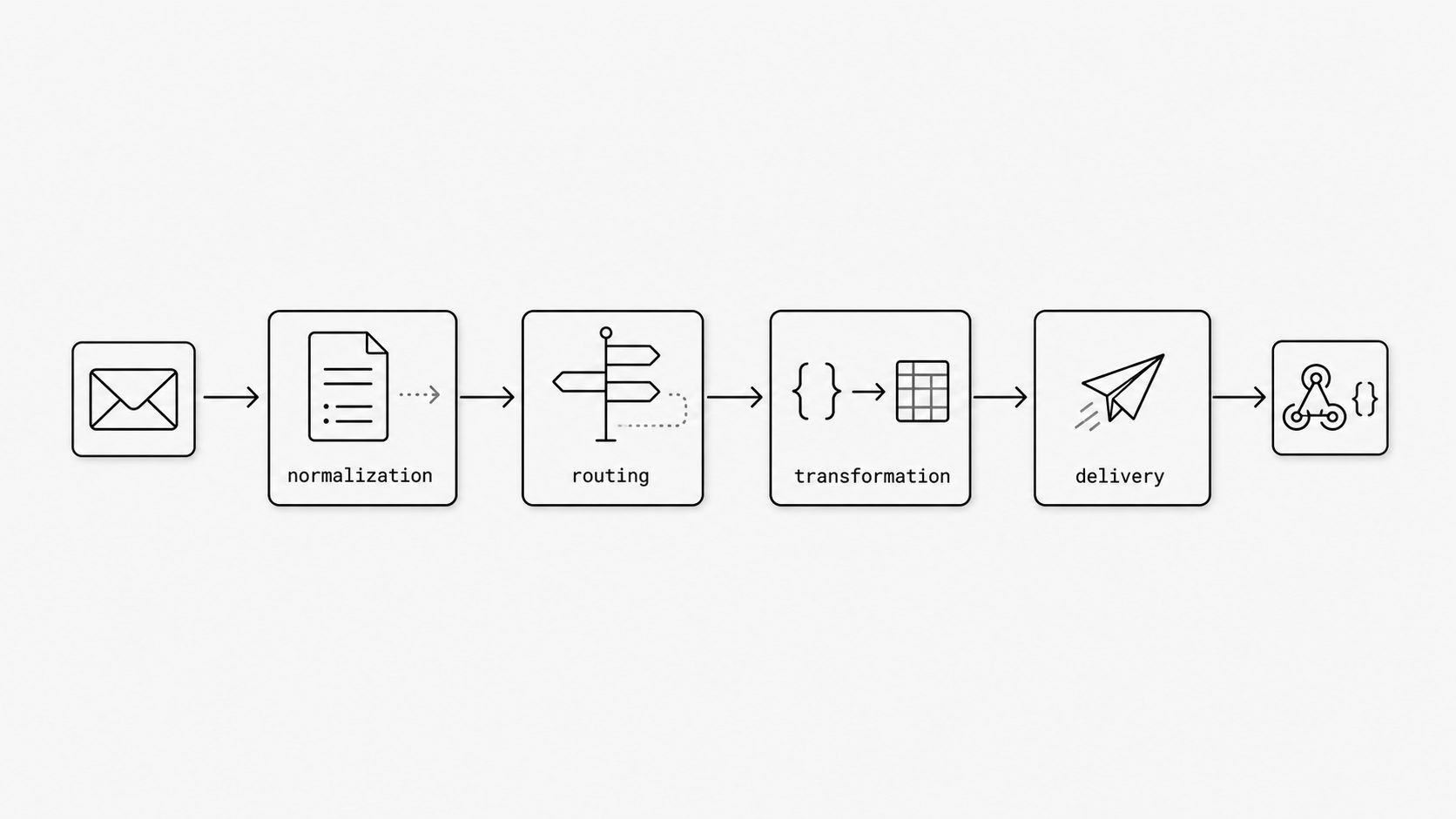
This framing matters because each stage answers a different operational question. Normalization asks what actually arrived in a form the platform can reason about consistently. Internet email has formal structure, but real inbound handling still includes variation across bodies, headers, attachments, and machine-generated reports such as delivery status notifications, so downstream logic benefits from a stable representation first. Routing then asks which workflow should own the message. That decision depends not only on content but also on trust signals. DKIM associates a domain with a message through a validated signature, and DMARC builds on aligned authentication checks and sender policy so receivers can make policy-aware handling decisions. Transformation asks what payload shape the application needs, while delivery focuses on handing that shaped event to the application boundary reliably. Separating these responsibilities gives teams a neutral way to evaluate whether a solution establishes consistency, applies decision logic, shapes output, and posts events safely. (RFC 3464 - An Extensible Message Format for Delivery Status Notifications)
Here is the payoff: once you frame inbound email as a sequence of responsibilities, you stop asking only whether a tool can parse mail and start asking whether it can create dependable meaning from mail. In practice, that gives engineers a fast evaluation checklist: where is message consistency established, where is ownership decided, where is output shaped for the consumer, and where is the final handoff made reliable and safe?
What this looks like inside MailWebhook
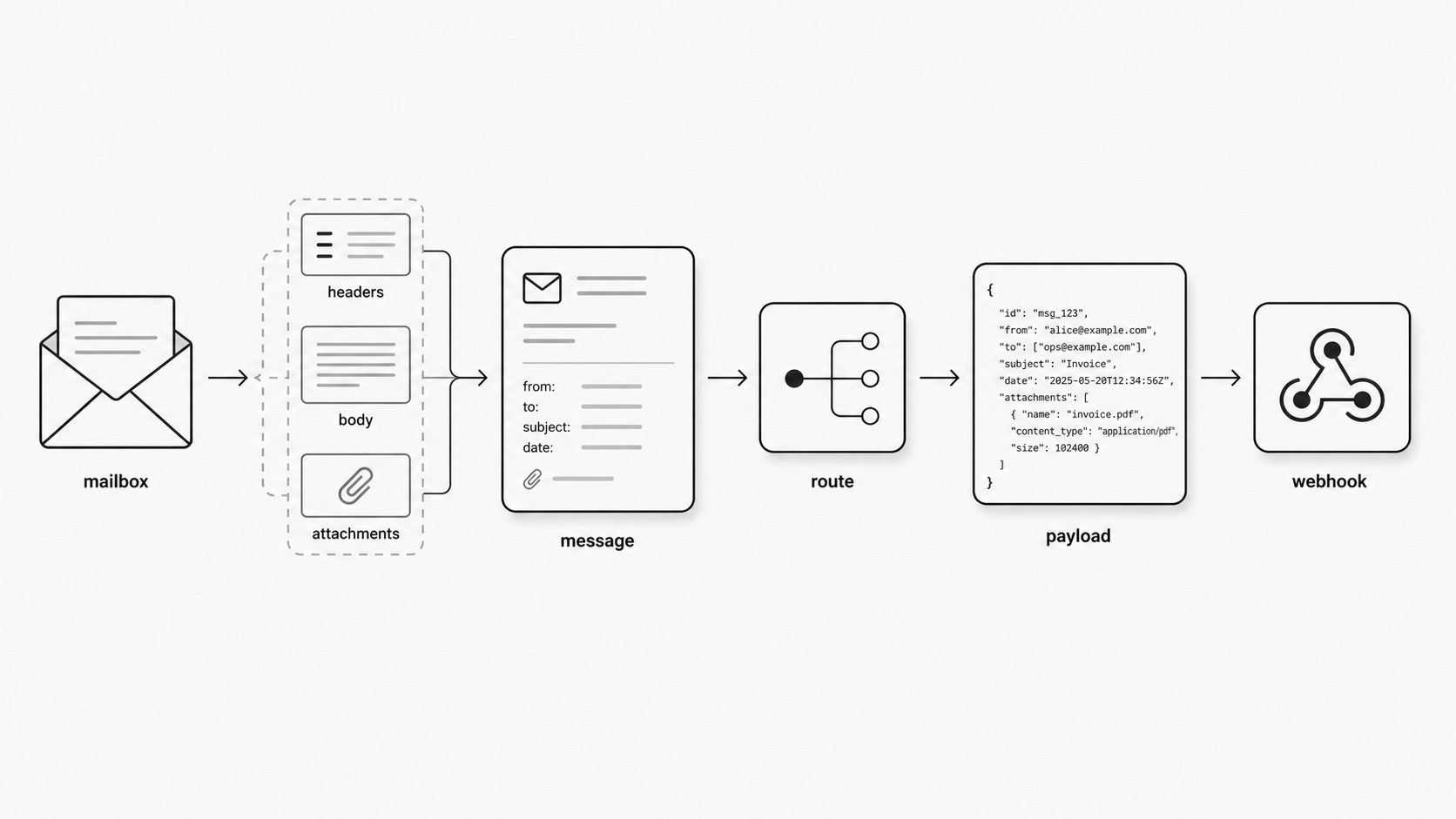
So what does this actually look like in practice? Inside MailWebhook, the journey starts with a messy, real-world email and ends with a structured event your application can act on. That gap matters because email is rarely one flat block of text. MIME gives messages a way to carry multiple content types and transfer encodings inside one message, which is why a single inbound email can contain plain text, HTML, inline media, and attachments all at once. Content-Disposition adds another layer by describing how individual parts should be handled, including attachments, which means the system has to understand the role of each part before it can build a useful payload. When I talk about an email webhook, I am talking about a system that can absorb that complexity and still hand your application one dependable event. (RFC 2045 - Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies)
For the current MailWebhook implementation references behind this flow, use the docs for mailboxes, route rules, route pipelines, Generic JSON, Custom JSON, and endpoints.
Normalization
Here is the simple version. A message lands in the mailbox layer. MailWebhook reads the raw source, breaks apart the MIME structure, identifies the meaningful headers and body parts, and creates a consistent internal object from that message structure. That internal object is the working form the rest of the system uses. I like this approach because application logic should not have to decode transfer formats, guess which body version to trust, or inspect attachment metadata directly when the platform can do that once, in a controlled way. (RFC 2183 - Communicating Presentation Information in Internet Messages: The Content-Disposition Header Field)
Routing
From there, MailWebhook selects the route that should own the message. In practice, that can mean matching on recipient address, mailbox alias, or other message attributes that were stabilized during normalization. The important point is that routing happens after the message has been made consistent enough to support a reliable decision. Once the route is known, the system can apply the right transformation rules for that destination.
Transformation
This is where the flow becomes more than an email parsing API. The goal is not only to extract fields. The goal is to shape a stable JSON contract that fits the receiving workflow.
That usually means promoting the parts an application cares about - sender, recipients, subject, cleaned body content, attachment descriptors, and selected headers - into structured fields, while leaving behind the low-level message complexity that belongs in infrastructure rather than business code. For teams building email to webhook integrations, this is the moment where the system becomes easier to reason about. Instead of treating every inbound message as a custom parsing problem, the application receives one predictable payload shape for a known route.
Delivery
The last move is delivery. MailWebhook posts that transformed payload to the configured endpoint as a webhook event. At that point, the message has crossed from mailbox semantics into application semantics. A raw email can be valid and still be hard for an application to consume directly because MIME and attachment metadata describe transport and presentation concerns, not the exact object model your service wants to process. The value of the mail to webhook path is that it closes that gap with a deliberate handoff: mailbox in, structured event out.
The practical takeaway is straightforward. When you evaluate MailWebhook, or any inbound email webhook design, you want to see one continuous path from message receipt to structured delivery, with each step reducing ambiguity for the next one. In MailWebhook, that means the mailbox receives the raw message, the platform interprets the MIME parts and attachment signals, the selected route determines how the payload should be shaped, and the final webhook carries application-ready data instead of email-shaped complexity. That is the architecture payoff for me: the system does the hard translation work once, at the platform boundary, so downstream services can respond to a clean event rather than wrestle with email itself.
Here is where trust is won or lost
Most email systems do not lose trust in dramatic failures. They lose it in quiet handoffs, when one stage makes a promise the next stage cannot keep. Reliable webhook delivery depends on surviving retries, duplicate attempts, slow endpoints, and transient network faults without changing the meaning of the event. (AWS Prescriptive Guidance - Retry with backoff pattern)
Stage-boundary reliability breaks first when the contract between stages is vague. If normalization hands routing a partially interpreted message, routing can select the wrong workflow. If routing does not produce a precise destination and rule set, transformation can build the wrong structured payload. AWS recommends retry with backoff for transient faults, but retries are only safe when the event crossing the boundary is deterministic. AWS also shows that adding jitter reduces retry clustering and unnecessary work under contention. Google SRE warns that retries can amplify overload and contribute to cascading failures when systems do not separate failure modes clearly. Stripe describes idempotent requests as a way to make repeated operations return the same result for the same request intent, which is essential when duplicate webhook deliveries occur. (AWS Architecture Blog - Exponential Backoff and Jitter)
Use four boundary checks immediately: ensure normalization produces one consistent internal object, routing creates an unambiguous execution context, transformation emits a stable JSON contract, and delivery uses exponential backoff plus duplicate-safe semantics. If those handoffs stay deterministic, transient failure is far less likely to become business failure. (Google SRE Book - Addressing Cascading Failures)
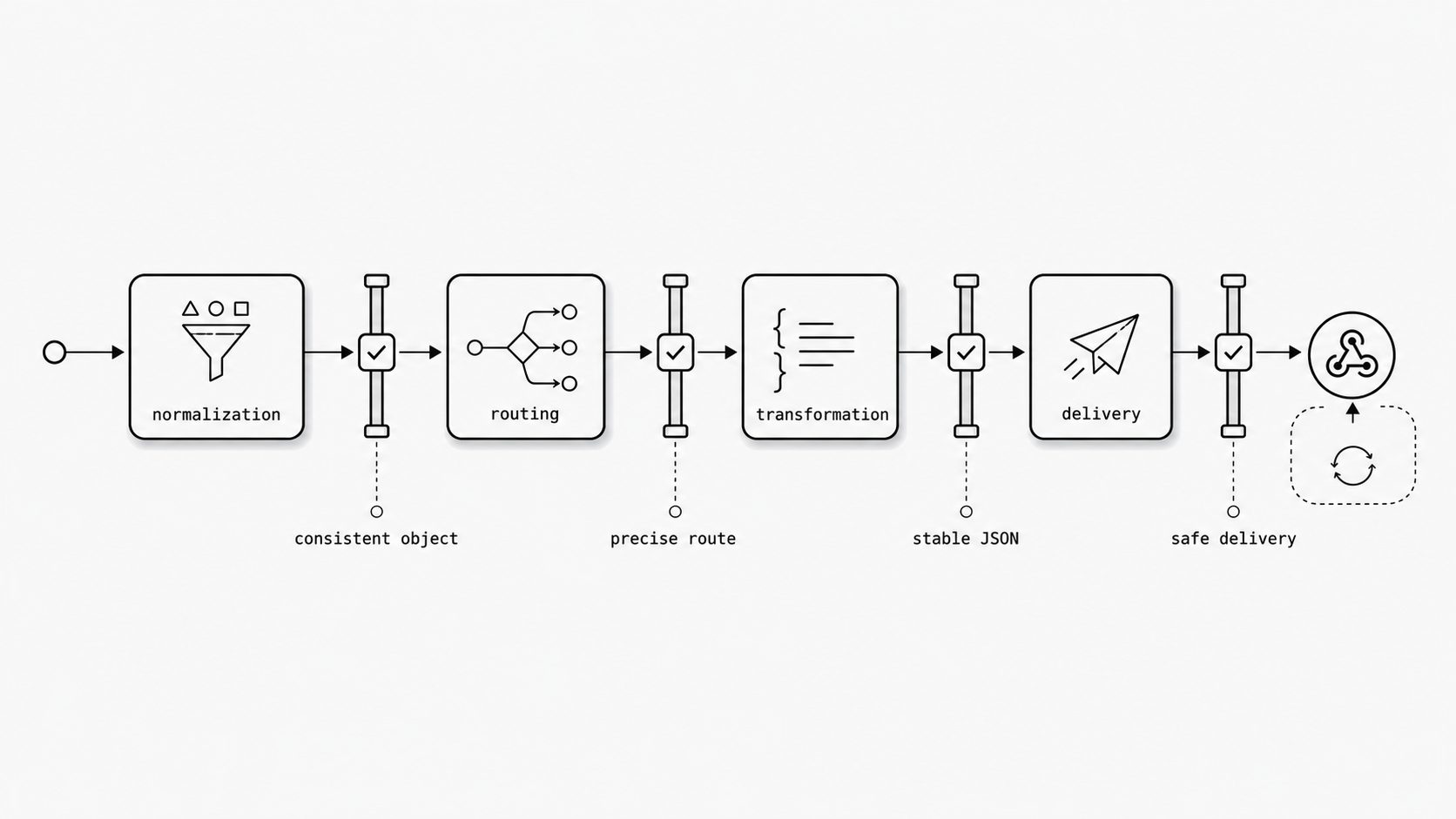
The main lesson is that inbound email reliability is not created by parsing alone. It is created when each responsibility in the architecture does its job clearly and hands the next one something deterministic to work with. Normalization establishes a stable internal representation. Routing decides ownership. Transformation shapes the application contract. Delivery gets that contract to the endpoint in a way the receiver can trust. When those boundaries are well defined, email becomes a dependable event source instead of a recurring source of ambiguity.
For product-level next steps, the mailbox-to-webhook path and the structured payload handoff have separate owner pages.
That is also why this post serves as the foundation for the rest of the engineering category. Each deeper topic lives inside one part of the model: normalization, routing logic, transformation approaches, and delivery concerns such as retries and idempotency. Once the four-stage frame is clear, the implementation details stop feeling like isolated tactics and start fitting into one coherent system design. That is the shift I want readers to leave with: not just how to parse inbound email, but how to architect the full path from raw message to trusted webhook event.