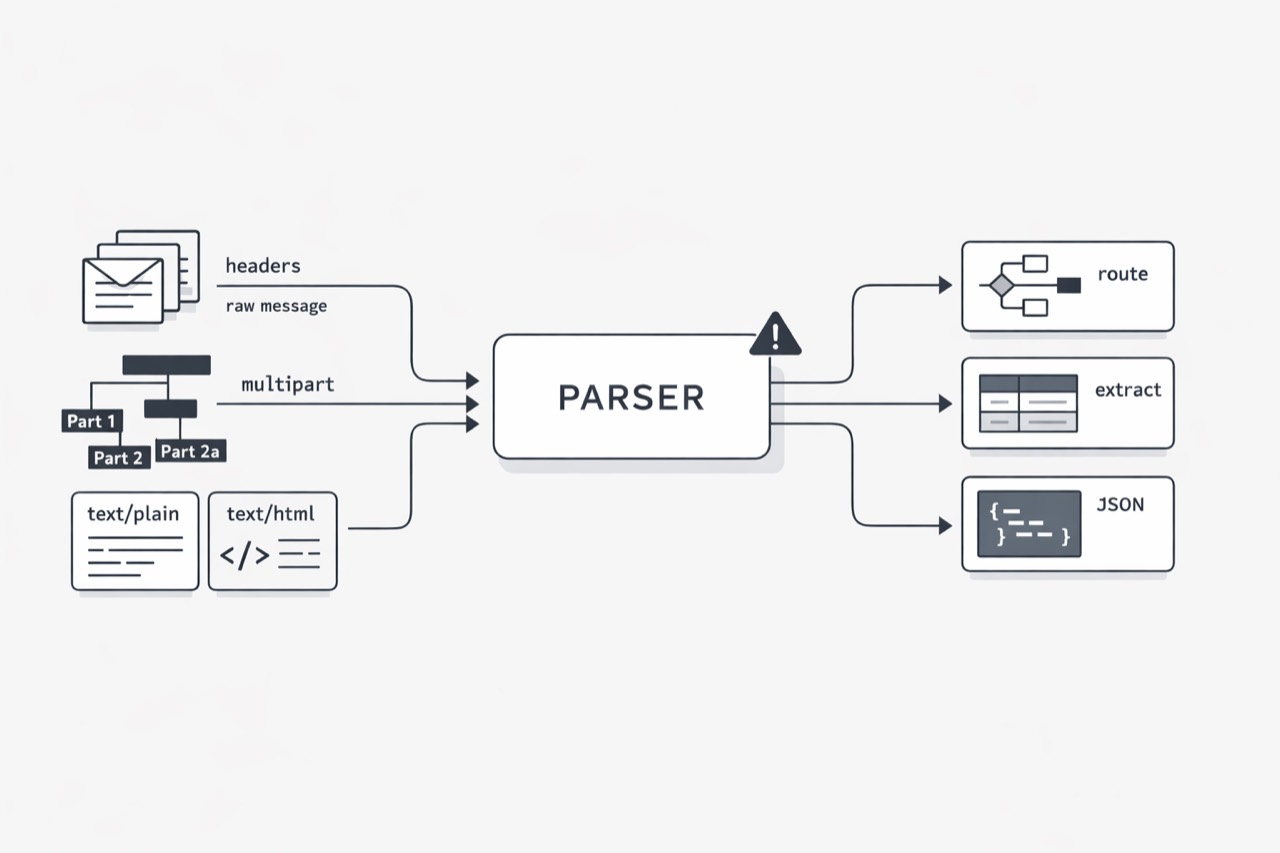
Raw email parsing has a way of looking deceptively manageable in the lab. A few sample messages come through, headers seem readable, the body appears extractable, and it is easy to believe the hard work will start later in classification, enrichment, or workflow logic. In practice, I have found the opposite. The reliability risk begins at the ingestion boundary, where MIME structure, transfer encodings, folded headers, and multiple body representations all shape what the rest of the system believes is true.
That matters more now because email is rarely parsed for display alone. Structured payloads now feed routing, search, automation, AI summarization, archives, and compliance workflows. Once parsed output becomes shared application input, a small interpretation mistake stops being a local bug and becomes a cross-system defect. This is why MIME parsing becomes a reliability problem faster than many teams expect: the format is flexible, real-world traffic is messy, and downstream systems are far less tolerant of ambiguity than email itself.
The structure problem starts earlier than most teams think
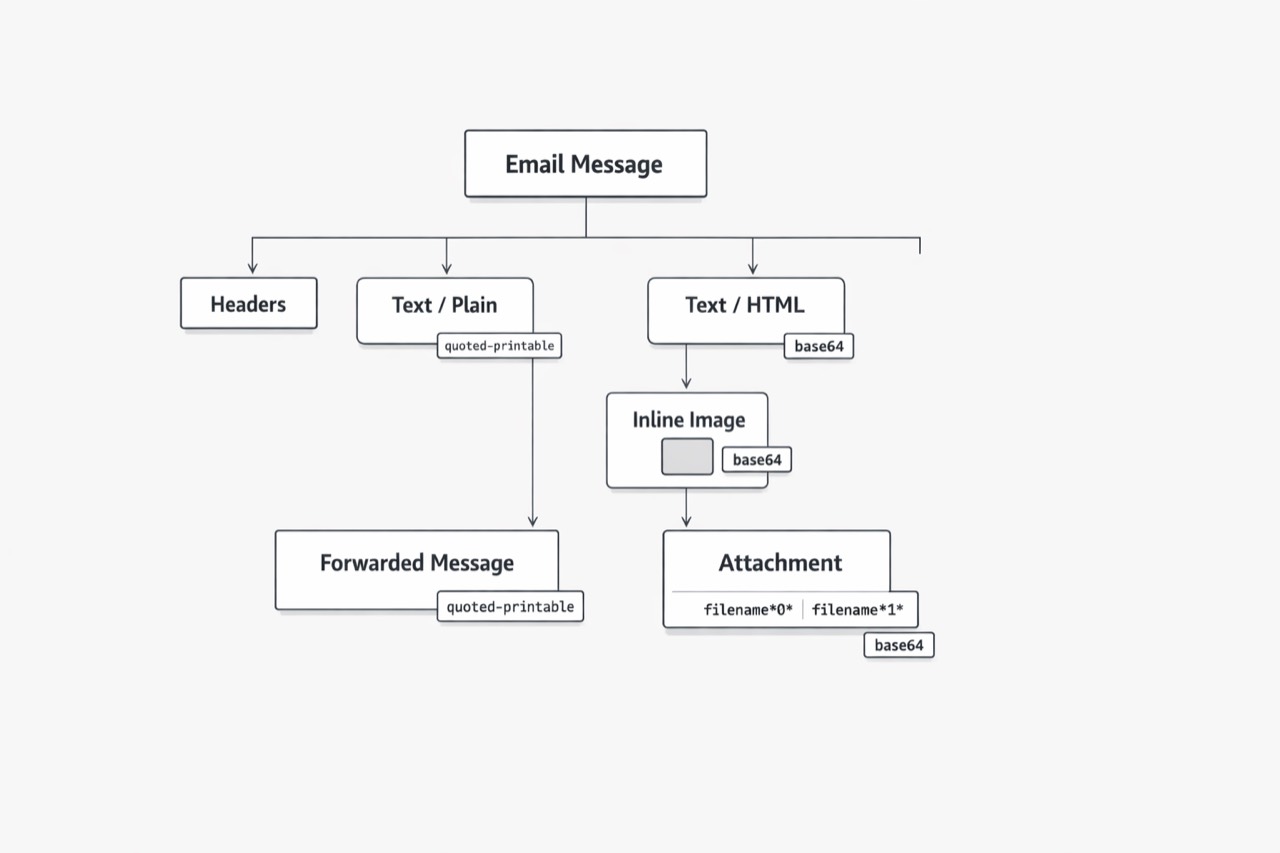
What looks like one email in the UI is often a multipart MIME tree with nested messages, attachments, and multiple body representations, so the first parsing mistake usually happens before extraction even begins. (RFC 2046 - Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types)
Teams often assume the difficult work starts when they classify or extract content, but MIME structure and transfer encodings complicate the message much earlier. A single message can contain text, HTML, inline assets, forwarded content, and attached files, while body data may arrive encoded with mechanisms such as quoted-printable or base64 that must be decoded consistently before downstream processing. Parameter handling adds another layer, because MIME values such as filenames may use continuations plus character set and language metadata, which affects how attachment context is reconstructed. (RFC 2045 - Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies)
Treat raw email as structured content ingestion rather than simple string parsing. In practice, test multipart trees, nested messages, content-transfer decoding, and RFC 2231-style parameter reconstruction early, so search, workflow, and AI systems start from a faithful message shape instead of inheriting parser errors. (RFC 2231 - MIME Parameter Value and Encoded Word Extensions: Character Sets, Languages, and Continuations)
Then the headers start asking for cleanup you did not plan for
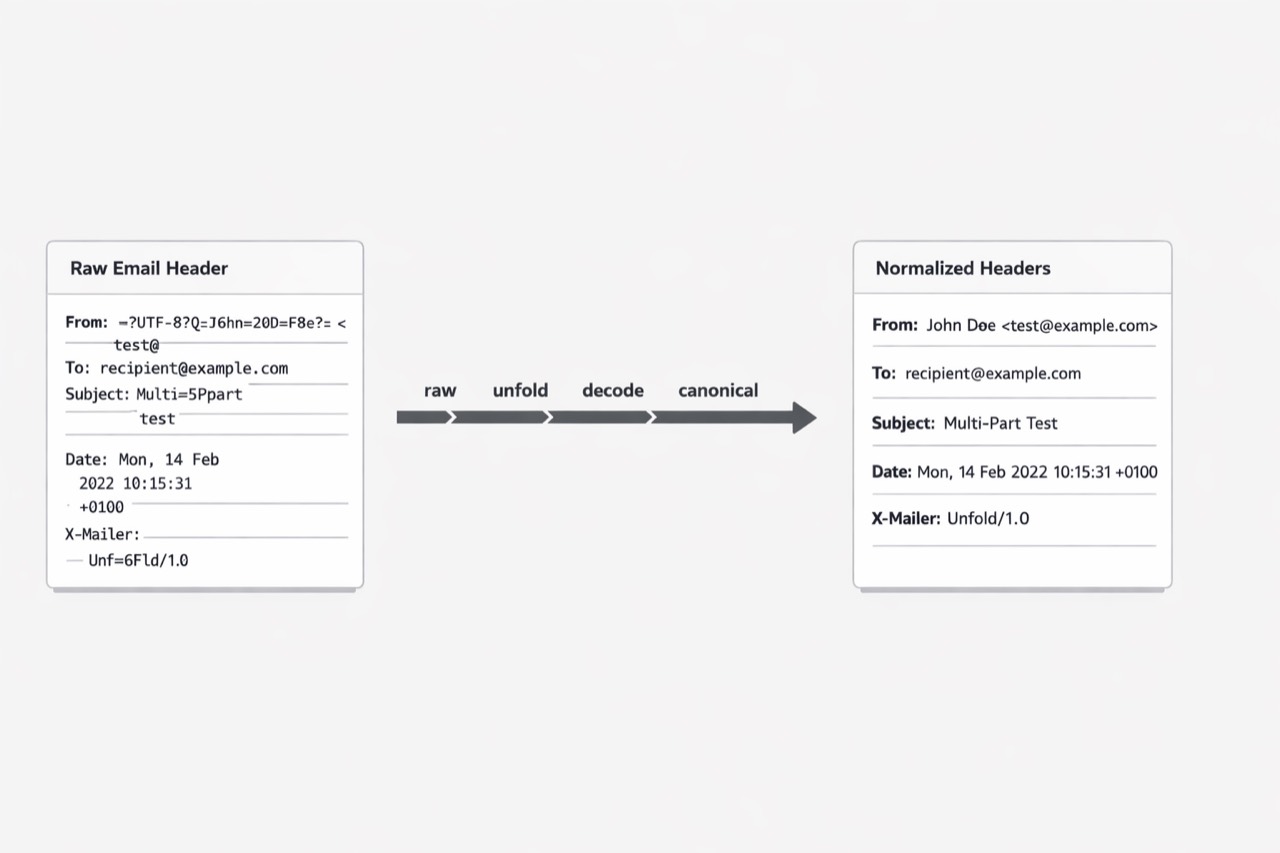
I usually see the second wave of pain arrive after the MIME tree is under control. The message finally opens, the parts look readable, and someone says, “Great, now we can route by Subject, From, and Reply-To.” That is the moment the hidden work starts. Email headers look like plain key-value data in a sample message, yet production traffic quickly proves otherwise. A single field can span multiple lines through legal folding rules, so the value you inspect may be incomplete until you unfold it first. Human names and subjects can also carry encoded words for non-ASCII text, which means a header that looks garbled at first glance may still be valid and meaningful once decoded. And modern internationalized messages may include UTF-8 in header field values, which breaks the old assumption that header content is safely limited to basic ASCII. (RFC 5322 - Internet Message Format)
So what does this mean in practice? It means I cannot treat headers as clean metadata that arrives ready for automation. I have to normalize them before I trust them. That usually starts with unfolding continuation lines in a safe, deterministic way, because policy checks run against the logical field value, not the raw wrapped presentation. Then I need consistent decoding for encoded words, especially in fields people use for routing, labeling, and search, because the same visible text can appear in more than one legal wire format. On top of that, UTF-8 support changes the baseline for parsers that were built around older mail assumptions, so any workflow that compares, stores, or indexes header values needs a clear normalization path for international text. (RFC 2047 - MIME Part Three: Message Header Extensions for Non-ASCII Text)
You might be wondering: is this really a big deal if my system only reads a few common fields? In my experience, yes. The trouble is not only parsing one header. The trouble is making many small decisions the same way every time. Do I trim whitespace before matching? Do I collapse internal line breaks after unfolding? Do I lowercase field names while preserving field values? Do I decode first and validate second, or the other way around? Those choices become product behavior. If they drift across services, one system files a message correctly while another misses the same rule because it saw a slightly different representation of the same header value. (RFC 6532 - Internationalized Email Headers)
That is why header work feels deceptively expensive. The input is legal. The parser often survives. The failure shows up later, when routing logic, ticket creation, deduplication, or compliance checks act on half-normalized data. What looked like a tiny helper function turns into a contract that every downstream consumer now depends on.
The useful shift is to stop thinking of headers as strings and start treating them as normalized application inputs. For me, that means one shared normalization layer with a fixed order of operations: parse field boundaries, unfold legal line breaks, decode encoded words where applicable, preserve original raw values for audit, and emit a canonical form for automation. Once I do that, downstream systems can evaluate policy against one stable representation instead of reinterpreting the same message in different ways. That does not remove every mail oddity, yet it sharply reduces the number of silent mistakes that only appear after the message has already entered business workflows.
Even after you decode the message, the body still is not obvious
This is where many teams think the hard part is over, but email can still contain more than one valid body at once. MIME allows multipart/alternative so plain text and HTML may both represent the same message, which turns body selection into a policy choice, not just a decoding step.
It is tempting to always prefer text/plain and move on, but that can quietly break real workflows. In some messages, the HTML version preserves links, tables, or visual structure that the text version flattens or loses, and MIME does not require one universal body to always win among alternative representations. The operational problem grows when different systems choose differently: search may want readable text, extraction may need HTML structure, and archives may need every representation because presentation can matter to the record. Content-Disposition adds another layer because it provides presentation guidance and filename metadata that can influence whether a part is treated as inline content or as a separate payload. (RFC 2183 - Communicating Presentation Information in Internet Messages: The Content-Disposition Header Field)
The practical fix is to define body selection as an explicit policy layer. Decide which MIME parts count as body candidates, when both text and HTML should be preserved, which representation feeds search or summarization, and how disposition metadata affects inline versus attachment handling. Then emit a stable model such as primary_body, alternate_bodies, rendered_text, and attachments so downstream systems stop inventing conflicting answers from the same email.
This is where a small parser miss turns into a bigger systems problem
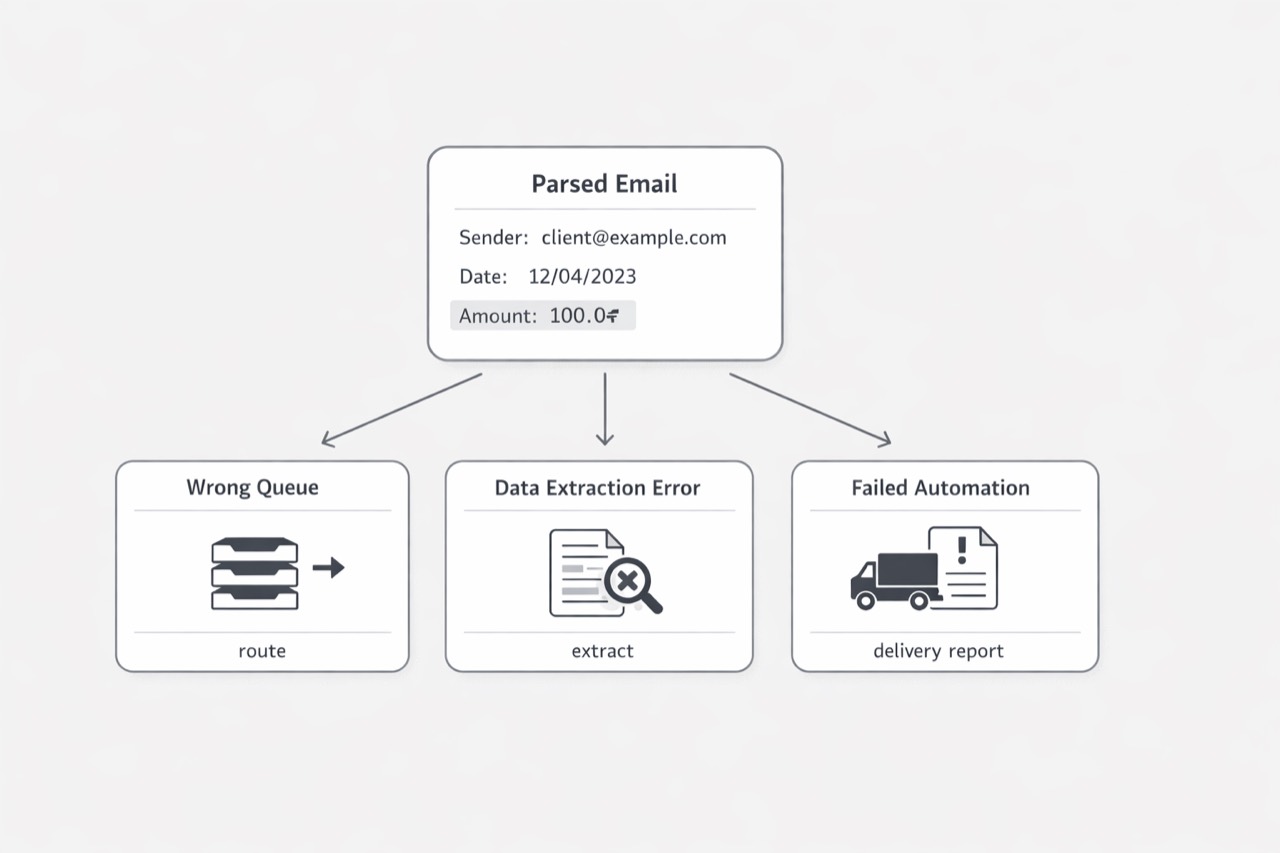
A parser can be only slightly wrong and still cause a much larger business failure, because downstream systems often treat parsed mail data as application truth. Internet message format and MIME both define structured elements that software uses for handling and interpretation, so a bad parse can quietly send a message down the wrong path.
The real damage usually appears one or two steps later. A message can land in the wrong customer queue because a parsed field was incomplete, an extraction job can miss the payload it expected because the selected body was wrong, and an automation flow can misread a delivery report even though delivery status notifications use a machine-readable multipart format meant for software processing. That spread happens because email pipelines work like trust chains: once the parser normalizes headers, bodies, and message type, later systems typically stop questioning the interpretation and make clean decisions from whatever they were given. (RFC 3464 - An Extensible Message Format for Delivery Status Notifications)
Treat email parsing like a boundary service, not a helper utility. Keep one authoritative parsed model, preserve raw messages for replay, and let downstream systems distinguish confirmed structure from best-effort interpretation. Then test beyond parsing itself into routing, extraction, and storage, because that is where the true blast radius of a parser defect becomes visible.
The lesson for me is that email parsing should not be treated like a thin utility sitting off to the side of the product. It is a boundary layer that converts a permissive, decades-evolved wire format into structured data that many stricter systems will trust without hesitation. That conversion is where reliability is either established or quietly lost.
If a team treats MIME handling, header normalization, and body selection as explicit architectural concerns, many downstream failures become preventable. If it treats them as incidental string processing, the cost eventually shows up somewhere else: wrong routing, weak search, broken automations, confusing payloads, and support work that is hard to trace back to the parser. Raw email does not have to be unmanageable, but it does demand more respect than its first happy-path examples suggest.