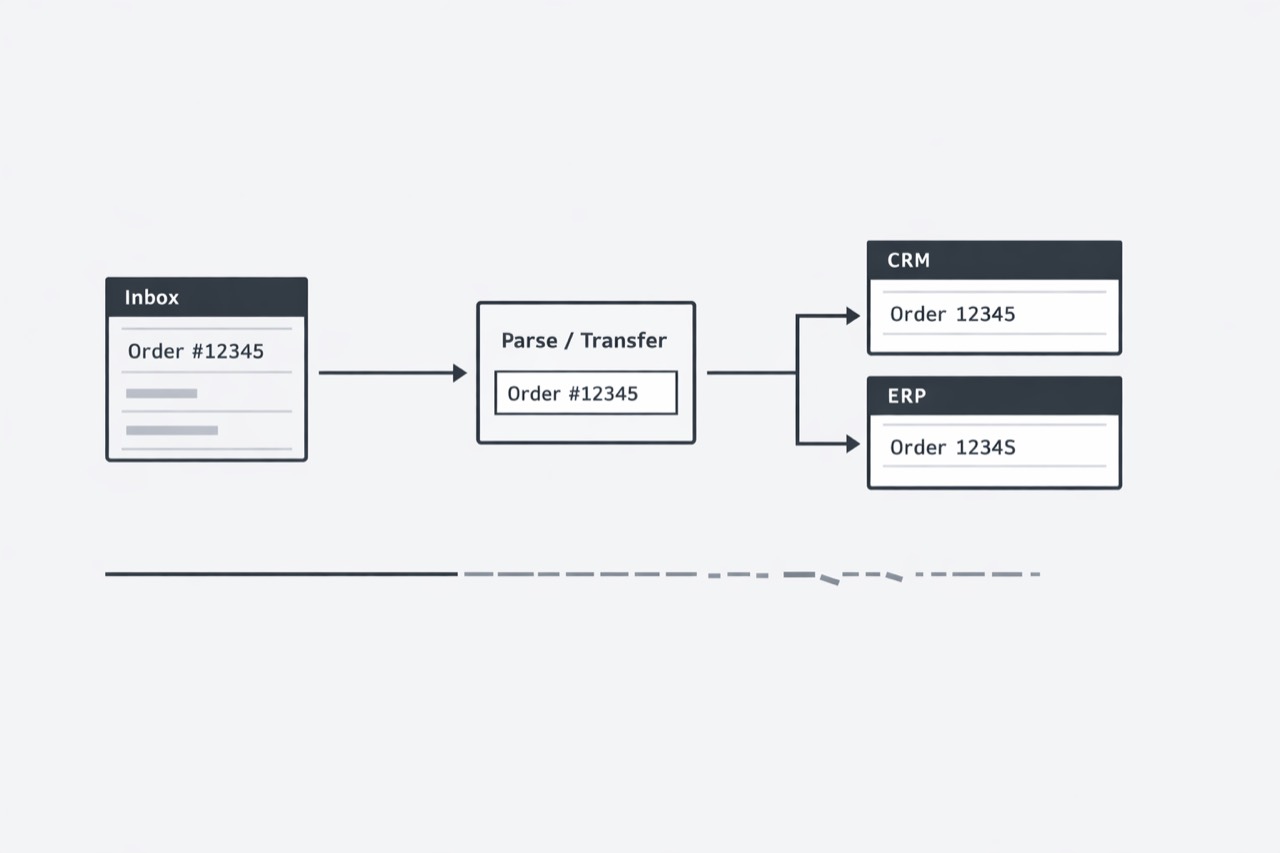
Most teams do not label inbox copy-paste as a data problem. They label it as routine operations work: read the email, open the system, move the details over, keep the queue moving. On the surface, that framing makes sense. The task looks small, familiar, and easy to absorb into daily work.
I think that framing misses the real risk. When important facts arrive by email and are then recreated by hand inside ERP, CRM, ticketing, or internal tools, the business is not just spending labor. It is allowing critical information to pass through an uncontrolled quality layer before that information becomes operational truth. That is a much bigger issue than simple efficiency.
As more workflows feed core systems, the downstream cost of small changes grows. A date entered slightly wrong, a part number normalized incorrectly, or a price copied in the wrong format can move far beyond one user action. It can affect fulfillment, billing, reporting, compliance, customer commitments, and later decisions made from records that now look official.
This is why I reframe copy-paste work from email into systems as a data integrity issue, not just a labor issue. For operations leaders and application owners, the important question is no longer only how much time teams spend moving information. It is whether the facts that enter core systems still match the facts that originally arrived.
Every time someone re-types a fact, the business takes a silent bet
I have seen this pattern more times than most teams want to admit. A customer sends a date, price, part number, shipping address, or renewal term by email. Someone opens the message, flips to the ERP or CRM, and types it in again. Nothing looks dramatic. There is no outage. No red screen. No alert. Still, the business just accepted a quiet risk. (What Is Bad Data? - IBM)
That risk is simple: the second version of the fact may not match the first. Under repetition, speed, and context switching, people do not perform like scanners. They summarize, transpose, skip, and normalize. A single field can move from “close enough” to operationally wrong in one keystroke. (What Is Dirty Data? - IBM)
You might be thinking: is this really worth worrying about? I think it is, because the act feels small while the exposure compounds. The first person only re-types one line. The company inherits everything downstream that line touches - inventory, invoicing, fulfillment, reporting, and customer trust.
What makes re-keyed data failure dangerous is that it hides inside normal work. The email was real. The employee was careful. The system accepted the value. So the organization treats the record as clean, even when the stored fact is already a few characters away from the source.
IBM notes that bad data often comes from human error, including typos during manual data entry. That matters because most operations teams still have important facts arriving in inboxes before they ever reach a structured workflow. Orders, change requests, vendor updates, pricing approvals, onboarding details, claims, and service requests often begin as unstructured messages. Once a human becomes the bridge between the message and the system, accuracy depends on attention surviving routine work at scale.
IBM also describes manual entry as error-prone because repetition, time pressure, and cognitive load wear down accuracy. In my experience, that is the part leaders underestimate. They review the task and see something easy. They do not review the environment around the task: ten browser tabs open, a queue building, similar-looking values, and a person trying to move fast enough to keep work flowing. In that setting, re-keyed data failure is not unusual. It is predictable.
A useful way to see it is this: every re-typed field creates a small gap between what the sender said and what the business stored. Most gaps stay invisible at first. They surface later as a wrong shipment, a billing dispute, a missed SLA, or a report nobody fully trusts. By then, the original email is buried in a mailbox and the system of record carries more authority than the source message that started the process.
That is why I do not treat this as a productivity annoyance. I treat it as a data integrity exposure. Labor is part of the cost, of course. The larger issue is that the company keeps making decisions from facts that may have been reshaped during transfer.
Here is the shift I want operations leaders and application owners to make: stop asking only, “How many minutes does this step take?” Start asking, “How many business-critical facts are being re-created by hand between source and system?”
That question changes the conversation. It moves the issue from clerical effort to controllable risk. It also gives you a sharper test for where to act first. Look for workflows where three conditions are true:
The email contains values that drive money, commitments, or compliance.
A person must read and re-enter those values into a business system.
The downstream system is treated as truth once the entry is saved.
When those three conditions show up together, you are no longer looking at harmless admin work. You are looking at a recurring point where the organization gambles that human re-entry will preserve the original fact every single time. It will not.
That is the core idea behind re-keyed data failure: the problem starts long before anyone notices an error. It starts the moment the business asks a person to recreate a fact that already existed once.
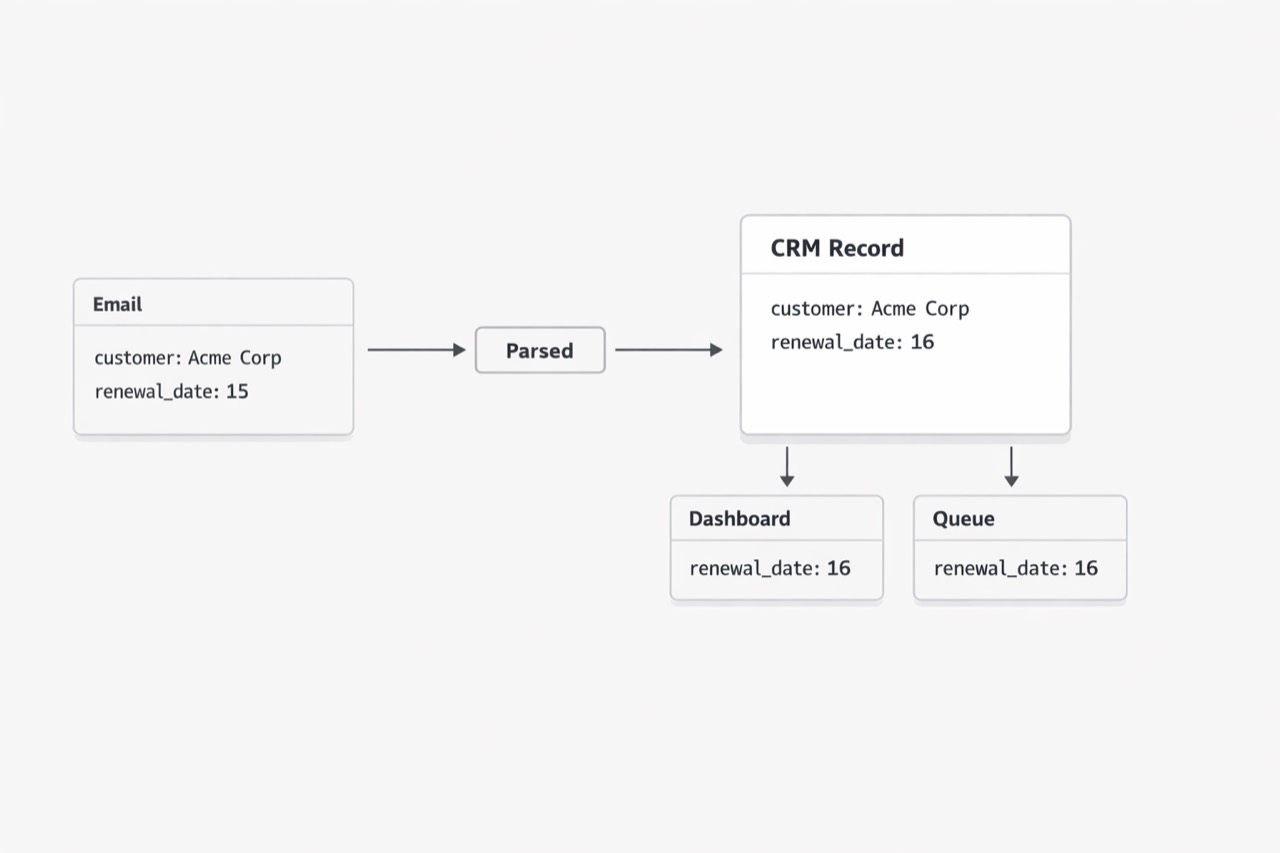
The bigger problem shows up when the system becomes the wrong source of truth
I have learned that the real damage rarely happens at the moment someone moves a value from an email into an application. It happens a step later, when everyone starts trusting the saved record more than the original message. (Data Quality: Why It Matters and How to Achieve It - Gartner)
That is the moment a small inconsistency hardens into operating reality. The CRM says the renewal date is the 15th. The ERP says the unit price is approved. The ticket says the address is final. Once those values live inside a named system, teams organize around them. Dashboards pull them in. Work queues depend on them. Managers review them in meetings. Very few people go back to the email unless something breaks. (The True Cost of Poor Data Quality - IBM)
You might ask: why does that matter if the difference is only one field? Because data quality is not just about whether a value exists. IBM frames it through dimensions like accuracy, completeness, timeliness, and consistency. When an email says one thing and the downstream application stores another, the organization now has a consistency problem and, often, an accuracy problem too. The bigger risk is social as much as technical - the wrong value starts to look official simply because it sits inside the official tool.
This is what I mean by system-of-record drift. The source event enters through email. A person interprets it, reshapes it a little, and saves it into a line-of-business system. From there, the stored version gains status. It becomes easier to see, easier to report on, and easier to reuse than the original message.
Once that happens, teams often stop managing the business fact itself and start managing the system’s version of the fact. That shift is subtle. Nobody announces it. Nobody says, “We are now accepting divergence between the source and the record.” The drift becomes normal because the application is where the work gets done.
I have seen this create a strange kind of false confidence. The record looks structured, so people assume it is reliable. The field is populated, the workflow moved forward, and the report totals correctly. Yet none of that proves the stored value still matches what the customer, vendor, or partner originally sent. Structure can improve usability without improving truth.
That is why this issue deserves more attention from operations leaders and application owners. Gartner says poor data quality costs organizations an average of at least $12.9 million per year. You do not reach numbers like that through dramatic failures alone. You reach them through thousands of ordinary moments where a business system carries values that are trusted, reused, and acted on despite small defects in accuracy or consistency.
And once drift enters a system of record, the cleanup gets harder. The wrong value can trigger downstream actions, appear in exports, sync into adjacent platforms, and show up in reports used for planning. At that point, the question is no longer whether someone copied one field cleanly. The question is how many decisions now depend on the altered version.
So when I look at email-driven workflows, I do not only ask whether staff are spending too much effort moving data around. I ask a more important question: after the data is moved, which version does the organization actually believe? If the answer is “whatever ended up in the system,” then even a minor mismatch can become normalized operational truth.
The practical insight is simple. A copied value becomes far more dangerous after it is saved than while it is being typed. Before save, it is a human action. After save, it becomes institutional memory.
That shift should change how you review risk in inbox-to-system workflows. I would start with three quick checks:
Which fields arriving by email later drive customer commitments, money movement, fulfillment, or compliance activity?
Which of those fields are trusted from the destination system without a routine look back to the source message?
Where would a mismatch create silent operational spread through reports, integrations, or downstream teams?
If you find those conditions, you are looking at drift risk, not just admin friction. That matters because the right response is different. The goal is not only to help people work faster. The goal is to keep the accepted system view anchored to the original business fact.
That is the lens I want readers to carry forward: when a system becomes easier to trust than the source that fed it, the business can end up running on a polished version of the wrong answer.
When the same fact gets processed twice, cost is only the first symptom
Inbox-to-system work often looks like a small labor line item, but the visible entry step is usually only the beginning. When the same business fact must later be checked, corrected, explained, or reconciled, the organization pays for handling it again and again. (What Is Dirty Data? - IBM)
Double-handling waste becomes expensive because effort does not end with data entry. It spreads into follow-up tasks such as checking the original message, comparing values across systems, resolving which version is current, updating downstream records, and handling the operational fallout from mismatches. IBM notes that poor data quality leads to time-consuming cleaning, correction, and reconciliation, which closely matches the rework pattern created when a fact is first handled in email and then recreated in another system. IBM also reports, citing Forrester, that more than a quarter of organizations estimate annual losses above $5 million from poor data quality, showing that downstream quality issues can create material financial impact at scale.
A useful next step is to stop measuring this workflow only as entry labor and start measuring total handling effort per fact. Ask how often one incoming email fact triggers later review, clarification, or correction, which teams touch it after first entry, and where time is spent reconciling versions before work can continue. That simple shift helps expose hidden rework and highlights where a cleaner source-to-system path could reduce both cost and delay.
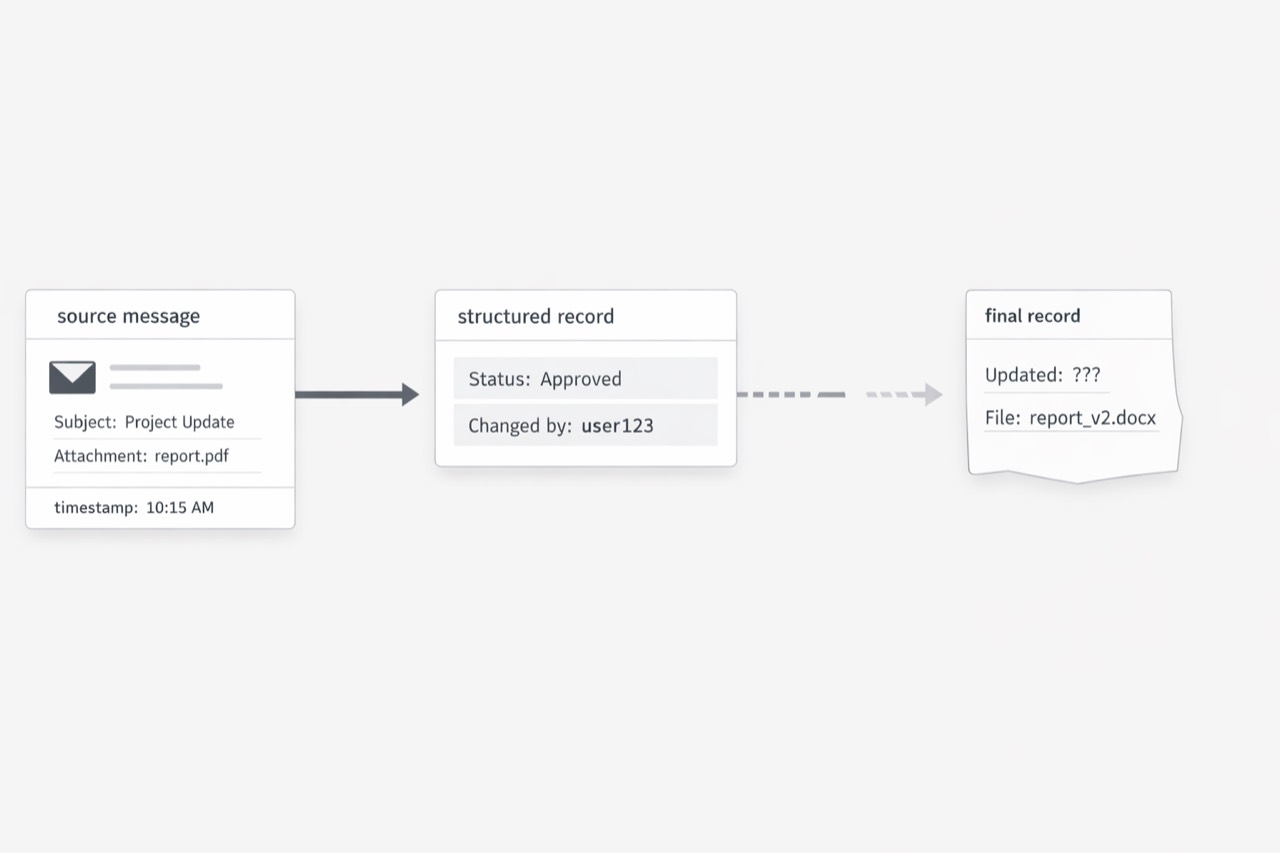
Trust falls apart when nobody can cleanly trace system data back to the message that started it
I have seen teams stay confident in a system record right up to the moment someone asks a simple question: where did this value come from? When that answer takes five inbox searches, two screenshots, and a Slack thread with three people, trust drops fast. The issue is bigger than inconvenience. It means the business cannot show a clean path from the inbound message to the stored record and the actions that followed. (FDA Guidance for Industry: Data Integrity and Compliance With Drug CGMP)
Key term: Audit trail dilution is the weakening of trust that happens when system data cannot be clearly traced back to the original message and the handling steps after it arrived.
You might be wondering: does this only matter in highly regulated settings? I do not think so. Regulated industries make the principle easy to see, because they are forced to define what trustworthy data looks like. FDA guidance describes core data integrity attributes through ALCOA, including attributable, original, accurate, contemporaneous, and legible. Those ideas apply well beyond life sciences. If a business record cannot be tied to who entered it, when they entered it, what source they used, and whether the stored value still reflects the original message, confidence in that record gets thinner every time someone touches it.
This is where inbox-driven operations start to create a quiet control problem. The email exists. The destination record exists. But the link between them is weak, partial, or informal. Maybe the employee copied the value correctly. Maybe they changed the wording to fit a field. Maybe they used the latest reply in a thread. Maybe they updated the record after a phone call and never noted it. Each step may feel reasonable in the moment. Over time, though, the organization loses a reliable way to reconstruct what happened.
FDA guidance uses a strong definition here: an audit trail is a secure, computer-generated, time-stamped record that allows reconstruction of events. I like that definition because it gets to the heart of the issue. Trust does not come from a team’s good intentions. Trust comes from being able to reconstruct the sequence cleanly. When a key field in ERP or CRM started as an email, then passed through a person, then changed again during follow-up, the business needs more than a saved final value. It needs a dependable chain that explains the value.
Without that chain, routine work becomes harder to defend. A billing amount may be right, but proving why it is right takes too long. A customer term may be current, but nobody can show which message authorized the update. An operations team may believe a service request was handled properly, yet the record does not clearly show when the request arrived, who interpreted it, or how the final fields were decided.
That is why I see audit trail dilution as an operational trust issue. The damage appears during exception handling. It shows up in escalations, disputes, internal reviews, and handoffs between teams. The system still contains data, but the confidence around that data is weaker because the path back to source is blurred. Once that happens, people compensate in expensive ways. They re-check inboxes, ask coworkers for context, keep side notes, and hesitate before acting on records that should have been straightforward.
In other words, the system may still look complete while its credibility is getting lighter. That is a dangerous state for operations leaders, because the gap often stays invisible until someone needs evidence, not just access.
The practical takeaway is simple: if you want people to trust system data, make traceability easy at the moment of capture, not during the later investigation. I would start with a short review of one email-driven workflow and ask three questions.
Can a user open the system record and quickly identify the exact message that supplied the business fact?
Can the team see who created or changed the value and when that happened?
Can a reviewer reconstruct the handling path without depending on memory, screenshots, or separate notes?
If the answer is no, trust is already eroding, even if the workflow still appears to run fine. That is the key insight I want this section to land: operational confidence depends on more than getting data into a system. It depends on preserving a clean line from the original message to the final record, with enough history to explain how the business got there.
That is what audit trail dilution really costs. It turns ordinary records into claims that are hard to prove.
Once you look at inbox copy-paste through a data quality lens, the pattern becomes hard to ignore. Re-keyed data failure introduces avoidable risk at the point of transfer. System-of-record drift turns small inconsistencies into accepted truth. Double-handling waste expands cost well beyond the original entry step. Audit trail dilution weakens confidence when teams need to explain what happened and why.
Taken together, these are not isolated admin annoyances. They are signs that an important part of the business data path still depends on people recreating facts that already exist. That should matter to anyone responsible for operations performance, system reliability, or trust in business records.
The practical shift is simple: stop treating email-to-system transfer as invisible glue work. Treat it as a place where data can change, spread, and lose credibility. Once you do that, you can start reviewing these workflows with the right questions: which facts are being recreated by hand, which saved values become trusted immediately, where rework accumulates later, and how cleanly each stored record can be tied back to its original message.
That is where problem recognition starts. What looks like copy-paste work is often a hidden data quality layer sitting in front of your most important systems.