Most organizations already know email matters. What they often lack is a clean architectural way to think about what happens after a message arrives and before an application can safely use it. In that gap, teams usually improvise. One group writes mailbox rules. Another adds a parser behind a webhook. A third pushes email into a workflow tool and hopes the edge cases stay manageable.
That pattern works just well enough to spread, but not well enough to scale cleanly. Over time, business-critical communication starts flowing through fragmented intake logic that nobody would accept in other input surfaces. We would not treat APIs, event streams, or file ingestion this casually. Yet many teams still treat inbound email as a side path rather than as a governed entry point into the stack.
This post argues for a better mental model: the email ingestion layer. I use that term to describe a dedicated system that receives email, normalizes it, applies logic, and hands off structured output to downstream applications. For technical executives shaping architecture direction, the value is not just cleaner implementation. It is clearer ownership, more reviewable boundaries, and a more useful category for operational email than ad hoc scripts on one end or generic automation on the other.
Why inboxes need a real system behind them
Many teams still treat the inbox like a side door: one script here, one webhook there, and soon fragile rules sit behind business-critical communication. Email remains a major business input and total email volume continues to grow, so this flow deserves the same architectural attention as APIs and event streams. (Email Market, 2024-2028 Executive Summary)
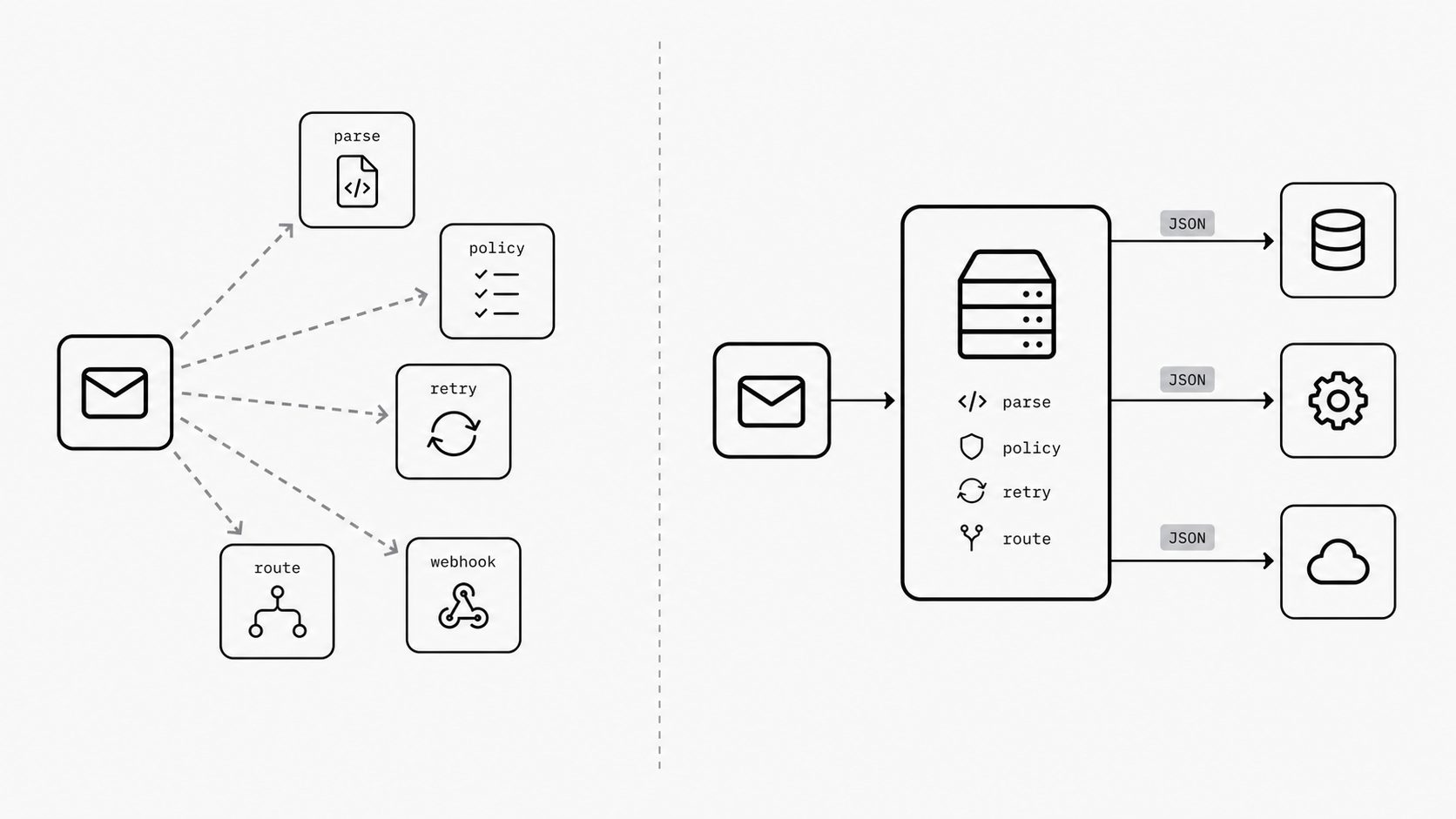
This keeps happening because email usually enters the stack through mailbox scripts or generic automation tools. Those options can help at the start, but they do not create a clean operational boundary for how email becomes application data. Modern inbound email products already show part of the pattern: they receive a message and send its contents to an application endpoint, often through an email webhook. A real email ingestion layer goes further by centralizing validation, extraction, normalization, routing, retries, and policy checks before downstream systems consume the result. Without that boundary, teams duplicate parsing logic, error handling, and review processes in inconsistent ways. (Understanding Inbound Email in Postmark)
The practical payoff is control. A dedicated email ingestion layer gives the organization one place to turn inbound messages into trusted records, events, or workflow triggers, making governance and scaling easier across use cases. It also gives leaders a clearer architectural category: instead of debating ad hoc scripts, they can define a system that owns conversion of email into reliable application input.
The handoff matters more than most teams think
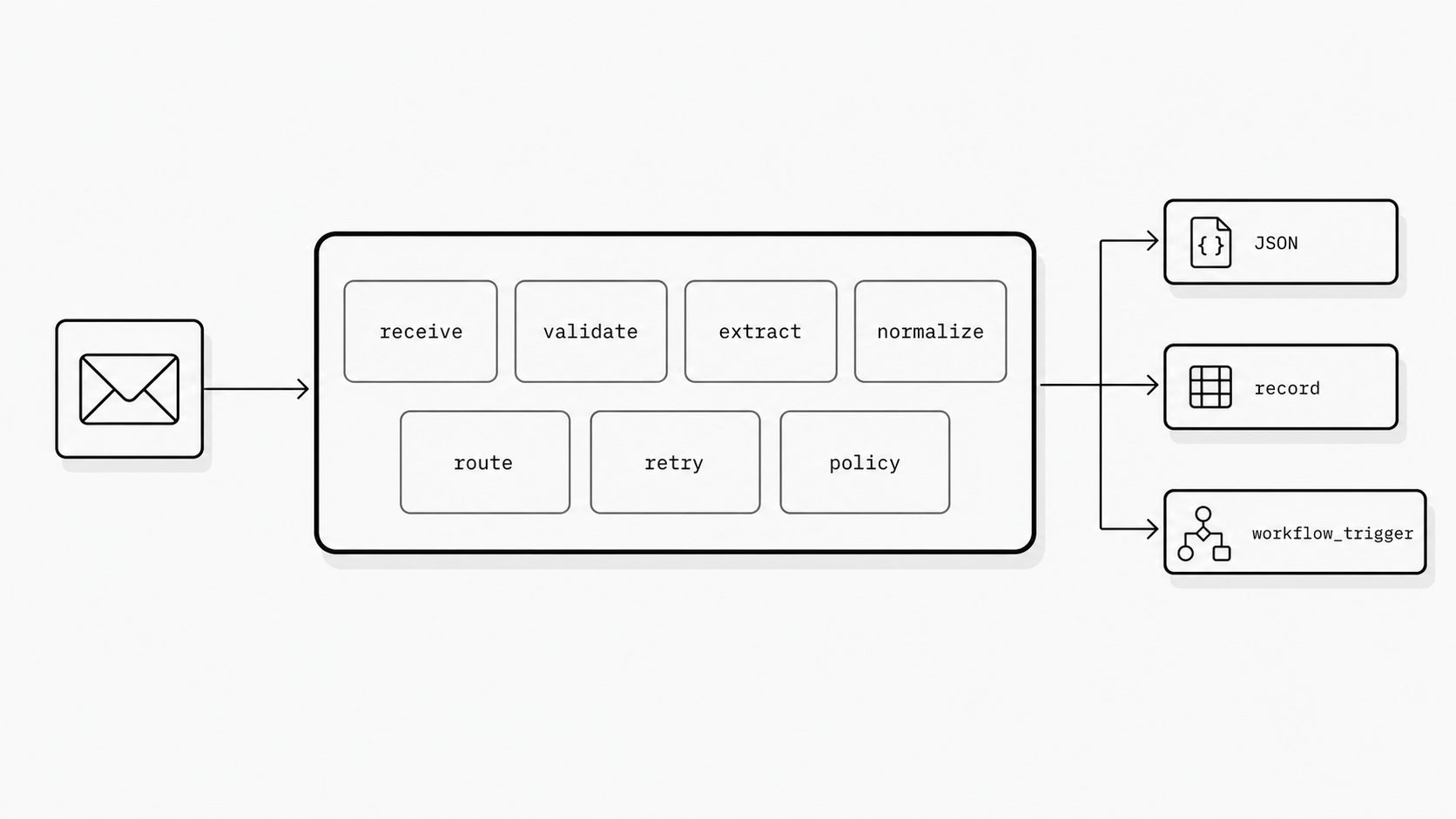
Teams often spend months tuning mailbox rules, extraction logic, and downstream workflows while barely naming the moment that shapes the whole system: the handoff from email into software. That is usually where reliability starts to drift. Once a message crosses into an app, differences in field names, attachment handling, headers, and retry behavior can create operational variation across teams. Modern inbound email parsing tools already expose sender and recipient data, headers, attachments, text and HTML bodies, and other structured fields that can be posted to an endpoint for application use. (Postmark Inbound Webhook)
This is why boundary standardization deserves more attention from technical executives. The question is not whether teams can parse incoming email. The market already provides an inbound parse webhook model where a provider receives the message and delivers a structured payload to an application endpoint. The real architectural question is whether every product team should define that payload differently. (Understanding Inbound Parse Webhook Retry Logic)
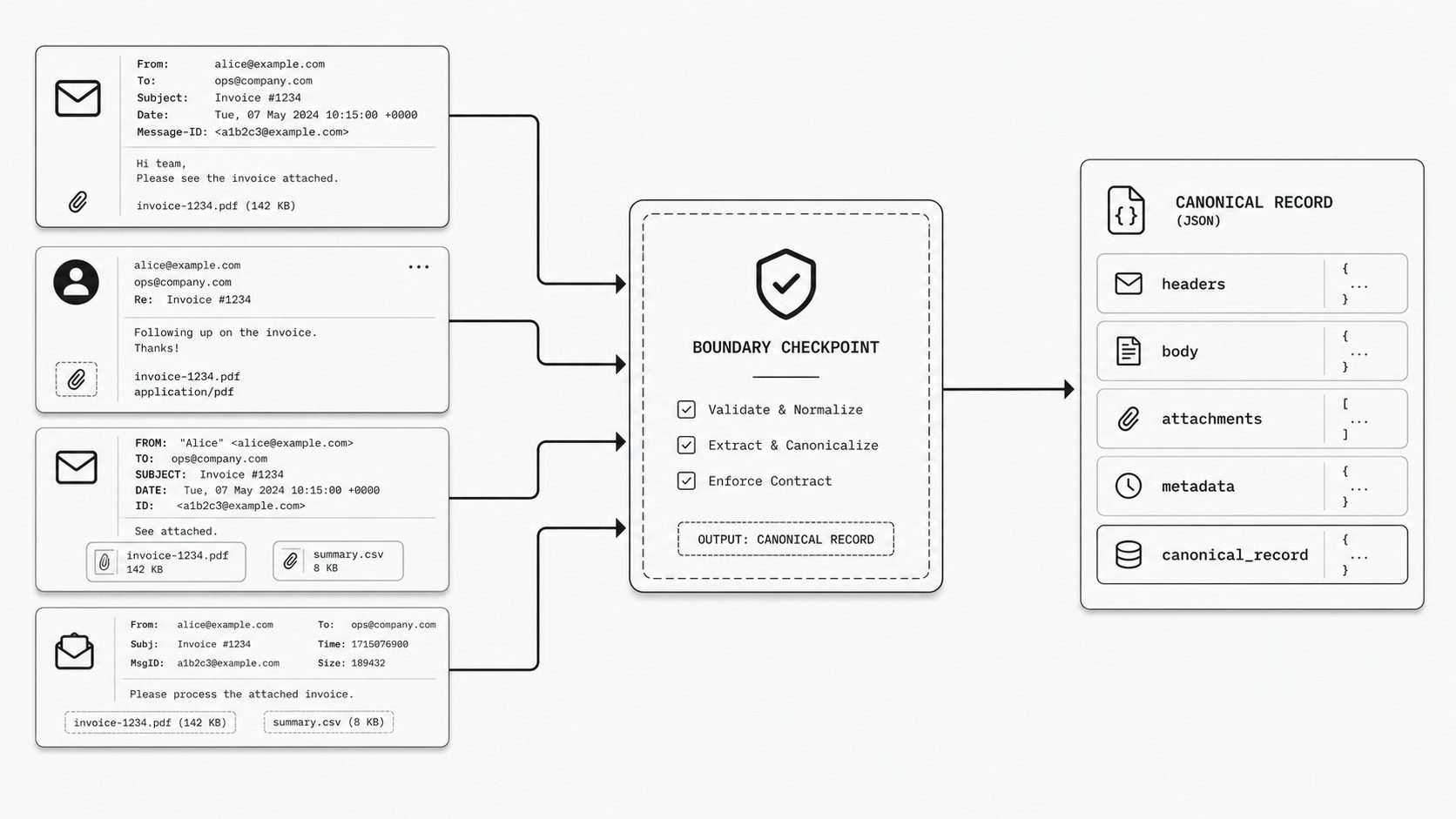
In practice, many do. One team keeps the original header block and stores attachments separately. Another extracts a few fields and drops the rest. A third maps everything into its own naming scheme because that is what the first release needed. Each choice can feel reasonable in isolation. Across a portfolio, it creates a messy edge that slows reviews and makes incident response harder because teams must interpret multiple patterns for the same business input.
The email-to-application boundary is one of the few places where standardization is both practical and visible. The payloads are inspectable, the parsed fields are known, the transformation steps can be logged, and the output can be made consistent enough for review without forcing every application to work the same way internally.
A fast takeaway is to define one canonical inbound email record for all teams: what arrived, what metadata was captured, what content was extracted, and what delivery or retry context applied. Because inbound parse webhooks already produce structured payloads, this standard can be implemented quickly at the boundary instead of rebuilt inside every application. The result is a more reviewable operating surface and fewer downstream integration debates.
Why central control lowers risk without slowing teams down
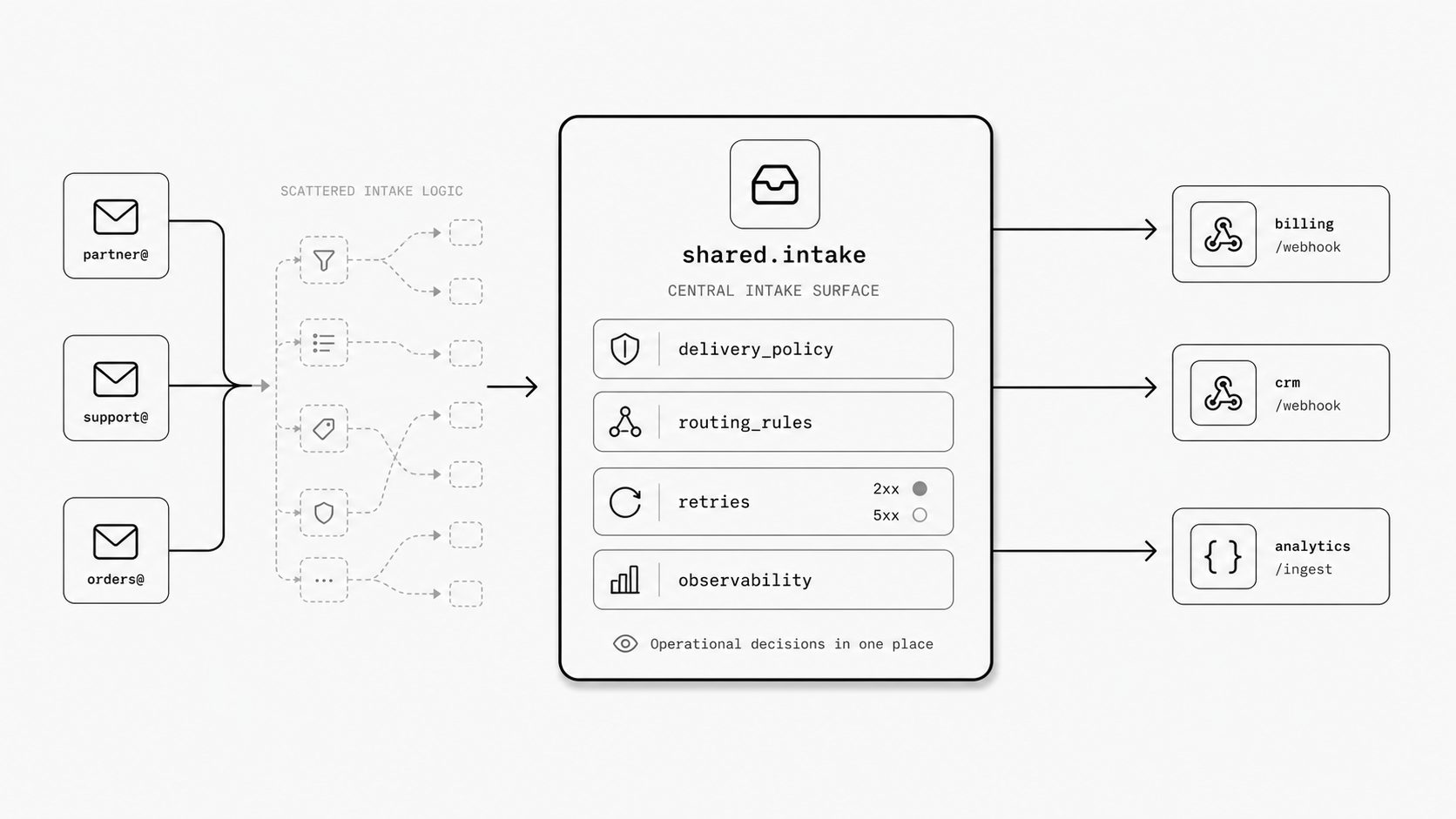
I have seen this movie before: a team ships fast with one mailbox rule, one parser, and one small endpoint, then six months later nobody can clearly answer who owns delivery policy, retry behavior, or routing decisions for a business-critical message flow. Inbound email systems already let messages be matched by rules and then pushed onward through an email webhook, another email address, or temporary storage for later retrieval. Once those choices spread across teams, the organization starts carrying operational risk in many small places instead of one visible one. (Understanding Inbound Parse Webhook Retry Logic)
You might be wondering whether central control means every team has to wait in line. In practice, teams often slow down more when each group has to rediscover intake mechanics on its own, including which response codes signal success or failure and how retry behavior works. SendGrid states that inbound parse delivery depends on the HTTP status code your server returns: a 2xx response marks success, 5xx responses trigger retries for up to 72 hours, and 4xx, 3xx, or DNS errors cause the payload to be dropped immediately. It also notes that the sender will not receive a bounce if your server fails and that you must monitor your own logs for failed POSTs. Mailgun likewise documents that incoming mail can be evaluated against route expressions, handled by priority, and then sent to an application over HTTP, forwarded elsewhere, or stored temporarily for retrieval. Those capabilities are useful, but they also show why central ownership matters: when routing logic, priority rules, and delivery actions are scattered, review and incident response become harder because behavior must be reconstructed one team at a time. (Mailgun Routes API Reference)
The practical win is simple: central control reduces risk by making email intake behavior explicit. A shared intake layer can own delivery standards, retry expectations, route review, logging, and failure visibility, while product teams stay focused on business logic. For leaders shaping architecture direction, that means fewer hidden failure paths and a cleaner way to process inbound email programmatically without creating unnecessary bottlenecks.
Why I frame this as infrastructure for operational email
When I talk with technical executives about inbound email, I rarely see a tooling gap first. I see a language gap. The market already shows the mechanics for receiving messages, extracting data, and sending that payload into software, often through an email webhook. Yet the way these products are usually described keeps the conversation at the feature level - routing, parsing, forwarding, posting - instead of at the operating model level. That matters because the words we use shape the budget, ownership, and review model around the system. (Mailgun Glossary: Inbound Processing)
This is why I frame the problem as infrastructure for operational email. I am trying to give leaders a more useful mental model for a pattern that already exists in pieces across vendor products and internal systems. Mailgun describes inbound processing in terms of parsing incoming messages and routing data into applications. Its inbound routing material also emphasizes configurable routes and delivery actions that move email onward based on rules. Those are real capabilities, and they are valuable. What they do not provide by themselves is a shared category that tells an architecture team how to think about the whole boundary. (Mailgun Inbound Email Routing)
You might be wondering: why does naming matter so much if the features already work? Because feature language encourages local buying decisions. Infrastructure language encourages system design. When a capability is framed as a handy developer feature, teams tend to evaluate it one workflow at a time. When it is framed as infrastructure for operational email, leaders start asking bigger questions: Who owns policy? What is the standard payload? How do we review transformations? Where do we observe failures? Which use cases belong on the same surface? That shift in framing helps executives see that processing inbound email programmatically is not just an implementation detail for one team. It is a repeatable enterprise pattern that deserves a defined place in the stack.
I also think this framing is timely. Many organizations now sit between two weak labels. On one side, they have scripts and mailbox rules that feel too small for the risk involved. On the other, they have broad automation language that feels too generic for the operational details of message intake. Vendor materials confirm that the mechanics for email-to-webhook flows are already established. The open space is conceptual: a clearer category that connects those mechanics to architecture, governance, and scale.
The reward of this framing is simple: it gives technical executives a better way to steer decisions. Instead of debating separate parsing features every time a new use case appears, they can treat operational email as infrastructure with standards, ownership, and review built in. That creates a cleaner strategic conversation for email automation for developers as well. The goal stops being to wire up one more mailbox flow. The goal becomes to establish a durable platform pattern for turning inbound messages into trusted application inputs.
The case for an email ingestion layer is really a case for taking inbound email seriously as an architectural boundary. The mechanics already exist in vendor products and internal tooling: receive the message, parse it, extract fields, route it onward. What is usually missing is the system-level decision to make that boundary consistent, visible, and owned.
Once you name the pattern, better decisions follow. You can standardize the handoff from email into application data. You can concentrate delivery policy, retries, routing logic, and failure visibility in one place. And you can frame operational email as infrastructure rather than as a collection of tactical mailbox workflows.
That shift matters right now because teams need a clearer option between brittle scripts and overly broad automation narratives. An email ingestion layer provides that option. It gives technical leaders a practical model for turning messages into trusted inputs at scale, with the governance and control that business-critical communication deserves.