Email automation starts out sounding simple. A message arrives, a webhook fires, a workflow runs, and the business moves faster. But once email is tied to tickets, billing, account changes, customer notifications, or internal approvals, delivery behavior stops being a background implementation detail. It becomes part of the business contract.
That is why retries and repeated deliveries matter so much. In distributed systems, retries are normal. Timeouts, dropped acknowledgments, and partial failures are normal too. What breaks trust is not that these conditions exist. What breaks trust is when one inbound email can produce two actions, or when the same delivery attempt leads to different visible outcomes depending on timing.
In this post, I focus on the business and technical damage that appears when email-driven automation cannot safely handle repeated delivery. The core issue is straightforward: if a system cannot recognize repeated intent, preserve the first accepted result, and protect downstream mutations from replay, stakeholders stop trusting the automation even if the pipeline looks healthy on paper. For backend engineers and technical approvers, that makes reliability less about successful receipt and more about consistent outcomes under retry.
One email, two actions - and suddenly everyone has a trust problem
I have seen this problem start with a very ordinary email webhook. A customer sends one message. The system accepts it, starts work, and then something small goes wrong on the way back - a timeout, a dropped connection, a slow acknowledgment. The sender sees one email. My systems may see that same event again. In distributed systems, retries are normal because transient failures are normal. That means an inbound email flow can quietly turn one message into two actions unless I design for that from the beginning. And when one email creates two tickets, two credits, or two customer updates, the issue stops looking like plumbing. It becomes a trust problem for engineering, operations, finance, and the people who approved the automation in the first place. (AWS Builders’ Library - Making retries safe with idempotent APIs)
You might be wondering: why does this catch teams off guard? Because the visible event is the email, while the risky part is the delivery path around it. Inbound email parsing often makes the first step feel clean and deterministic. The message arrives, fields are extracted, payload is shaped, and the downstream workflow starts. That neat flow hides a harder truth: delivery and acknowledgment do not happen in a perfect line every time. If the receiving service finishes the business action but the response never gets back cleanly, the sender may try again. From the platform side, that can be a responsible recovery step. From the business side, it can look like the system changed its mind and acted twice.
That is why I treat duplicate-event exposure as an executive-level reliability concern, not a narrow implementation detail. The cost is rarely limited to extra compute. It shows up as duplicate records, repeated notifications, multiple case opens, conflicting status changes, and manual cleanup across teams. Even worse, the damage is uneven. Some downstream actions are harmless if repeated. Others create financial, legal, or customer experience issues that take much longer to unwind than the original workflow took to run. When approvers realize the same email can produce inconsistent business results depending on network timing, confidence drops fast. (Postmark Blog - Why idempotency is important)
The practical signal here is simple. If my system receives an inbound email webhook, I should assume the same event may be delivered more than once and design my consumer to recognize that fact using stable identifiers or another durable deduplication approach. This is not a fringe edge case. It is the operating reality of distributed delivery. Teams that ignore it usually discover the issue through support tickets, audit questions, or an uncomfortable meeting where everyone agrees the automation worked exactly as built and still failed the business.
The insight I want technical approvers to hold onto is this: trust in email-driven automation is shaped less by whether a message arrives and more by whether the same message always leads to the same business result. When I explain duplicate-event exposure in those terms, the priority becomes obvious. This is about protecting outcome consistency. A reliable mail webhook is one that can survive retries without changing the business story told by the original email. Once a team sees that clearly, architecture discussions get better fast. Instead of asking, “Did we receive the message?” we start asking the question that actually preserves trust: “If this shows up again, what exactly happens?”
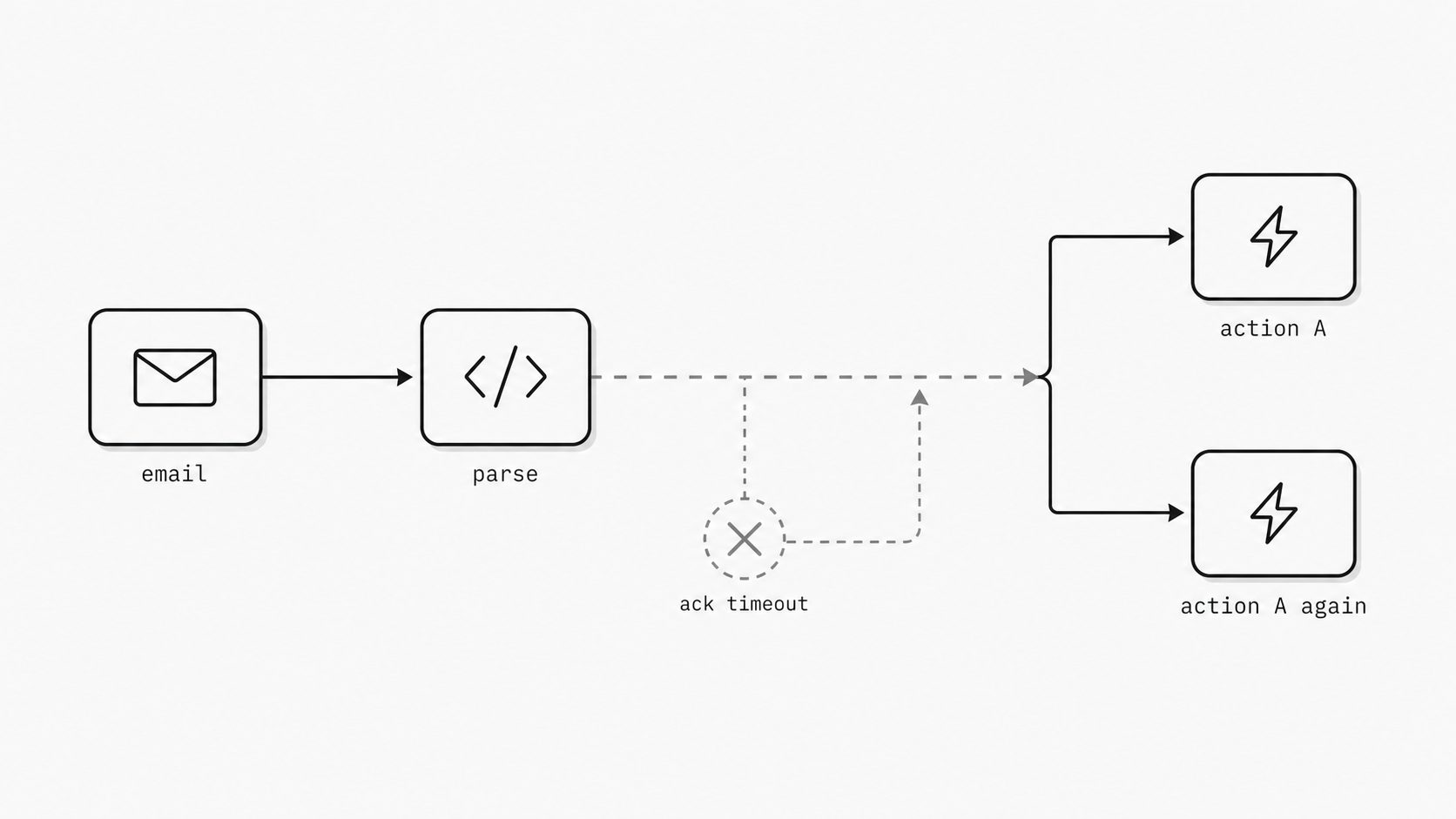
So what exactly should happen when delivery half-succeeds?
I have learned that the most dangerous moment in an email-driven workflow is not the obvious outage. It is the gray zone right after partial success. The message was received. Some work may have finished. The acknowledgment may have timed out. Now the sender has to guess whether to try again, and my system has to guess what that second attempt means. That is the retry semantics gap. In practice, this is where a clean automation story turns into a boardroom question: did the system fail, or did the contract fail? AWS guidance is direct on the underlying pattern: mutating operations should be designed to be idempotent so retries do not create unintended changes. If I cannot explain, in plain language, what happens after a half-success, then I do not have a reliable workflow. I have a hopeful one. (AWS Well-Architected Framework - REL04-BP04)
You might be wondering: isn’t retrying a good thing? Yes. Retrying is often the right recovery behavior in distributed systems because transient faults are normal. The issue is not the retry itself. The issue is the missing contract around it. When an inbound email starts a downstream action, I need a reviewable answer to a few simple questions. If the first attempt created a ticket and the response got lost, should the second attempt return the original ticket ID? If the first attempt sent data to billing and then timed out, should the next attempt resume, reject, or confirm the existing result? If operations reviews the logs a week later, can they trace both attempts back to one business intent using a stable request identifier?
That last point matters more than many teams expect. AWS Builders’ Library highlights caller-provided request identifiers as a core way to make retries safe and understandable because the service can recognize repeated intent rather than treating each arrival as brand new work. That creates something technical approvers care about immediately: auditability. I can explain what happened. I can prove why it happened. I can show that a second delivery was interpreted as the same operation, not a second business instruction.
This is also where conversations about webhook retry exponential backoff often go off track. Backoff helps reduce pressure during failures, and automatic webhook retry can improve eventual delivery, yet neither one answers the real business question on its own. A retry policy tells me when the sender will try again. It does not tell me what outcome the receiver should preserve when part of the work already happened. That difference is easy to miss in architecture reviews because timing diagrams look neat while production failures do not.
When I review a reliable webhook delivery design, I look for an explicit operational contract with three parts. First, a stable identity for the business request so repeated attempts can be matched. Second, a durable record of the first accepted outcome so the system can return the same answer on later attempts when appropriate. Third, a clear policy for incomplete work so humans know whether the system will resume, reconcile, or escalate. Without those three parts, teams usually end up with hidden branch logic, support playbooks, and long meetings where everyone uses the word “edge case” to describe a recurring production condition.
The payoff is simple. Once I define retry semantics as a business contract, not just a transport behavior, reliability decisions get much sharper. I stop asking whether the sender will retry and start asking what result must remain true when it does. That shift protects more than uptime. It protects approvals, audits, customer communication, and internal confidence because the workflow has one explainable story even when delivery gets messy. If a team wants trust from email-driven automation, this is the standard I use: after partial success, the next attempt should follow a rule I can document, test, and defend in front of both engineers and executives.
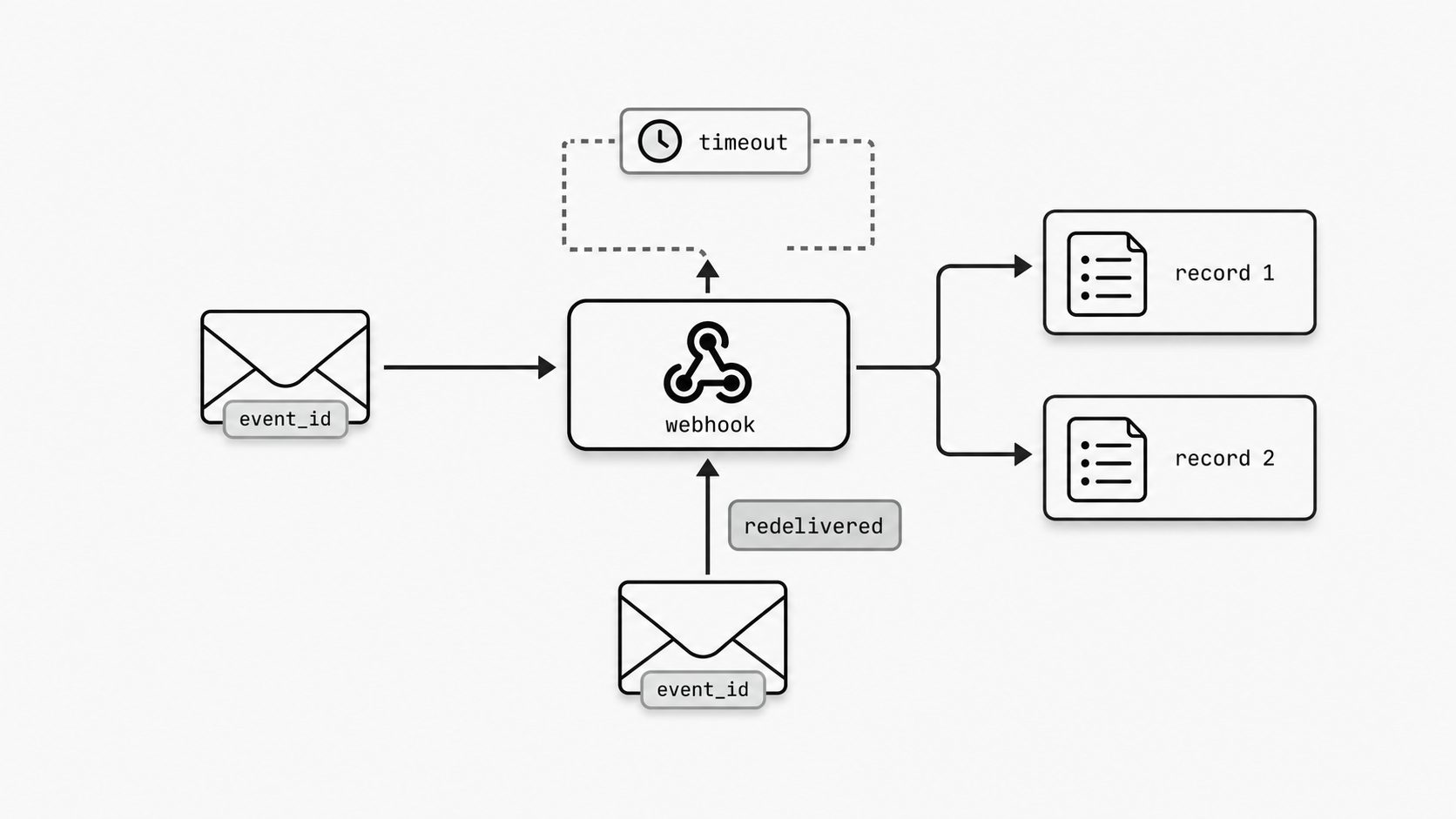
If the action is unsafe on replay, the workflow is unsafe in production
Teams often feel confident once they add retries to an email flow, but production reveals the real test: a replayed message can trigger a second refund, reopen a closed case, send another customer notice, or write a conflicting record if the business mutation is not protected. If the same request returns after a timeout or disconnect, the workflow is only safe when it preserves the first accepted result instead of mutating the business again. (Stripe API Docs - Idempotent requests)
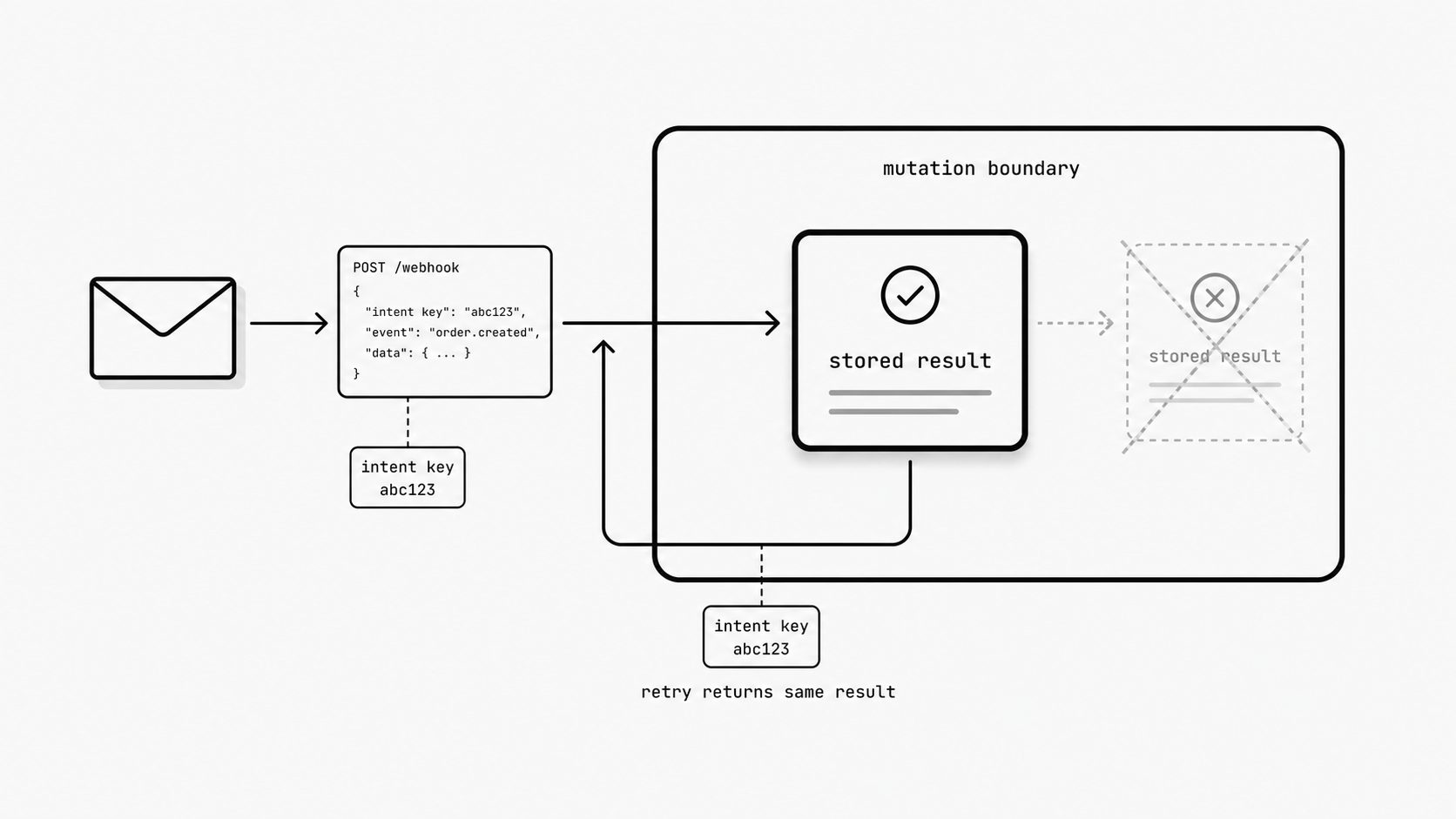
Safety lives at the point where an inbound event becomes a business mutation, not merely in the transport layer. Retries, queues, and webhook backoff improve delivery reliability, but they do not by themselves guarantee a safe outcome for mutating operations. AWS notes that identical request parameters are not always enough to determine whether two requests reflect the same customer intent, so systems need a stronger way to recognize replayed intent before repeating an action. That matters in email-driven automation because the same message body or extracted fields can appear again during a retry. Stripe offers a practical pattern: it stores the first result associated with an idempotency key and returns that same result for later retries using the same key. The broader lesson is to preserve outcome continuity at the operation boundary so one inbound message identity maps to one accepted business result.
Use a simple review test: identify where the business mutation starts, what identifier expresses the original intent, where the first accepted result is stored, and how retried requests are forced back onto that same recorded result path. This shifts the conversation from replay-safe delivery to replay-safe outcomes, which is what actually protects customer trust and operational stability. If one replay can create a new side effect, the workflow is still carrying avoidable production risk.
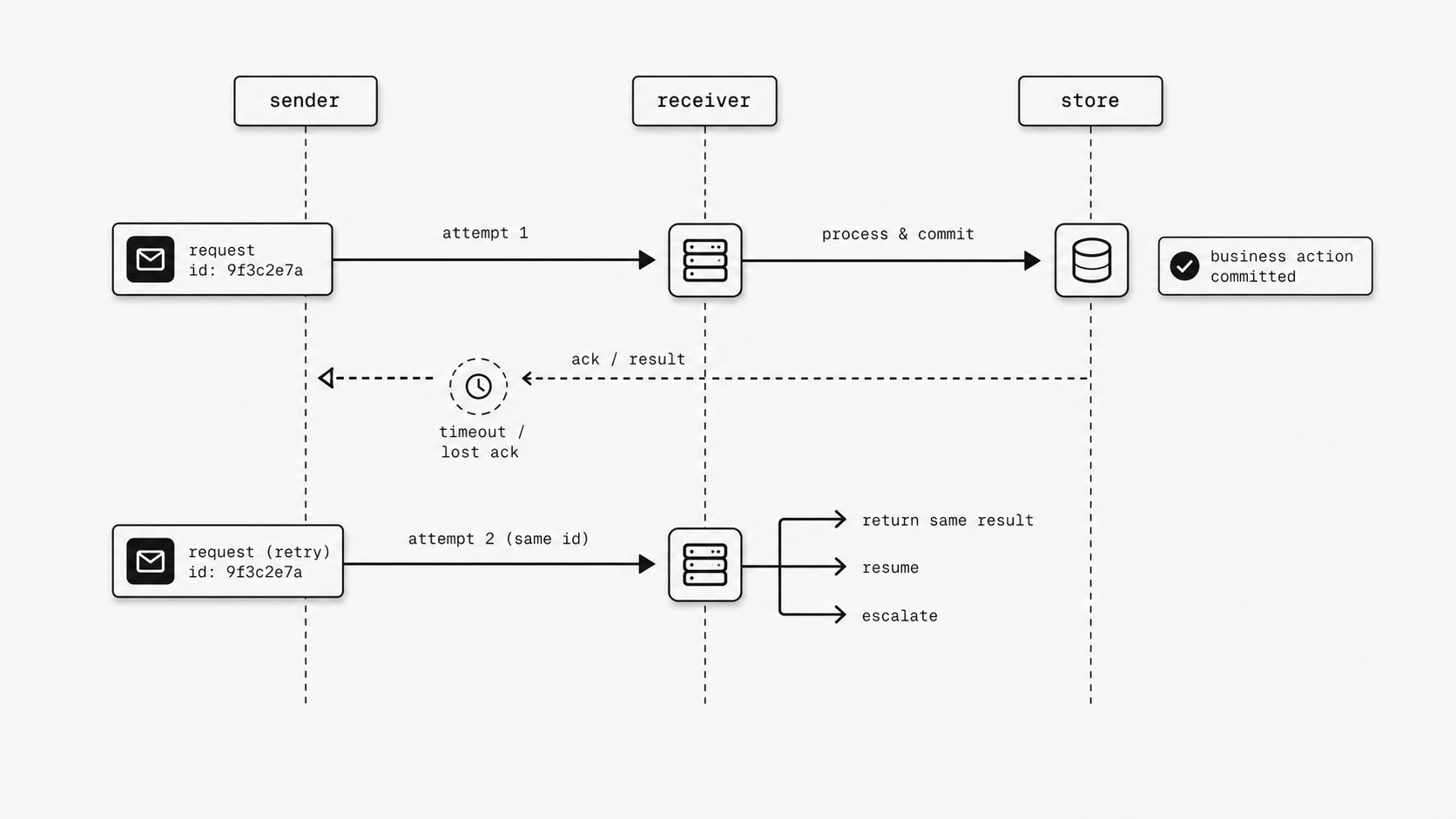
The real failure is not the retry - it is the loss of confidence after the result changes
I have seen teams stay calm during a retry and then lose confidence one minute later when the outcome changes. The email webhook arrives, the workflow starts, and a temporary failure triggers another delivery attempt. That part is normal in distributed systems. The trust break happens when the second pass does not confirm the first result and instead creates a new business story - a second case, a changed status, a repeated charge, or a fresh notification to the customer. At that point, the technical event is small, but the organizational signal is loud: the system cannot prove that one business intent leads to one stable outcome. (AWS Lambda Developer Guide - Idempotency)
You might be wondering: why does this hit confidence so hard? Because most stakeholders do not judge automation by transport logic. They judge it by whether the result is consistent. AWS guidance on idempotency centers on exactly that idea. Services should let callers retry safely, and idempotent handling exists to avoid creating unexpected outcomes from those retries. AWS Lambda documentation is similarly direct that duplicate invocations can happen and that idempotency logic is what makes those retries safe.
That is why I do not treat an inconsistent retry result as a narrow engineering bug. I treat it as a credibility event. Engineering starts asking whether the inbound email webhook can be trusted under pressure. Support starts building manual checks because they no longer believe the first visible outcome is the final one. Technical approvers start questioning the whole business case, because reliable webhook delivery is supposed to reduce operational friction, not create a second review loop around every important action.
This is also where teams can get distracted by infrastructure language. A webhook retry exponential backoff policy may be perfectly reasonable, and an automatic webhook retry path may improve eventual delivery. Yet confidence does not come from the retry policy by itself. Confidence comes from proving that the replay returns the same accepted result, or at least follows one documented rule every time. If that proof is missing, people compensate with human controls. They recheck queues. They compare logs. They ask finance or support to confirm whether the first action already happened. In other words, the organization rebuilds trust manually because the system did not preserve it automatically.
For an email to webhook architecture, this is the point I want leaders to see clearly: outcome consistency is part of the product, not an internal implementation detail. If the same inbound message can lead to different visible results depending on timing, the platform teaches everyone around it to doubt automation at the exact moment it should be earning more responsibility.
The practical insight is simple. A retry does not damage trust on its own. Trust erodes when the system cannot return, recognize, or defend the original result after the retry arrives. That gives me a much better review question for any mail webhook or email webhook flow: if this same message is delivered again after a partial failure, will every stakeholder see the same business answer? When I can answer yes, approval gets easier, support effort drops, and the automation earns room to handle more serious workflows. When I cannot, the real risk is bigger than an extra invocation. It is the slow loss of confidence that turns a technically working system into one the business hesitates to use.
The pattern across all of this is simple: trust in email webhooks is not earned by receiving the message once. It is earned by making sure the same message cannot quietly rewrite the business result when delivery gets messy.
That means treating repeated delivery as expected, defining what should happen after partial success, protecting every downstream mutation from replay, and judging the system by whether it preserves one stable answer for one business intent. When those rules are explicit, retries remain a recovery tool. When they are missing, retries become a source of confusion, cleanup, and organizational doubt.
For teams putting email into production flows, this is the real reliability bar. If the same inbound message shows up again tomorrow, next week, or during an outage, the workflow should still tell the same business story. That is what keeps approvals intact, operations calm, and automation worthy of more responsibility.