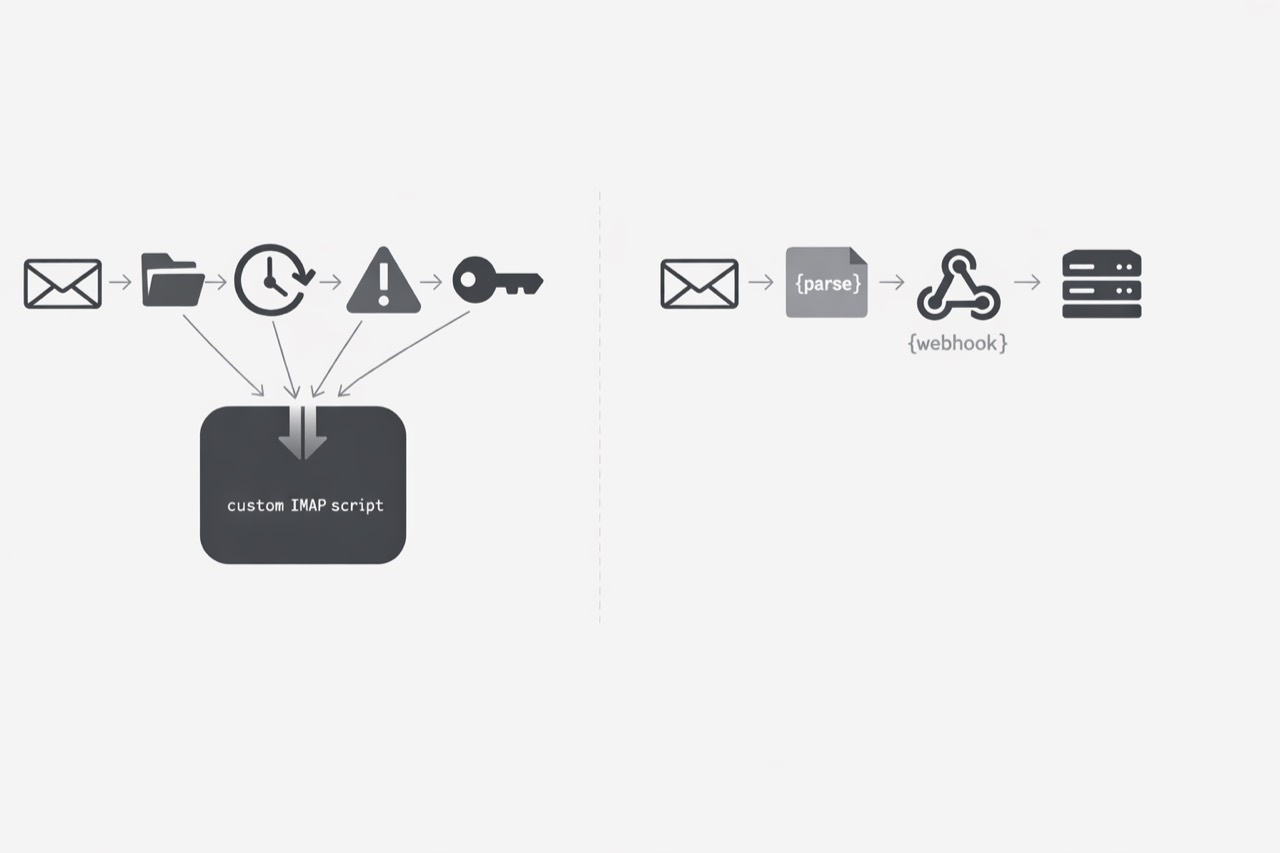
Some infrastructure problems do not arrive looking important. They start as a small script written to read a shared inbox, move a few messages, and unblock a workflow. At launch, that kind of integration feels practical. It is fast to build, easy to explain, and usually much cheaper than designing a broader ingestion model.
But this is exactly the kind of engineering shortcut that can age into permanent drag. The mailbox script keeps running, so it looks finished from a distance. Meanwhile, it quietly absorbs retries, auth changes, folder assumptions, deduplication rules, and provider-specific exceptions. What began as a utility becomes production infrastructure without ever being treated like it.
That shift matters for backend and platform engineers because the real cost is rarely the first implementation. The cost shows up later in maintenance, ownership concentration, and recovery logic wrapped around a stateful protocol that keeps interacting with systems outside your control. In this post, I move from the operational pain of mailbox polling into the engineering pain underneath it: why custom IMAP integrations age badly, why they become long-term liabilities, and why an event-first model is often the cleaner path once the script stops being truly small.
The script was small. The maintenance surface never stayed small
I have seen this movie more than once. A team needs to pull messages from a shared inbox, so someone writes a small IMAP script on a Friday afternoon. It logs in, checks one folder, grabs unread mail, and moves on. In that moment, it feels contained. The job is tiny, the code is short, and the business gets its integration fast. The problem is that IMAP was never a tiny surface area to begin with. It is a stateful protocol with mailbox selection, message flags, searches, server capabilities, and client behavior that all have to stay in sync over time. What looked like a quick utility starts carrying assumptions about folder layout, message state, authentication, and server responses. Those assumptions age even when the script itself barely changes. (RFC 3501 - Internet Message Access Protocol - Version 4rev1)
That is where the pain shifts from operations into engineering. The script still runs, so on paper it looks done. In practice, it becomes a living compatibility layer. Every mailbox has state. Every message can carry flags. Every server advertises capabilities a client may need to interpret correctly. Searches, selections, and updates happen inside that protocol model, which means a reader has to behave like a careful client, not a one-time file download tool.
You might be wondering: why does this get worse with age? Because the environment around the script keeps moving. Security expectations move. Protocol revisions move. Provider defaults move. The base IMAP specification did not freeze the world forever, and the standard itself later advanced to IMAP4rev2, which is a good reminder that a mailbox integration cannot be treated like code you write once and safely forget. (RFC 9051 - Internet Message Access Protocol (IMAP) - Version 4rev2)
I have watched teams underestimate this because the first version appears calm. One mailbox. One credential. One folder. One happy-path search. Then real life arrives. The inbox owner adds subfolders. A provider changes auth posture. A mailbox gets large enough that timing and state handling start to matter. Someone asks for retries. Someone else asks to skip duplicates. Another team wants the same script pointed at a second mailbox with slightly different behavior. None of these asks sound dramatic on their own. Together, they create maintenance debt: a pile of small, recurring engineering decisions attached to a script that was never designed to be a product.
This is why custom mailbox readers often feel older than their actual age. The code may be small, but the agreement it must keep with the outside world is broad. When that agreement drifts, engineers start spending time on diagnosis instead of delivery. They inspect flags, replay searches, compare mailbox state, and patch edge cases that were invisible in version one.
The useful mental shift is simple: do not size this kind of integration by lines of code. Size it by the maintenance surface you are accepting. If the workflow depends on IMAP, you are signing up to keep pace with mailbox semantics, client state handling, and protocol evolution over time. Once I frame it that way, the decision gets clearer for both engineering leaders and platform teams. The risk is rarely that the first script was hard to write. The risk is that it quietly becomes permanent infrastructure with no one budgeting for its care.
That is the heart of IMAP maintenance debt. The original task stays small only in memory. The ownership surface does not.
Every provider says IMAP. Each one still changes the engineering math
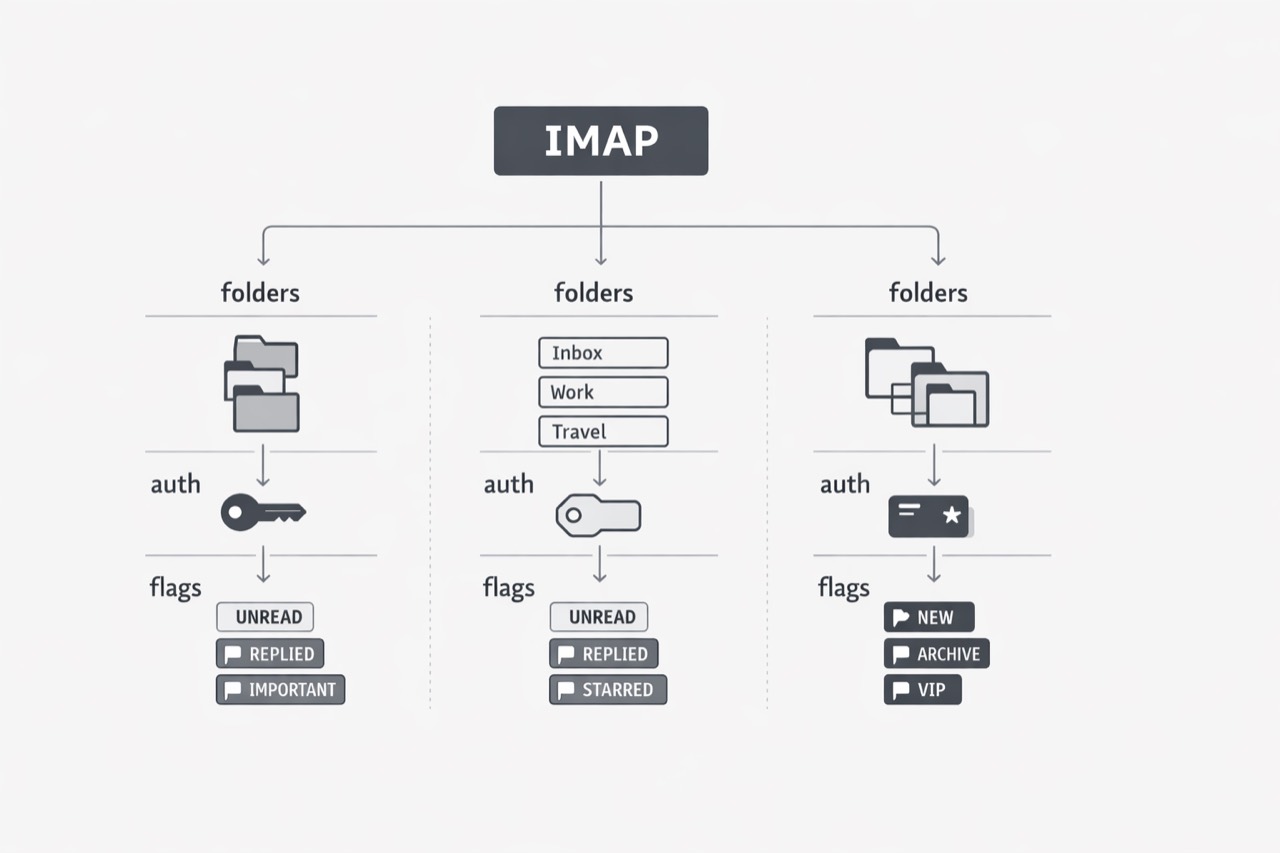
Two systems can both claim IMAP support and still create very different engineering outcomes because the standard does not guarantee identical mailbox behavior or provider semantics. Teams often assume protocol compatibility means reusable integration work, but provider-specific authentication and mailbox models can quickly break that assumption. (RFC 6154 - IMAP LIST Extension for Special-Use Mailboxes)
The burden usually appears as accumulated exceptions rather than one dramatic failure. IMAP special-use mailboxes are standardized through optional attributes, so discovery and naming can vary by server implementation. Gmail adds provider-specific IMAP extensions such as X-GM-LABELS, which changes how engineers must reason about folders, labels, and message handling. Microsoft also changed the practical boundary of IMAP integrations by deprecating Basic Authentication in Exchange Online, pushing older mailbox scripts toward modern authentication flows. (Gmail IMAP Extensions)
The useful takeaway is to treat “supports IMAP” as the start of a scope conversation, not the end of one. Ask which providers, which auth models, and which mailbox semantics are in scope before you estimate effort. That framing helps teams test against provider categories early and avoid underpricing the long-term cost of custom mailbox logic. (Deprecation of Basic authentication in Exchange Online)
Sooner or later, one tiny script ends up with one tired owner
I have learned to watch for a very specific moment in these mailbox projects. The script is still called “small,” but everyone on the team already knows who to message when it breaks. That is the trap. IMAP is stateful by design, so clients must track mailbox state, message state, and recovery behavior carefully enough to avoid missed or duplicated work. Once that logic lives inside a homegrown script, the real asset is no longer the code. It is the person carrying the mental model of how that code survives in production.
You might be wondering why ownership shrinks instead of spreads. In practice, this work is low glory, high context, and full of sharp edges. Engineers can read the script, but fewer want to absorb the operational history behind it: why one mailbox is handled differently, why a reconnect path exists, or why a message flag is checked before moving mail. Provider policy changes can also turn old assumptions into incidents. Microsoft says Basic Authentication for Exchange Online began permanent disablement on October 1, 2022, which shows how platform decisions can break mailbox integrations that once looked stable. When that happens, the burden usually falls to the one person who already knows the old path, the new path, and the workflow waiting on the inbox. (Deprecation of Basic Authentication in Exchange Online - Microsoft Lifecycle)
The useful shift is to stop asking whether the script is small and start asking whether its ownership model is healthy. If safe operation depends on one person remembering hidden state rules and provider-era workarounds, the integration has already become a liability. Treat it honestly as infrastructure with concentrated knowledge risk. Then take one next step within minutes: document the recovery model, list the mailbox-specific exceptions, or decide whether the workflow should move to something with less protocol-specific ownership overhead.
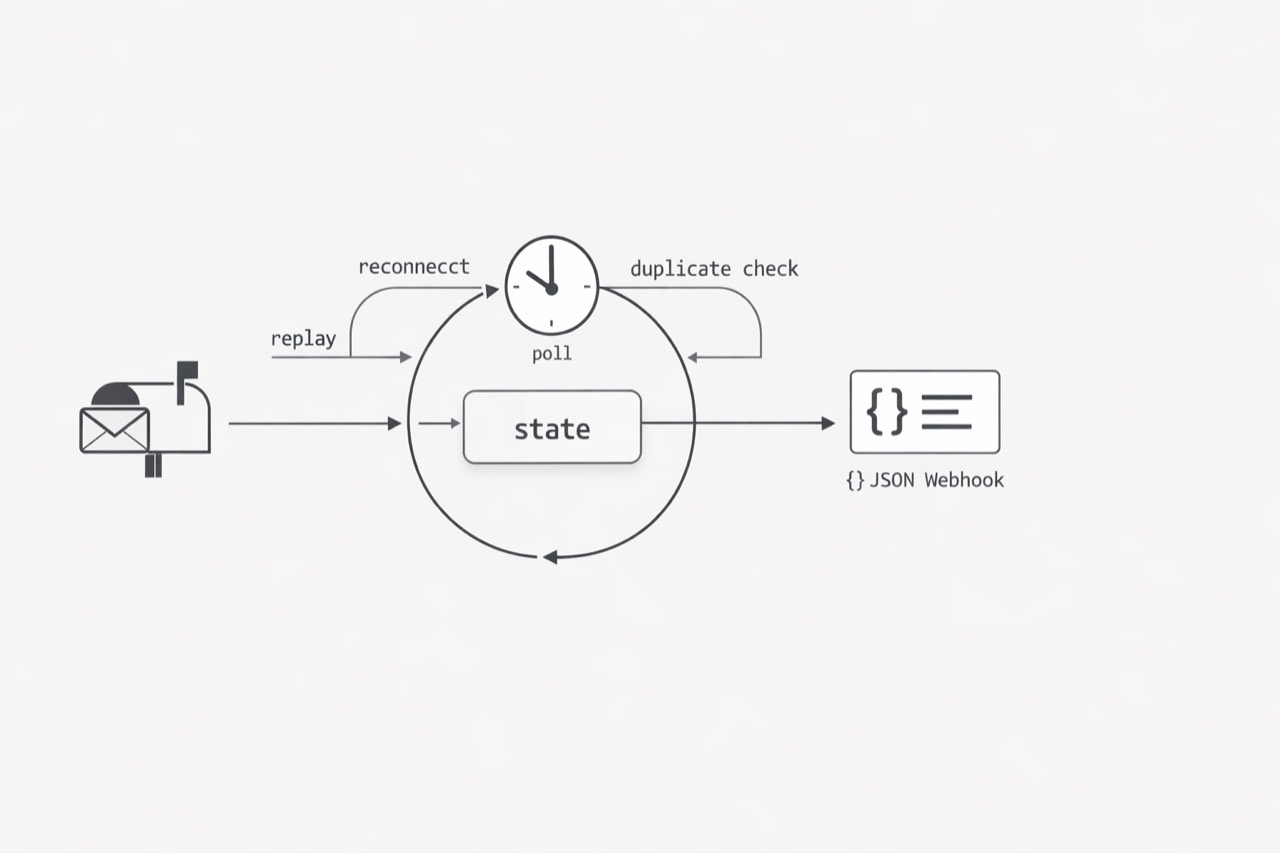
The real complexity is hiding in the poll loop
Teams often describe an inbox reader as a simple timer job: check the mailbox, fetch new mail, mark what was handled, repeat. That sounds safe until you notice the poll loop is really a small reliability system. IMAP IDLE is an extension rather than a universal baseline, so clients may still need polling, reconnect behavior, and fallback handling. Once that is true, the work is no longer just fetching messages; it is deciding what was seen, what was processed, and how to recover when mailbox behavior differs from expectations. (RFC 2177 - IMAP4 IDLE command)
This is where the hidden cost starts to accumulate. A poll loop needs memory: it must track the last successful check, identify which messages were already processed, and distinguish between conditions that call for retry versus stopping before causing more damage. Even if the original requirement sounds basic, the implementation keeps absorbing reliability decisions such as handling dropped connections, duplicate visibility on later cycles, and partial progress before state updates complete.
What many teams miss is that they are not just automating mailbox access. They are building a recurring reconciliation process between their own system state and a mailbox state model they do not fully control. That matters because mailbox semantics can vary by provider. Gmail exposes IMAP settings such as auto-expunge and folder visibility, which can affect what it means for a message to be removed, still present, or visible in a given folder. A fetch loop built on a generic mental model can therefore drift away from production reality without a dramatic code change. (Gmail API - ImapSettings)
Schedule-driven systems also create underestimated failure patterns. If one run fails, the next inherits uncertainty; if runs overlap, state can race; if a retry succeeds after a partial prior pass, the team needs idempotency by design rather than assumption. Over time, the poller accumulates dedupe checks, backoff rules, reconnect logic, alerts, and manual replay steps, turning a mailbox reader into a fragile operational subsystem.
The practical takeaway is to estimate the poll loop like a stateful service, not like a cron task. If the workflow depends on scheduled mailbox reads, reliability comes from disciplined state handling, explicit recovery design, and clear assumptions about provider behavior. Polling can work, but the real decision is whether the team wants to own the logic required to keep that loop trustworthy over time.
The common failure in these projects is not that teams chose a bad tool in a bad moment. It is that they made a reasonable short-term choice and then kept paying for it long after the original tradeoff stopped making sense. A custom IMAP script can absolutely work. The problem is that working today is not the same as being cheap to own over time.
Once you look closely, the pattern is consistent. The maintenance surface grows with protocol realities. Providers change the implementation math. Ownership narrows to the people who remember the exceptions. The poll loop turns into a reliability subsystem. None of that shows up in the original script size, but all of it shows up in engineering time.
That is why these integrations age badly: they inherit the full complexity of mailbox state and provider change while pretending to still be lightweight glue. If your team is carrying one of these readers now, the useful next step is not denial or endless patching. It is to evaluate the true ownership cost and ask whether the workflow should still depend on custom mailbox polling at all. In many cases, the better long-term answer is an event-first architecture that reduces protocol-specific handling, narrows the failure surface, and gives engineering teams back time they should not be spending babysitting an inbox.