Most teams believe they have a simple email setup, and that is exactly why email routing complexity gets underestimated. One shared address. A few email routing rules. Maybe a forwarding alias, a weekend backup inbox, and one quiet exception for a high-priority customer. From the outside, it still looks like one inbox.
Then six months pass.
Support wants one path, finance wants another, operations wants alert copies, and product wants structured events pushed into downstream systems. A team that started with one support alias and two forwarding rules can end up eighteen months later with eleven active rules across three mailbox tools. Two are understood by only one person, and one is still firing even though nobody is sure who requested it.
Each addition solves a real problem, and no single change feels large enough to call architecture. That is how email routing complexity usually grows: not through one bad decision, but through many reasonable local fixes layered onto the same familiar entry point.
This post is about the moment a mailbox stops being a communication tool and starts behaving like an undocumented workflow system. Email routing rules can be useful, but when routing, ownership, visibility, retries, and escalation depend on scattered inbox behavior, the organization has built an operating surface it can no longer review in one place.
One inbox rarely stays one route for long
A shared mailbox often looks like one of the safest places to automate. There is one address, one inbound stream, and usually one obvious reason to start: forward certain messages, trigger a workflow, or send specific email to the right queue.
The first version usually feels clean. A sender domain gets one rule. A subject line gets another. A partner address routes to the right team. Then the first successful automation becomes the reason to layer the next business case onto the same path.
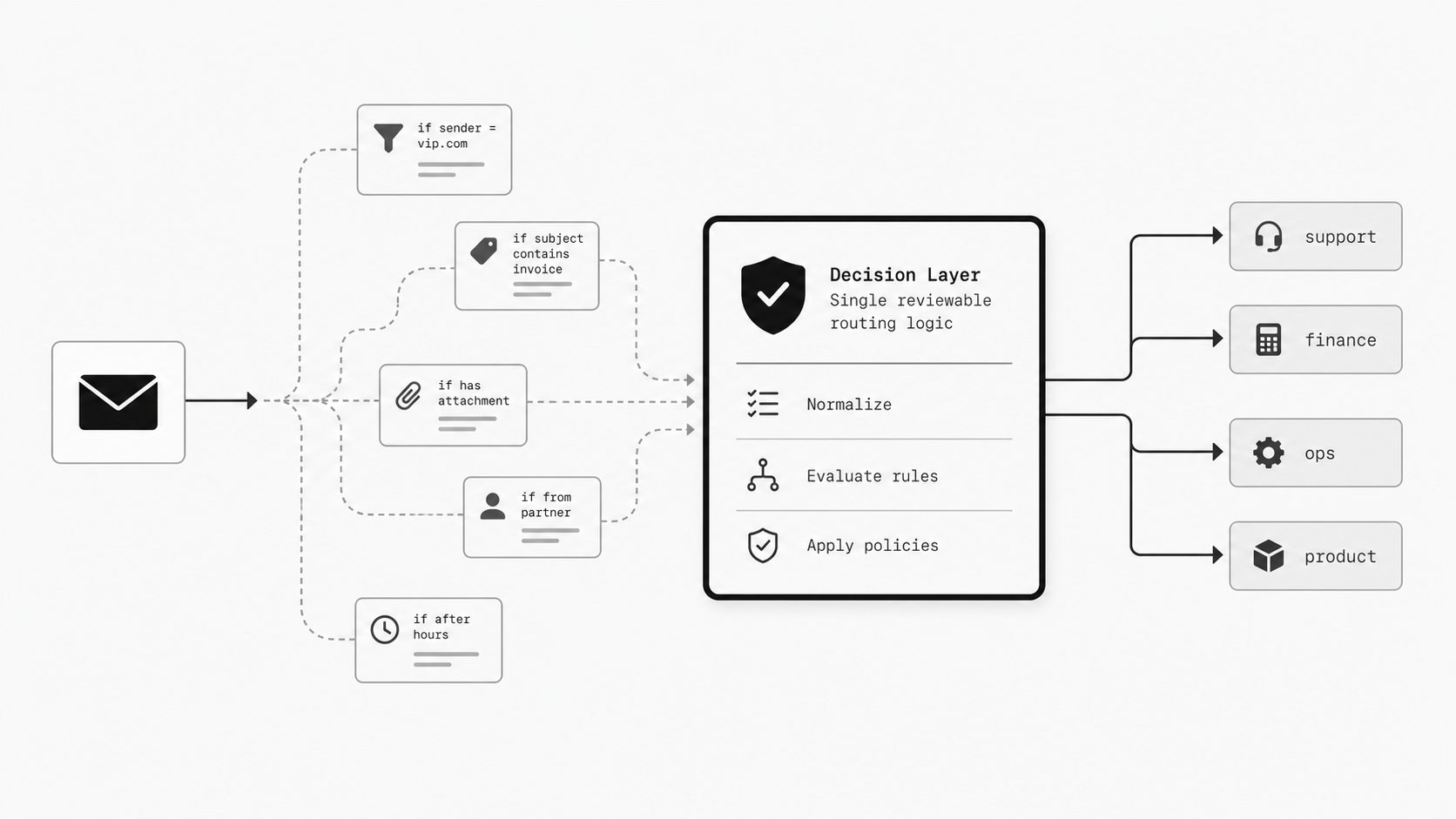
That is where route explosion begins. The entry point stays familiar, but the downstream behavior stops being simple. One inbound source may feed people, ticketing systems, archives, monitoring tools, compliance workflows, and API-based processing at the same time. As conditional rules accumulate, overlap and precedence start to matter.
Email routing rules do not stay small just because the address stays familiar. Once a single inbound source begins feeding several workflows, the real challenge is no longer only delivery. It is ownership, visibility, precedence, duplicate handling, and control. Flexibility without a review model becomes a hidden control plane. (Google Workspace Admin Help - Set up routing for inbound email)
The practical test is simple: if one inbox already feeds multiple destinations and conditional actions, treat those routing rules as shared logic now, not later. Naming the pattern early makes it easier to design for growth before a familiar mailbox becomes unmanaged operational infrastructure.
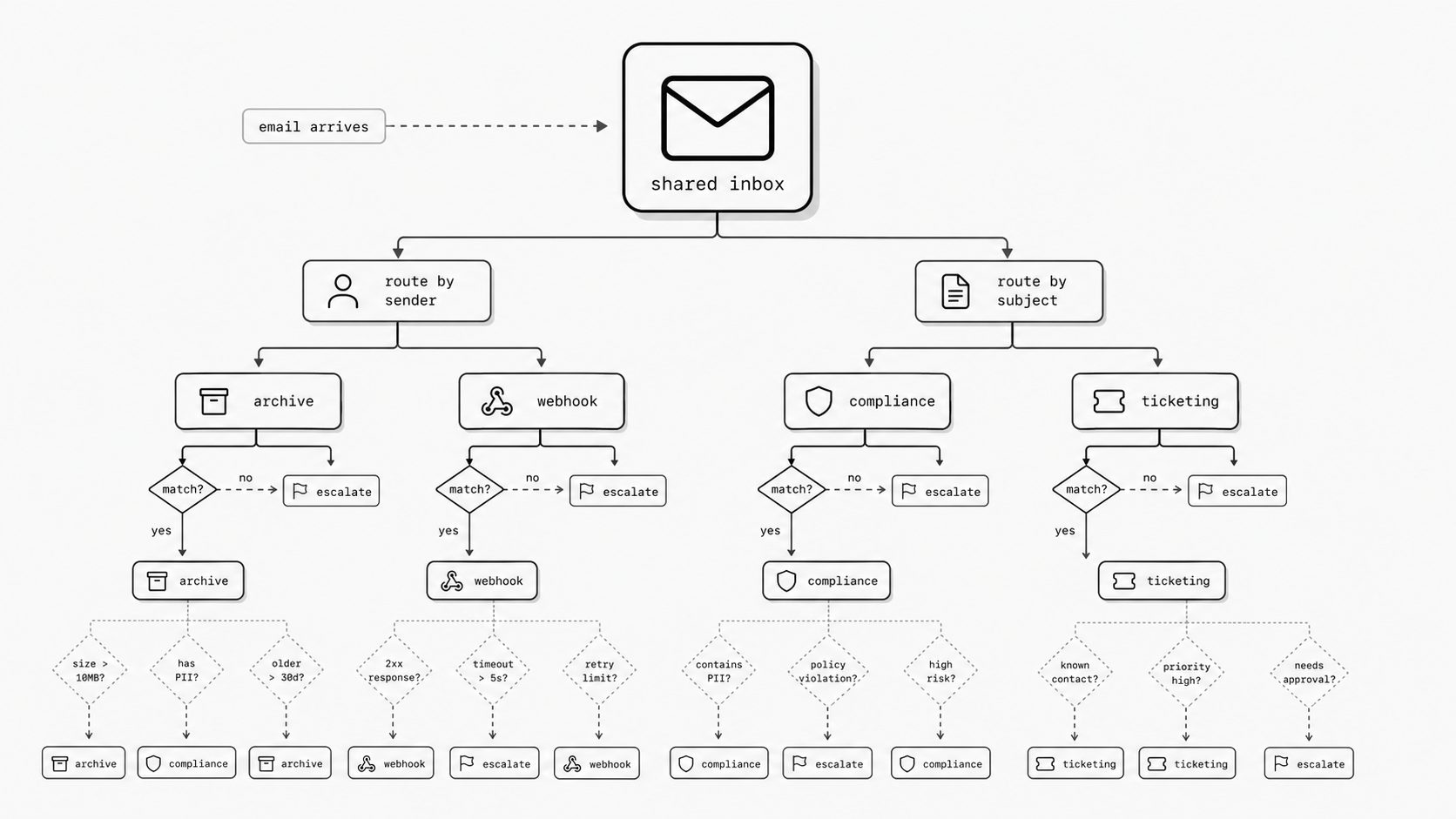
Every new exception adds one more hidden hop
I have seen this pattern start with a reasonable exception. One VIP customer needs faster handling. One region needs a different approver. One product line needs a backup inbox for weekends. So the team adds a rule, an alias, a shared mailbox, or a quiet forward to one more person.
Each change works in the moment. Together, they create forwarding-chain sprawl.
Key term: Forwarding-chain sprawl is what happens when operational routing logic spreads across aliases, personal rules, shared mailbox settings, and informal forwards until nobody can draw the full path of a message.
This becomes a leadership problem the moment the inbox carries a business-critical workflow. At that point, every hidden hop raises the odds of delay, duplicate handling, and silent failure because the real process lives in scattered settings instead of one visible system.
One person creates an inbox rule. Another adds forwarding in a mailbox setting. A third changes the shared mailbox habit by telling the team, not the system. Soon the organization believes it has a simple intake path, while the real path includes customer tier, geography, vacation coverage, after-hours support, and old workarounds that were never removed.
The risk is accumulation. Hidden hops are easy to change and hard to see. They borrow structure from the inbox, which was built for communication, then stretch it into workflow control. Early on, the speed is useful. Later, the same design creates drag because nobody can inspect the whole flow at once.
Every new forwarding exception is a process decision, even when it is implemented as a mailbox convenience. Once you see it that way, the warning sign becomes easier to spot. If your team needs hidden hops to express priority, coverage, routing, escalation, or categorization, then the inbox is already acting like an informal workflow engine.
When routing logic lives everywhere, nobody can review it
The inbox may still look simple from the outside while the real decision logic is spread across mailbox settings, forwarding rules, help desk automations, integration services, and custom handlers. Once that happens, no single owner can review the full behavior in one pass.
This is where operational confidence starts to drop. If an executive asks, “Why did this email go here, and can we prove it will do the same tomorrow?” the answer often requires several admin consoles and several people. That is an architecture problem because the system cannot explain its own behavior.
Shared mailbox access adds another layer of confusion. Access tells you who might act. Ownership tells you who must act and who is accountable if progress stalls. A complaint or approval can sit in a mailbox many people can open, yet no one may be responsible for moving it from arrival to resolution.
When the inbox cannot show workflow state clearly, teams often build a spreadsheet beside it: owner, priority, status, escalation notes. Over time, that sheet becomes the control layer the team actually trusts. If it vanished, the team might lose track of what is waiting, who owns it, what is late, and what needs escalation.
That is the operating signal: the mailbox is no longer only receiving messages. It is coordinating work through side channels the organization did not formally design.
I would want any team to answer four questions quickly: what matched, why it matched, where it went, and what happened next. Those questions sound basic, but they are the minimum proof that routing logic is reviewable. If the answers require four tools and three owners, the logic is too scattered to govern well. The team does not need perfect simplicity, but it does need one dependable way to inspect the behavior that the business depends on.
More destinations means you need rules about the rules
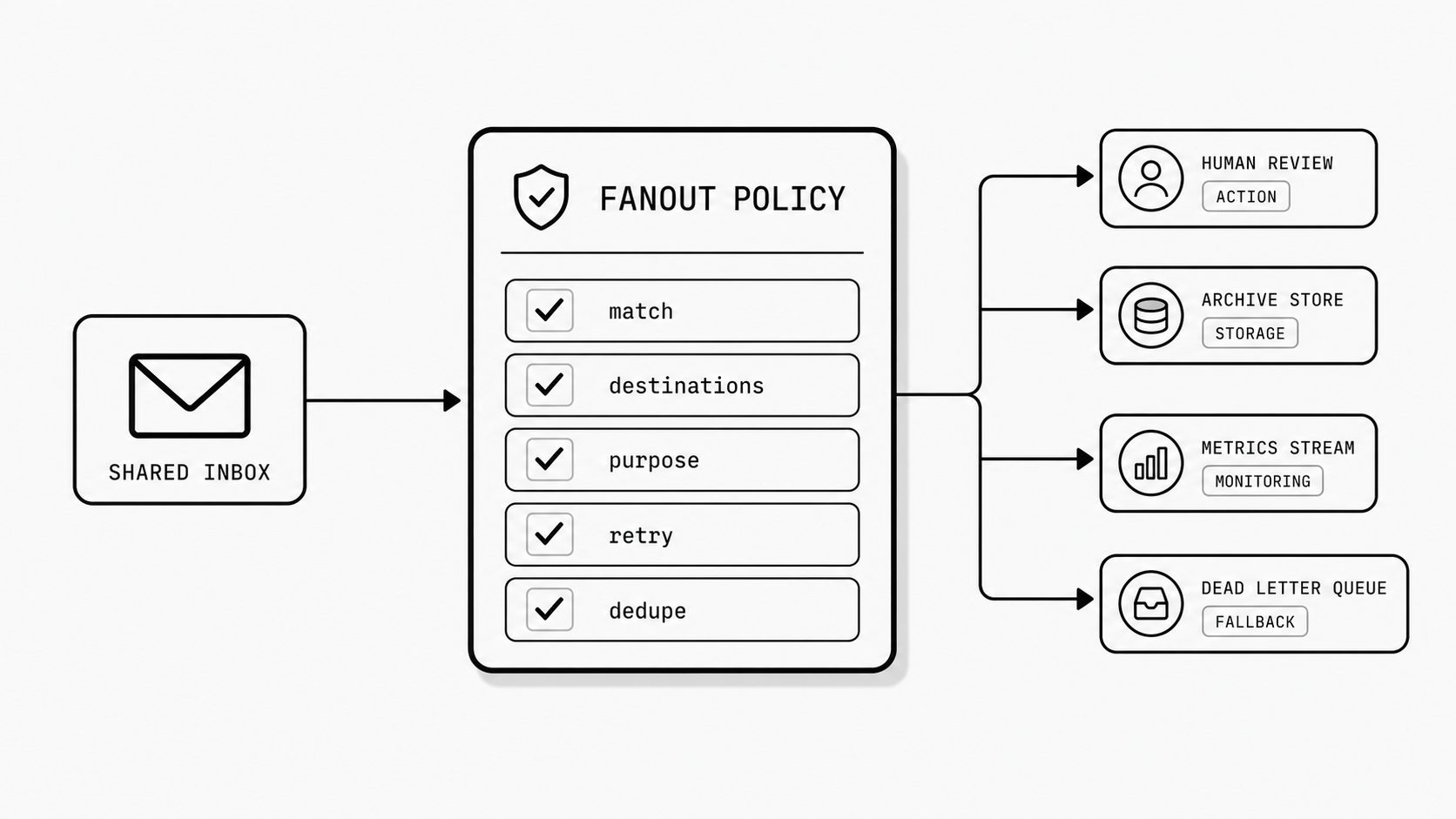
Teams cross an invisible line when one inbound message can land in several places. A shared address sends messages to a person, a queue, an automation, a compliance copy, and then a webhook for a downstream process. Suddenly the risk is no longer simple delivery. The risk is overlap.
Some destinations are for action. Some are for storage. Some are for monitoring. Some exist only as fallback. If those roles are not written down, every recipient or endpoint may assume it is allowed to act on the message. That is where duplicates, race conditions, and conflicting records begin.
This is fanout governance.
Key term: Fanout governance means defining who receives a message, who may act on it, what retry behavior is expected, and how duplicate processing is prevented when one inbound source feeds multiple destinations.
Once one message can land in several places, each destination can have its own delivery behavior, retry pattern, and failure state. One system may accept immediately. Another may retry later. A third may process the same payload again unless deduplication and validation are built into the flow. Published delivery systems treat retries and resilience as operational concerns, which is the right mental model for email routing once messages feed software workflows. (Courier Docs - Delivery Reliability and Retries)
This is why leaders need rules about the rules. For every inbound route, I would want one simple policy view: the match condition, approved destinations, purpose of each destination, retry expectation, and deduplication key or replay rule if programmatic processing is involved.
For MailWebhook route configuration, the source-of-truth implementation references are the route rules and route pipeline docs.
Without that layer, teams keep adding useful local automations while the shared inbox becomes a multi-system control point with no clear operating model. When something breaks, the investigation starts in the ruins: traces spread across mailboxes, rules, logs, and admin tools. The team has to reconstruct what happened from fragments instead of reading a clear operational history.
The important shift is mental. Once one inbound stream feeds many systems, you are no longer managing only message transport. You are governing shared operational consequences.
What a reviewable routing layer actually looks like
The goal is not to eliminate flexibility. Email remains useful because it can absorb messy, external, and exception-heavy work. The goal is to make growth reviewable.
A reviewable routing layer has one central principle: routing logic should be defined in one authoritative place, with clear precedence, expected destinations, and observable results, regardless of which tool implements the delivery.
In practice, I would make that framework concrete in three ways.
First, it is inspectable. The team can open one view and see every active rule, condition, priority, destination, and owner before the message enters the next system, without relying on the person who built the rule two years ago.
Second, it is governed. A new route requires someone to name an owner, purpose, priority, and failure behavior before it goes live, not after something breaks.
Third, it is observable. Routing outcomes, delivery failures, retries, and duplicate handling are logged in a way operators can review. When a message goes missing, the team reads the routing history instead of reconstructing it from memory and inbox searches.
This is the real architecture reframe. Forwarding rules are not an architecture. They are often evidence that a real architecture is overdue. The better pattern is a controlled intake and routing layer that lets teams keep email’s flexibility while making ownership, fanout, and failure behavior explicit.
What looked like one inbox and a few rules can quietly become a routing surface with precedence, side effects, retries, and ownership gaps. That does not make email the problem. It means the organization has outgrown informal handling.
For technical leaders, the signal is straightforward: if the business depends on the workflow, the workflow should be visible, governable, and owned. Mailbox conveniences can help with communication, but they should not carry the core logic of intake, routing, escalation, and completion.
When those rules should trigger software rather than more forwarding, the core owner page is the software-triggered intake path.
If this pattern sounds familiar, the broader series goes deeper on two adjacent questions: why email still runs critical operations and why teams eventually need an email ingestion layer before inbound messages become application data or operational work.
But the routing lesson is narrower and more urgent: the moment one inbox feeds several workflows, treat the rules as production logic. If the business relies on the route, the route should be visible before it fails.