Most platform problems do not announce themselves as leadership problems at first. They show up as one more integration delay, one more downstream exception path, one more incident where teams spend the first half hour arguing about whether the data changed or the code failed. That is why I think deterministic JSON belongs in executive conversations. The issue is not aesthetic consistency. The issue is whether shared systems can evolve without quietly pushing cost, uncertainty, and delay into every team that depends on them.
Right now, that question matters more than usual. Teams are under pressure to reduce integration cost, move faster across service boundaries, and avoid hidden maintenance work accumulating in downstream systems. When payload structure is inconsistent or loosely governed, every consuming team compensates in its own way. Over time, that creates duplicated logic, weaker planning confidence, and a platform that gets harder to change the more successful it becomes.
In this post, I make a simple argument: stable payload structure is not just an engineering preference. It is a leadership concern because it shapes delivery speed, trust between teams, and the economics of operating a platform at scale.
Why I treat payload structure as a leadership decision
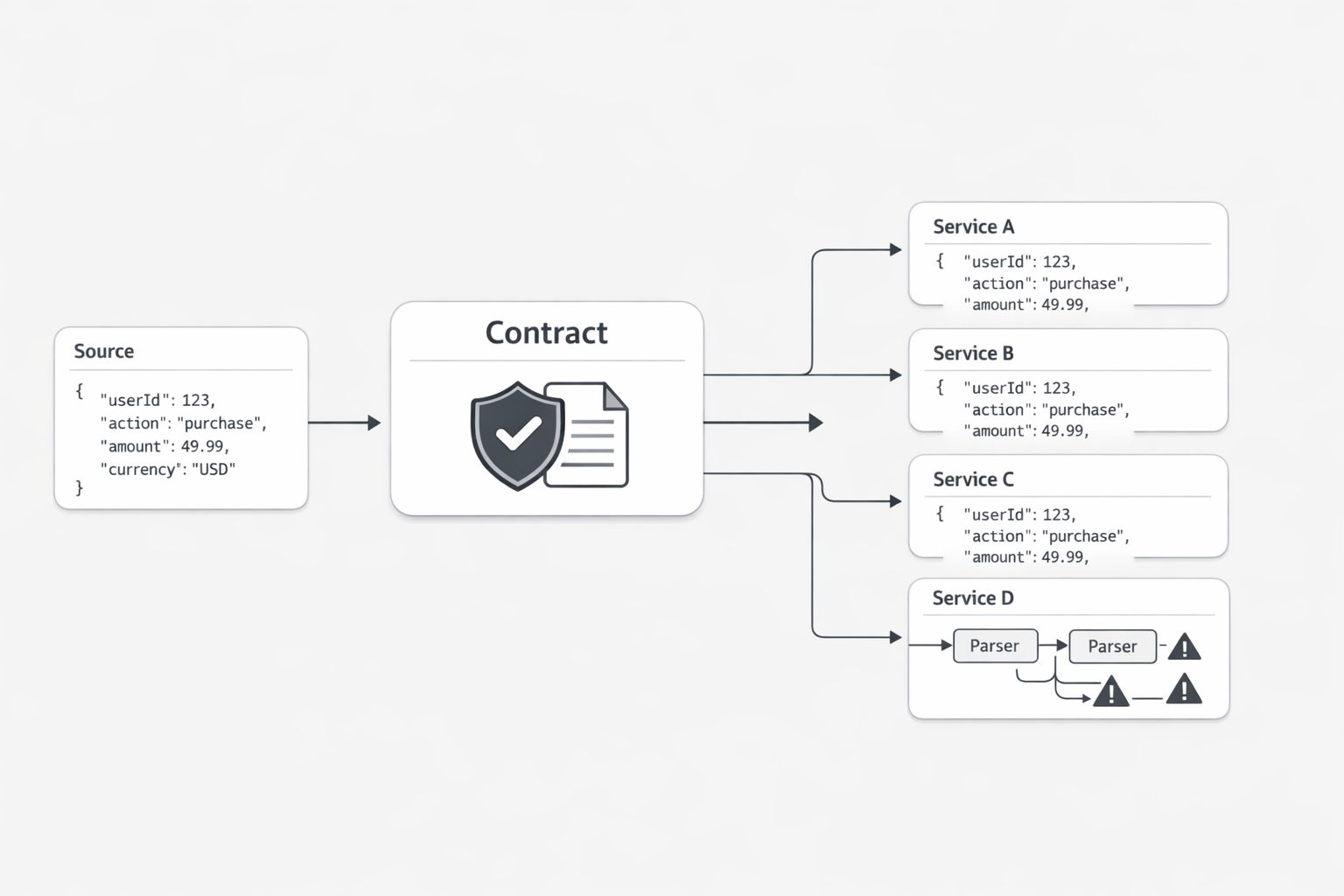
I have learned to pay close attention when a payload makes every downstream team ask the same anxious question: “Can we trust this shape next week?” That question sounds technical, yet it drives planning risk, delivery risk, and support cost across the organization. JSON Schema exists to help teams keep structured data exchange consistent, which tells me this is a coordination problem as much as a coding problem. When the structure of a payload shifts without clear control, each consuming team starts building private checks, fallback paths, and local assumptions just to stay safe. Leadership owns that outcome because leadership sets the standards that either contain variation or let it spread. (What is JSON Schema?)
You might be wondering: why elevate payload structure to the executive level? My answer is simple. Shared interfaces shape how fast teams move together. If one producing service sends data in a way that changes field presence, nesting, or version signaling from one release to the next, every dependent team has to spend time re-reading docs, retesting flows, and hardening code around uncertainty. A deterministic payload contract reduces that uncertainty by making the structure dependable and by declaring version information explicitly, which supports stable downstream consumption. (JSON Schema documentation style guide)
That is why I see payload design as an operating model decision. Leaders choose whether integration work will be a reusable platform capability or a repeated local burden. When version declaration is treated as a visible part of the contract, teams get a cleaner path for validation, migration planning, and change review. When it is left vague, the burden moves outward into every consumer. The producer may feel fast for a sprint. The organization pays for it for much longer.
In practice, I look for one simple test: can a platform lead explain the contract rules in a few plain sentences? If the answer is yes, teams can build with confidence. If the answer turns into exceptions, tribal knowledge, and “it depends,” then the organization is carrying hidden integration debt. That debt rarely stays contained. It shows up in delayed launches, brittle automations, and longer incident calls because people first have to determine whether the issue is business logic or payload drift.
So here is the leadership takeaway I use: payload structure is a governance choice with direct economic effects. A deterministic payload contract gives teams a shared point of truth for validation and change management, and JSON Schema is specifically intended to support consistent structured exchange. Root-level version declaration is also a documented practice, which reinforces the idea that compatibility should be explicit rather than assumed. When I ask teams to make those choices up front, I am not asking for extra ceremony. I am protecting delivery capacity across every service that depends on the contract.
If you lead a platform, this is the question worth asking in your next review: are we shipping data that other teams can trust without negotiation? If the answer is unclear, the issue is already bigger than code.
So where does the money actually go?
I have seen this movie too many times. One producer says the payload change is small. A field moved. A null showed up where an object used to be. A version rule lived in a release note instead of in the contract. On the producer side, it feels minor. On the consumer side, it triggers a chain of extra work that rarely appears on any budget line. (Consumer-Driven Contracts: A Service Evolution Pattern)
Key term: Consumer simplicity economics means the money an organization saves when downstream teams can integrate without building extra checks, exceptions, and recovery logic.
That is the part I want technical executives to see clearly. The cost is usually not in the first code change. The cost spreads into every team that has to interpret, guard, transform, test, and monitor around that change. Once that pattern repeats across several services, what looked like a local engineering choice becomes an operating expense problem. (Release, versioning, and breaking change policies)
You might ask: where does that expense actually show up? I would break it into four places.
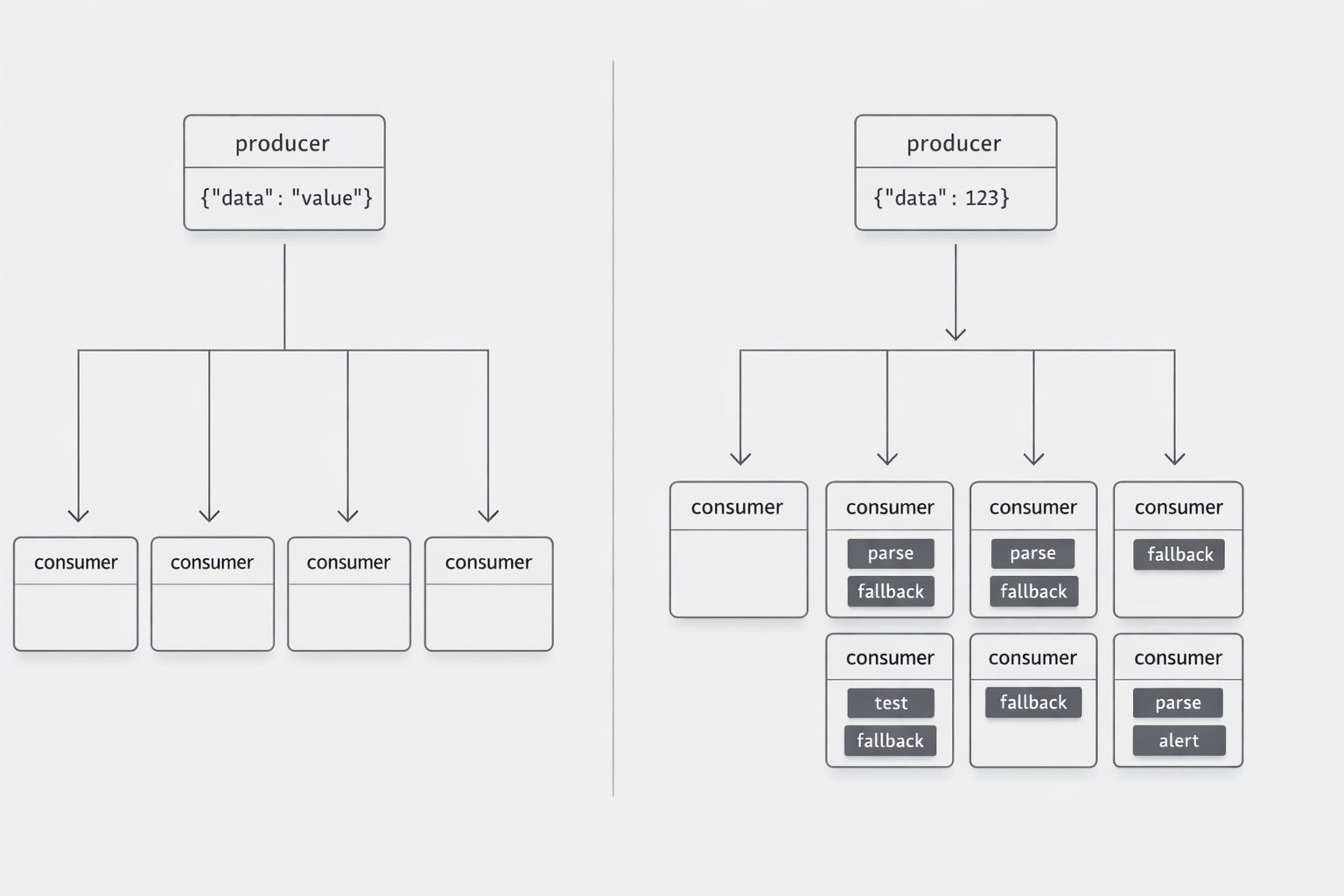
First, it shows up in duplicate logic. When consumers cannot rely on a clean contract, each team writes its own fallback handling, field checks, and translation rules. Consumer-driven contracts are meant to align provider behavior with consumer expectations during service evolution, which is exactly why they reduce mismatch risk across teams. If that alignment is weak, every consumer builds its own safety net. The organization then pays for the same protective idea many times.
Second, it shows up in testing drag. Backward compatibility policies exist because interface changes can break consumers, and explicit versioning gives teams a managed path for change. Without that discipline, downstream teams expand regression coverage, add scenario tests for edge cases, and hold releases longer while they verify whether old and new shapes both need support. That extra caution is rational. It is also expensive.
Third, it shows up in incident handling. When a workflow fails and the payload shape is not fully dependable, teams spend early incident minutes proving whether the issue came from business logic or a contract shift. That slows triage and creates more coordination overhead across service owners. Fowler’s discussion of service evolution centers on avoiding provider-consumer mismatches through clearer contracts, which supports faster diagnosis when things change.
Fourth, it shows up in planning behavior. Teams that expect surprises design roadmaps differently. They buffer more time, delay adoption, and prefer local workarounds over shared dependencies. Microsoft states that versioning and breaking change policies are there to manage compatibility over time. I take a practical lesson from that: when compatibility is managed well, teams can plan with less fear. When it is managed poorly, they plan around instability.
This is why I call it economics, not elegance. Simpler consumption lowers repeated labor. It lowers retesting. It lowers support friction. It lowers the number of private interpretations of the same interface. None of that may look dramatic in one sprint. Across a platform, it compounds fast.
So where does the money actually go? Into hidden repetition. Into defensive parsing. Into bigger regression suites. Into longer incident calls. Into roadmap padding that nobody labels as payload tax.
My executive takeaway is simple: every unclear interface decision made once by a producer can create many small costs for consumers. Clear contracts, managed evolution, and backward compatibility reduce mismatch risk and make downstream work lighter over time. That is why I do not treat consumer simplicity as a developer convenience. I treat it as a scaling decision.
If I am reviewing a platform team, I ask one blunt question: how much downstream code exists only because your interface cannot be trusted to evolve cleanly? Leaders who can answer that question usually find savings quickly. Leaders who cannot answer it are often funding the same integration work again and again.
What trust looks like when teams stop guessing
A platform has a trust problem when teams ask for sample payloads more often than they ask for product context. That behavior suggests they do not believe the contract alone is safe to build against. Compatibility policies exist to define how schemas can change over time and what old and new versions are allowed to do together. (Schema Evolution and Compatibility for Schema Registry on Confluent Platform)
Trust looks boring in the best way. A consuming team can read the contract and understand how change will be handled. They know whether a new field can appear safely and whether older or newer readers can still process the data under published compatibility rules. Confluent documents backward and forward compatibility as explicit schema evolution policies, which helps teams rely on rules instead of hallway explanations. It also looks testable: with explicit versioning, teams can evaluate a change before absorbing it into production behavior. Stripe describes API versioning as a precaution so customers can test a new API version before committing to an upgrade. When compatibility and version handling are visible, delivery planning gets calmer because teams share assumptions about interface change and can choose when to adopt updates. (Schema Compatibility)
Use schema confidence as a leadership test: can a consumer team explain the change rules and version path without calling the producer? Compatibility rules give teams a formal basis for evolving schemas while reducing surprise breakage, and explicit API versioning gives them a controlled way to test changes before committing. When that is true, roadmap planning tightens, integration reviews shorten, and trust becomes operational instead of personal. (Versioning - Stripe API Reference)
Here is where small payload drift turns into a big platform problem
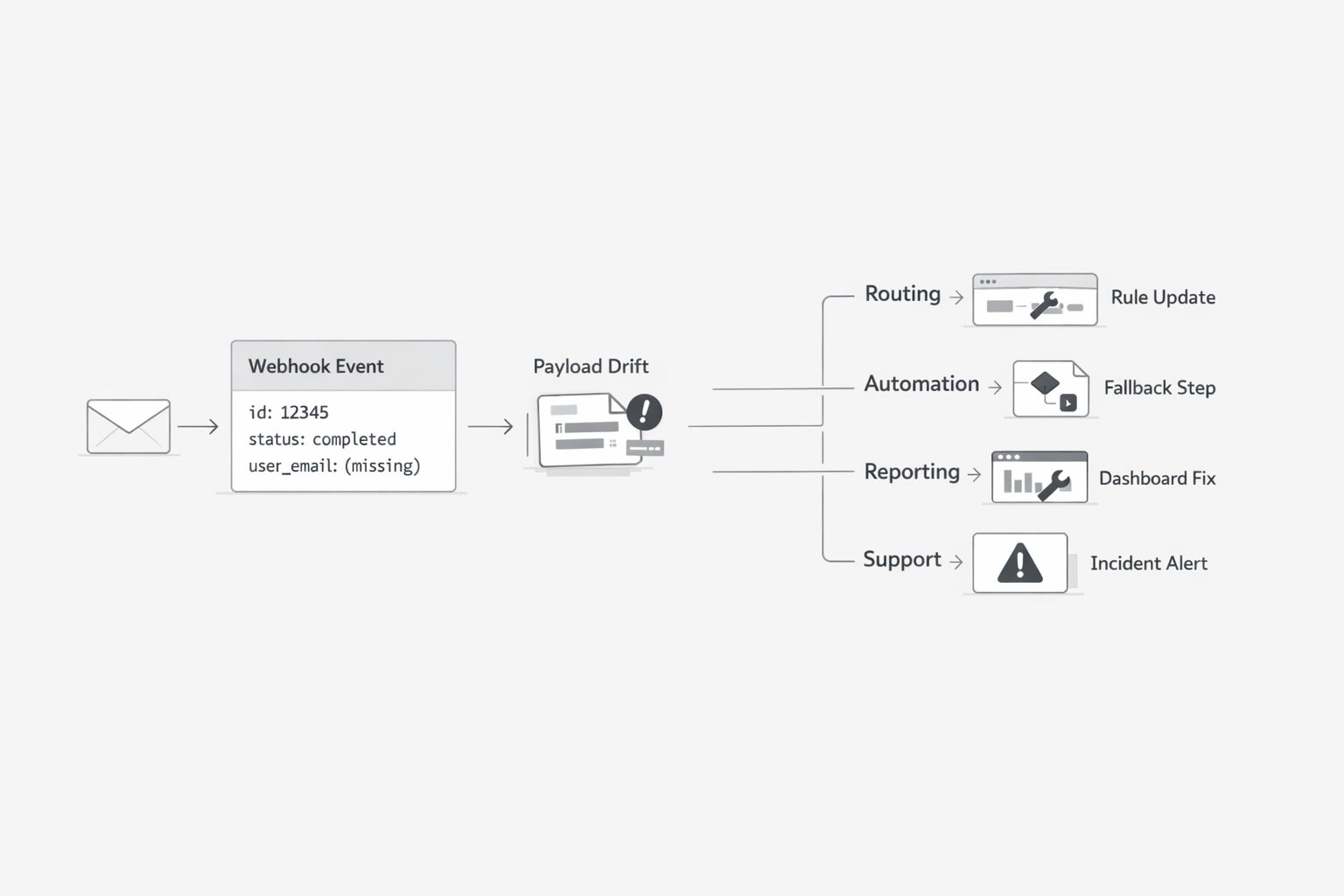
I have learned that payload drift rarely stays where it starts. A producer changes one field, one nesting rule, or one event interpretation, and the blast radius moves outward into every connected workflow. That matters even more when the source is email-derived data, because email is still a major business channel and global volume remains enormous. In plain terms, a small contract wobble at the source can become a large operations problem across routing, automation, reporting, and support queues. (Email Market, 2024-2028 - Executive Summary)
You might be wondering: is that really a platform issue? I think it is, because the multiplier effect comes from scale. One producer can introduce one variation. Ten consuming services then each build their own parser fix, test case, exception path, and monitoring rule. The original change happens once. The maintenance burden repeats many times. (Moving Toward a Stable Spec)
This is where technical leaders can miss the real cost. They see a minor producer update and assume the effort is local. The harder truth is that each consumer has to decide how to survive the ambiguity. Some teams accept both old and new structures. Some add translation layers. Some create manual fallback steps when parsing fails. Some expand alerting because they no longer trust the event shape to stay consistent. None of that work is visible in the producer backlog, yet it is still real organizational work.
I see this most clearly in email-linked workflows. Email continues to sit inside customer support, sales motion, compliance records, service notifications, and operational approvals. When email-derived events feed multiple downstream systems, even small inconsistency can spread fast. A changed field name may break one router. A missing value may distort one dashboard. A different nesting pattern may force another team to rewrite enrichment logic. Soon the organization is maintaining many interpretations of what should have been one shared event model. (Email Statistics Report, 2024-2028 - Executive Summary)
That is why backward compatibility matters so much here. The JSON Schema community has explicitly framed stability work around protecting backward compatibility so future schema changes do less harm. I take a very practical lesson from that. If change policy is weak, every consumer becomes its own compatibility layer. If change policy is strong, the producer absorbs more discipline up front and the whole platform carries less repair work later.
From a leadership view, this is a force multiplier in the wrong direction. One unstable interface creates many local maintenance loops: more regression checks, more exception handling, more incident triage, more coordination between teams trying to determine whose interpretation is now correct. The issue is not just extra code. It is extra organizational drag.
So here is the insight I want executives to hold onto: payload instability scales by consumer count. The more systems that depend on the event, the more one small producer-side drift multiplies maintenance, support effort, and delivery friction across the platform. In environments where email remains a core operational channel and volumes stay high, that multiplier can become large very quickly.
My rule is simple. When I review an integration surface used by many teams, I do not ask only whether it works today. I ask how many separate teams will pay when the shape changes tomorrow. That question usually exposes the real platform risk. If the answer is “many,” then contract discipline belongs on the leadership agenda, because repeated downstream maintenance is a scaling problem, not a local engineering detail.
If there is one point I want leaders to keep, it is this: interface instability rarely stays local. A producer may experience a payload change as a small technical adjustment, but the organization experiences it as repeated downstream work. The costs show up in defensive parsing, broader regression testing, slower incident response, roadmap padding, and a steady loss of confidence in shared systems.
That is why deterministic payload design deserves executive attention. A dependable contract, explicit version handling, and clear compatibility rules do more than help engineers write cleaner integrations. They protect coordination across teams and keep maintenance from multiplying silently with every new consumer. For technical executives and platform leads, that makes payload discipline a governance choice with real operating impact.
So the next time an integration surface comes up in review, I would ask a higher-level question than whether it works today: can other teams trust it tomorrow without negotiation? If the answer is uncertain, the risk is already organizational.