A shared mailbox often looks like one of the safest places to automate. There is one address, one stream of inbound messages, and usually one obvious reason to start: forward certain emails, trigger a workflow, or send specific messages to the right queue. For a while, that feels manageable.
Then growth changes the shape of the problem. Support wants one set of handling rules. Finance needs another. Operations adds monitoring and fallback paths. Product wants structured events pushed into downstream systems. What started as one inbox becomes a decision point for multiple teams, tools, and exception paths.
This is the part many organizations underestimate. Email routing rules do not stay small just because the entry point stays familiar. Once a single inbound source begins feeding several workflows, the real challenge is no longer only delivery. It is ownership, visibility, precedence, retries, duplicate handling, and control.
In this post, I show how that complexity builds, why scattered rule logic becomes hard to trust, and why platform engineers and ops architects should treat inbound email routing as shared operational infrastructure earlier than most teams do.
One inbox rarely stays one route for long
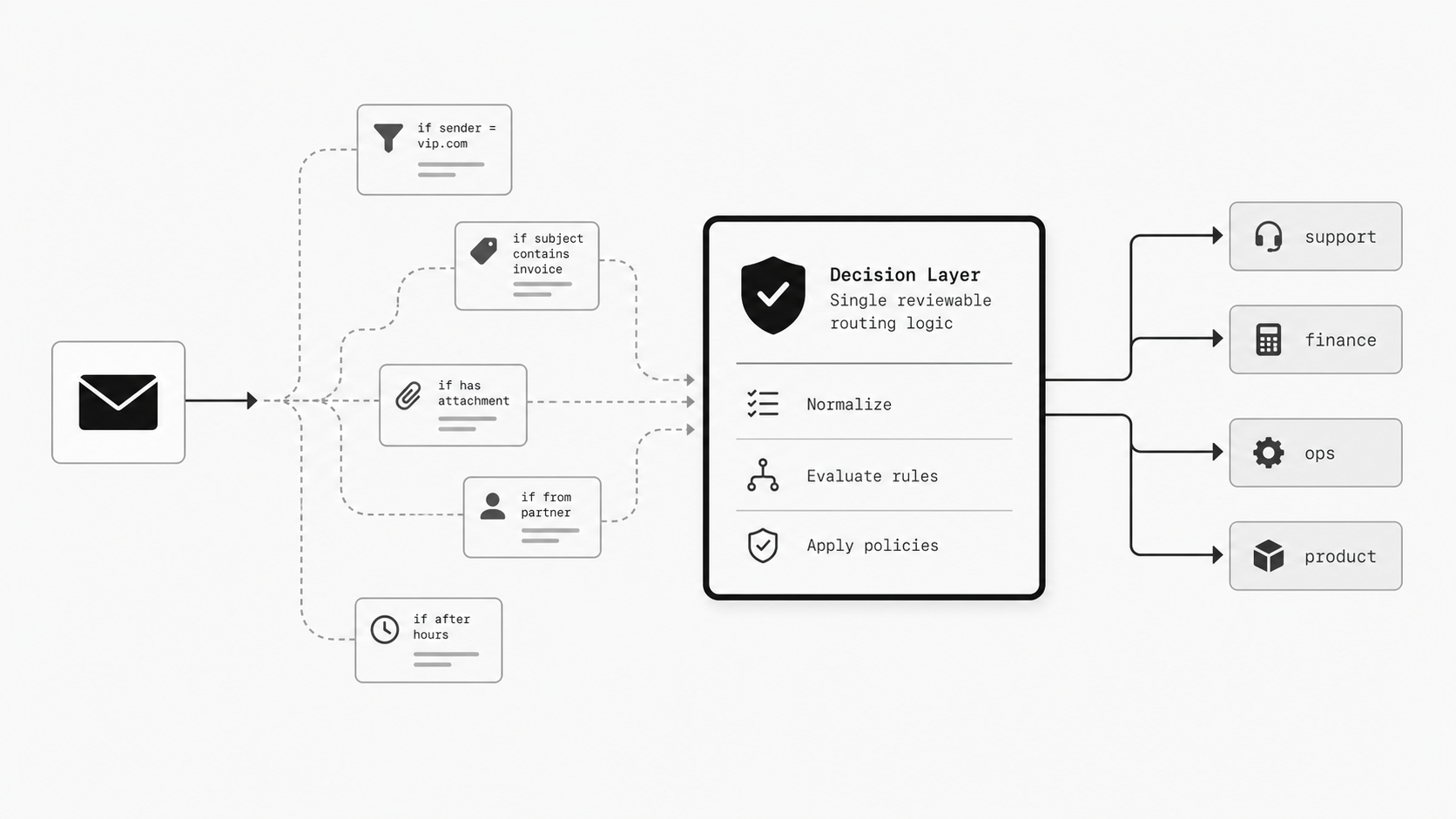
What looks like a harmless shared inbox often turns into a switching point for many downstream actions surprisingly fast. Email systems have long supported aliases and list-style expansion, so one address feeding multiple paths is built into the medium before teams add business logic. (RFC 5321 - Simple Mail Transfer Protocol)
In practice, the first version often feels clean. Teams may add receipt rules, conditional forwarding, or webhook-style handling for narrow use cases based on sender, subject, or message properties. That seems manageable because each rule is approved one at a time and solves a real need. But the number of paths can rise faster than leaders expect, and each new branch often brings exceptions, fallback handling, audit concerns, and ownership questions. (Amazon SES Developer Guide - Receiving Email with Amazon SES)
The surface still looks simple: one mailbox, one familiar address. Underneath, that inbound stream may feed people, ticketing systems, archives, analytics pipelines, compliance workflows, and API-based processing at the same time. As conditional rules accumulate, logic stops being linear. Overlap, rule priority, and evaluation order start to matter, and silent failures can become expensive operationally. (Gmail Help - Create rules to filter your emails)
This is why routing should be treated as shared production logic rather than scattered mailbox tweaks. When rules are split across mailbox settings, forwarding tools, and custom handlers, it becomes harder to answer which messages go where, which rule wins, and who owns the current behavior. (Cloudflare Email Routing documentation)
The practical takeaway is simple: route explosion starts before most organizations recognize it as architecture. If one inbox is already feeding multiple destinations and conditional actions, treat those email routing rules as shared logic now, not later. Naming the pattern early makes it easier to design for growth, reduce hidden conflicts, and keep one source from turning into unmanaged operational complexity.
When routing logic lives everywhere, nobody can review it
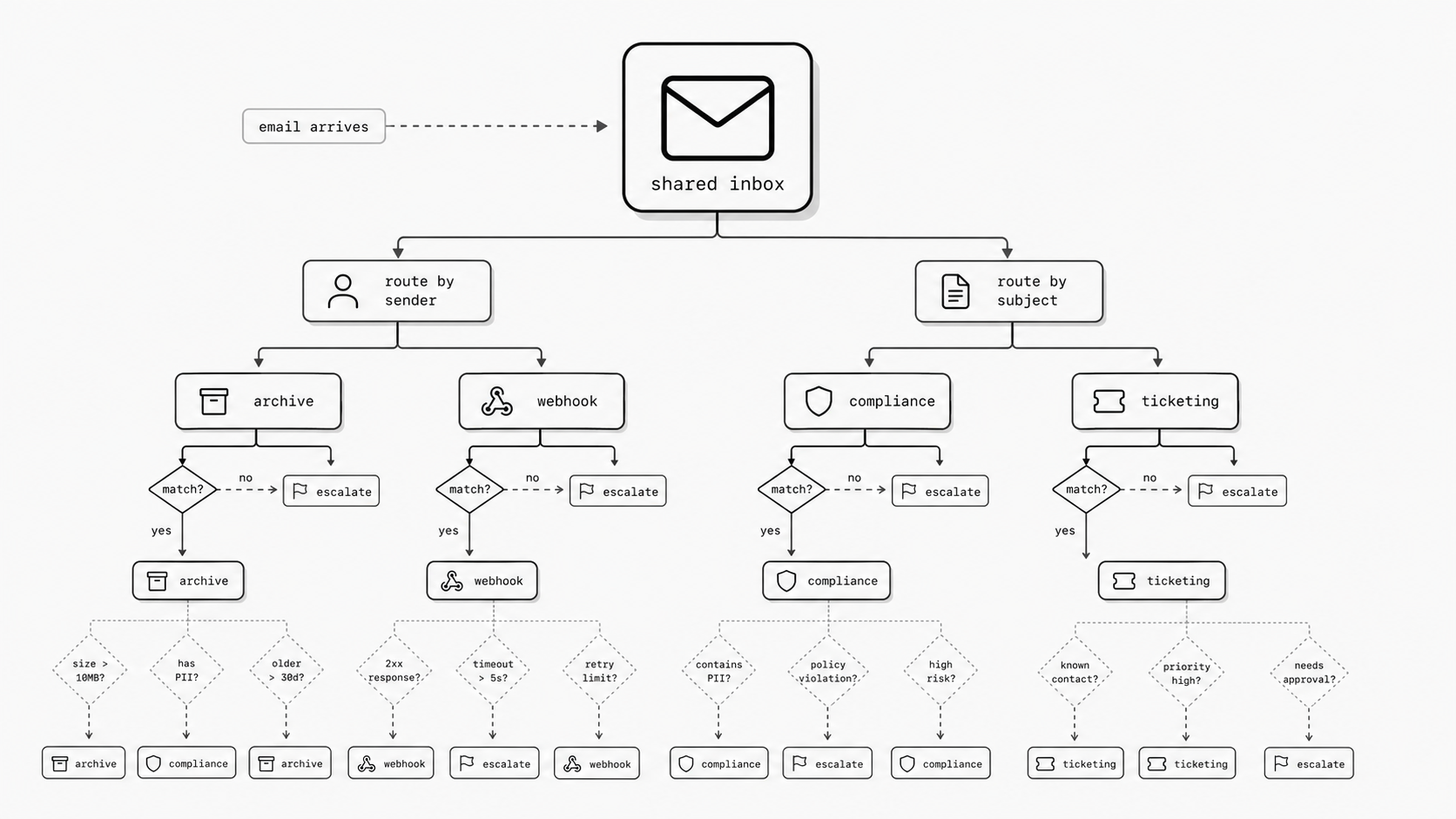
I have seen this pattern more than once: the inbox still looks simple from the outside, yet the real decision logic is spread across mailbox settings, forwarding rules, ticket automations, and custom handlers. Once that happens, nobody can review the full behavior in one pass. A team may believe it has “just a few rules,” while the actual flow depends on multiple systems, different rule orders, and uneven logging of what happened to each message. That is where operational confidence starts to drop. If an executive asks, “Why did this email go here, and can we prove it will do the same tomorrow?” the honest answer often becomes slower and less certain than it should be. (Google Workspace Admin Help - Set up routing for inbound email)
You might be wondering: is this really an architecture issue, or just cleanup work? I see it as architecture, because message handling only stays reliable when teams can inspect the full chain of matching, delivery, retries, and failures. If one rule lives in the mail provider, another in a help desk, another in an integration service, and another inside application code, no single owner can easily answer what the system will do for a given message. (Webhook Reliability Checklist)
That gap matters most when exceptions show up. A sender domain changes. A partner forwards from a new address. A ticketing workflow adds a new condition. An email webhook starts pushing messages into a downstream process that has its own retry behavior. Each local change may look safe on its own, yet the combined outcome becomes hard to predict without a shared view of the rules and outcomes. (Microsoft Learn - Exchange mail flow rules in Exchange Online)
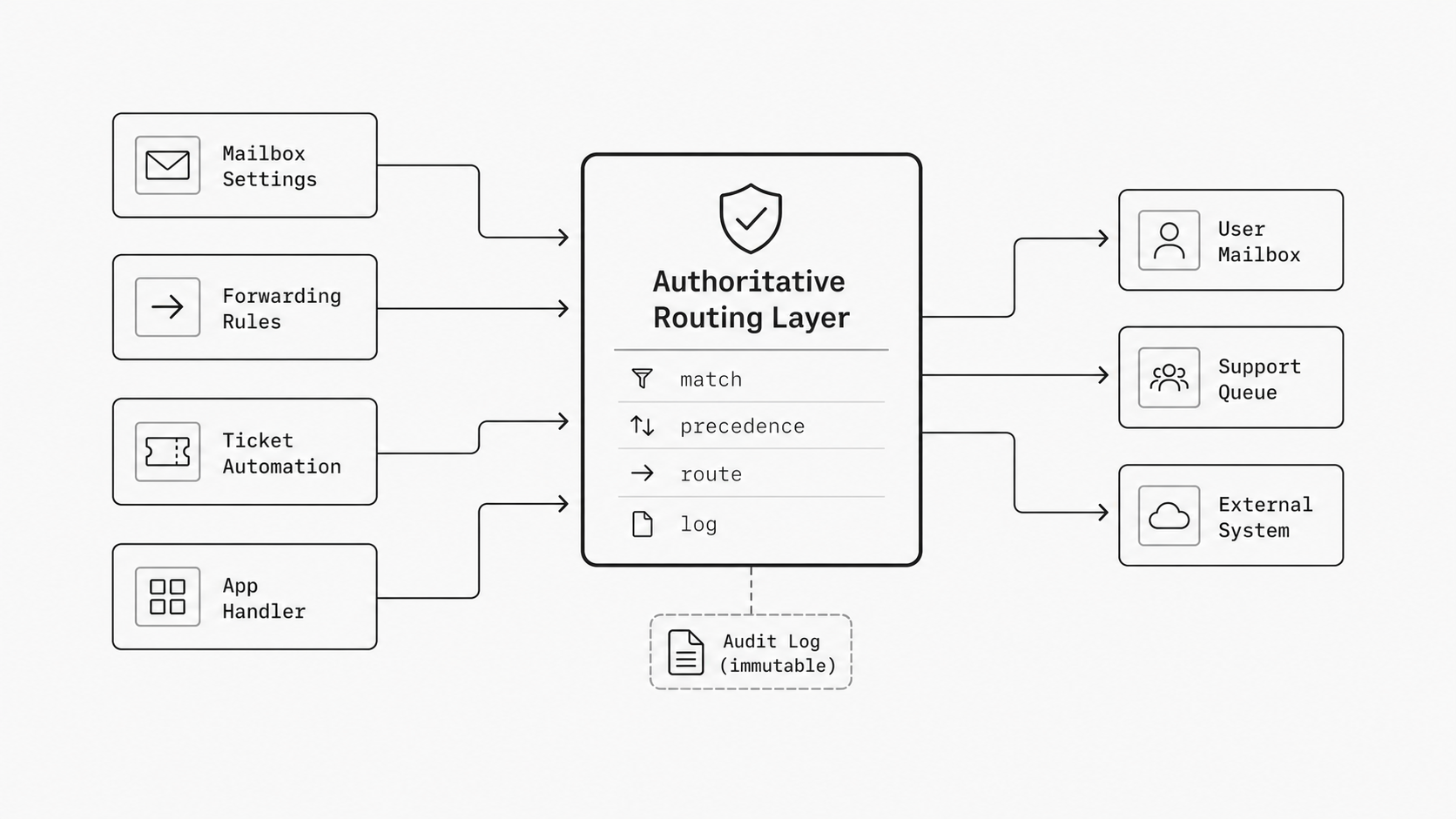
This is why I push teams toward one reviewable decision layer. I do not mean every system has to disappear. I mean the logic for conditional email routing should be defined in one authoritative place, with clear precedence, expected destinations, and observable results. When a team adopts an email routing rules API or a similar control layer, it becomes much easier to see which conditions exist, which route wins, and what changed over time.
That central view also improves operations. Reliable event-driven handling benefits from validation, deduplication, replay paths, and logging because those controls help teams recover from delivery failures and understand processing outcomes. The same principle applies here. If you process inbound email programmatically, visibility is part of the design, not an extra feature added later.
In practical terms, I would want any team to answer four questions quickly: what matched, why it matched, where it went, and what happened next. If those answers require opening four admin consoles and asking three different owners, the logic is already too scattered to govern well.
The payoff from centralizing decision logic is not only cleaner administration. It is faster review, safer change control, and a much stronger operational story when volume grows. Leaders do not need perfect simplicity. They need one dependable place to understand and govern how messages are handled. When the rules are explicit, teams can adapt without guessing, and email automation for developers becomes easier to scale into shared operations instead of turning into a hidden tangle of exceptions.
More destinations means you need rules about the rules
I have watched teams cross an invisible line with inbound mail. At first, one shared address sends messages to a person, a queue, and maybe one automation. Then a second system gets added, then a compliance copy, then an email webhook for a downstream process, and suddenly the real risk is no longer simple delivery. The risk is overlap. The same message can be retried, forwarded, copied, or processed by more than one destination unless someone defines who is allowed to act, who is only allowed to observe, and what should happen when delivery partially fails. That is the moment I stop thinking only about routing and start thinking about governance. (Courier Docs - Delivery Reliability and Retries)
You might be wondering: why does this get hard so fast? Because once one message can land in several places, each destination can have its own delivery behavior, retry pattern, and failure state. One system may accept immediately. Another may retry later. A third may process the same payload again after a timeout or replay event unless deduplication and validation are built in. On paper, every route still looks reasonable. In operations, the combined behavior can become messy very quickly. (Webhook Reliability Checklist)
This is where leaders need rules about the rules. I mean explicit decisions such as: which destination is authoritative, which copies are informational, which routes may trigger actions, how replay is handled, and who approves a new branch before it is attached to the same inbound source. Without that layer, teams keep adding useful local automations while the shared inbox becomes a multi-system control point with no clear operating model.
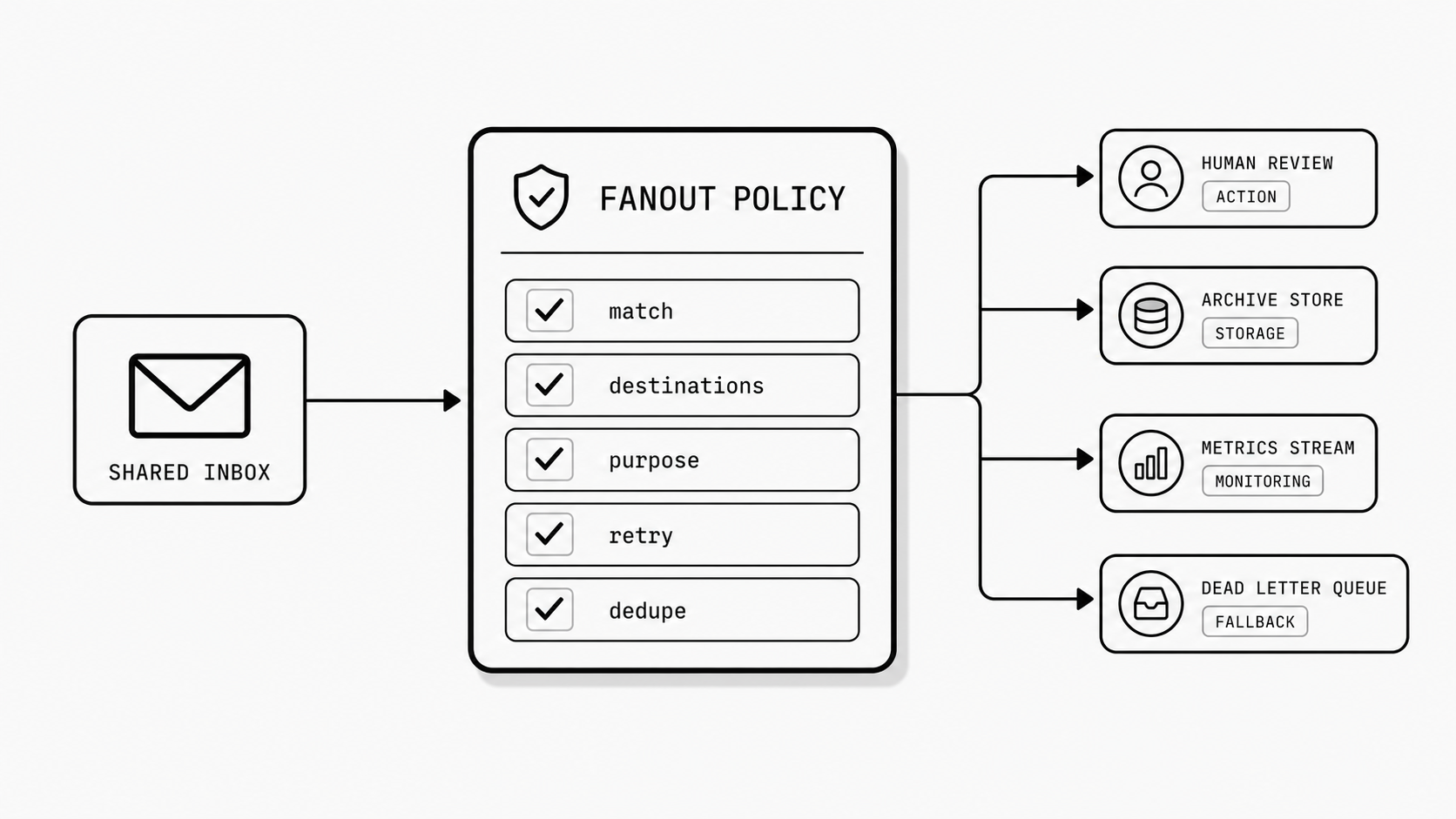
I have found that governance gets much easier when the routing design names message intent up front. Some destinations are for action. Some are for storage. Some are for monitoring. Some exist only as fallback. If those roles are not written down, people assume every recipient or endpoint can act on the message, and that is where duplicates, race conditions, and conflicting records start to appear. Even a well-designed email routing rules API can become hard to trust if teams use it only to add conditions and never define destination responsibilities.
So what does this look like in practice? I would want one simple policy view for every inbound route: the match condition, the approved destinations, the purpose of each destination, the retry expectation, and the deduplication key or replay rule if programmatic processing is involved. That gives platform engineers and ops architects a way to review fanout as a governed system instead of a growing set of independent conveniences.
The important shift is mental. Once one inbound stream feeds many systems, you are no longer managing only message transport. You are governing shared operational consequences.
The payoff is straightforward. Governance keeps one inbound source from creating multiple competing versions of “done.” Retry behavior becomes easier to reason about, duplicate processing risk drops, and new destinations can be added with clearer ownership and less surprise. If the inbox already fans out to several tools, I would treat that flow like production infrastructure now. The earlier you define who can receive, who can act, and how retries and replays are controlled, the easier it is to scale without hidden conflict.
The first successful automation is often what makes the next five risky
One small automation can feel harmless, but once teams add exceptions, retries, backups, and audit copies, a simple inbox flow starts behaving like an operational system with branching logic and failure handling. (Contentstack Docs - Webhook Retry Policy)
Complexity creep in seemingly simple flows happens when a basic message path becomes harder to operate after a few useful automations are added. Once a team trusts one inbound email or webhook flow, it is natural to layer more business cases onto the same path instead of building a new intake route. That is the point where simple forwarding begins to act like production middleware: teams must think about timeouts, retries, duplicate delivery, and what happens when one branch succeeds while another fails. Published webhook retry guidance commonly uses exponential backoff, which shows that delivery is an operational problem rather than a one-time handoff.
Use the first successful automation as the moment to add design discipline. Define retry behavior, duplicate-handling rules, route ownership, and change review before more exceptions accumulate, because repeated delivery and retries create operational responsibilities that simple flows rarely reveal at first.
The pattern here is consistent: one mailbox becomes many routes long before most teams name it as an architectural concern. Each added rule seems reasonable in isolation, but together they create a system with precedence, side effects, retries, and ownership gaps that are difficult to manage informally.
That is why I think leaders should respond early, not after a visible incident. If one inbound stream already feeds several destinations, it deserves an explicit decision layer, a governed fanout model, and clear operational expectations around retries, replay, and duplicate processing. The goal is not to eliminate flexibility. It is to make growth reviewable.
Email automation works best when teams recognize that the first successful rule is usually the start of a larger routing surface, not the end of a simple task. If you design for that reality early, you can keep one familiar inbox from turning into a quiet source of operational risk.