Technical teams rarely ask for custom scripting because they want more systems to govern. They ask for it because real-world input is messy, and simple field-to-field mapping stops short of what production workflows actually need. That tension shows up clearly in inbound email parsing. Leaders want the flexibility to normalize sender variations, extract values from inconsistent message formats, and preserve a stable email JSON schema. At the same time, they do not want to create a second application layer hidden inside transformation logic.
The previous post in this JSON series, Custom Webhook Payload Mapping for Email: Shaping Data for Your Application, showed what custom mapping looks like in practice. This post explains the rule model underneath that flexibility. For the default payload contract those custom mappings build on, start with Webhook JSON Payload Structure: Why a Stable Contract Is the Right Default.
That is why JSONLogic-style mapping models are so interesting. They offer a middle path between rigid mappings and open-ended code by expressing transformation behavior as structured rules. In this post, I unpack how that model works at a practical level: why structured mappings are easier to review than one-off scripts, how operator-based evaluation gives them real expressive power, where product-specific helpers can extend the model without collapsing into a general runtime, and why that matters for governance. The technical details matter, but so does the operating model around them. The goal is not just more flexible parsing. It is flexibility that remains legible, bounded, and supportable as the system grows.
Why I prefer structured mapping rules over one-off transformation code
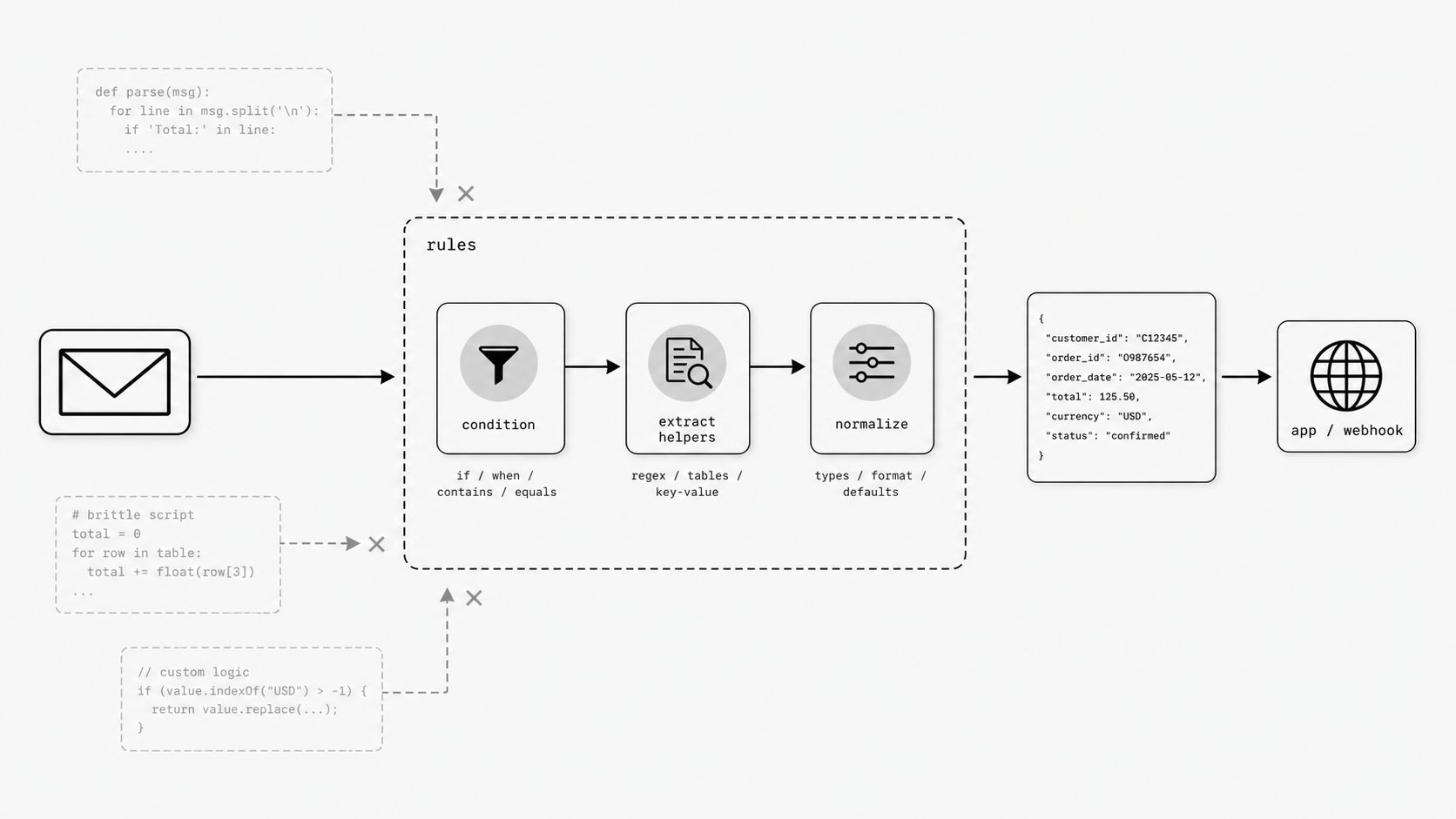
I have learned to be careful when a team says, “we just need a small script.” Small scripts have a way of becoming permanent architecture. In transformation-heavy systems like an email parsing API, that usually starts with one exception, then another, then a growing pile of one-off logic that only two people feel safe touching. A structured rule model changes the conversation because the transformation stops living inside scattered code and starts living inside a visible definition the team can inspect. (JSON Logic Operations)
That distinction matters more than it sounds. When I use declarative mapping logic, I am asking the system to describe intent as data. The rule says what should happen to an input, under what condition, and where the output should go. JSON Logic is a useful reference point here because it represents rules as JSON and supports conditionals, comparisons, array handling, and string operations in a structured form. That is powerful for technical leaders because the mapping becomes easier to review in the same way we review a payload, a schema, or a policy. You do not need to read through custom control flow to understand the business meaning.
This is also why I see these mappings as closer to a focused language than to application code. Martin Fowler describes a domain-specific language as something aimed at a particular problem area rather than an entire program. That framing helps executives and staff engineers meet in the middle. The executive sees a bounded way to express change. The engineer sees a model with clear limits, repeatable behavior, and fewer hidden side effects. (Domain-Specific Languages - Martin Fowler)
In practice, this becomes especially valuable when teams need to maintain a stable email JSON schema across many message shapes. If every new sender format requires a fresh script, the operating model gets fragile fast. If the team can update structured mapping rules instead, they can adapt field extraction and output shaping while keeping the contract visible and easier to reason about. You might be wondering: does that reduce flexibility? In my experience, it changes the kind of flexibility you allow. Instead of open-ended programming freedom, you get controlled expressiveness inside a format the platform can validate, version, and review.
That is why I prefer structured mapping rules over one-off transformation code. They give me a cleaner control surface. I can ask better governance questions: What inputs are expected? Which conditions are supported? Which output fields are guaranteed? Those questions are much easier to answer when the logic is expressed as structured data instead of buried inside custom scripts. For teams building inbound email parsing workflows, that difference compounds over time. The immediate gain is readability. The longer-term gain is organizational memory. The mapping can outlast the person who first wrote it, which is usually the real test of whether a transformation approach will scale.
How operator-based evaluation gives mappings real expressive power
Here is where many mapping systems either become truly useful or quietly hit a wall. A nice visual mapping layer can move fields from left to right, but real data rarely arrives that cleanly. In an email parsing API, one sender may put an order number in the subject, another may bury it in the body, and a third may include it only when a status changes. If the mapping layer cannot evaluate conditions, compare values, inspect arrays, and work with strings, it stops being a transformation system and becomes a fragile copier. That is why I pay close attention to the operator model. The expressive power does not come from letting people write arbitrary code. It comes from giving them a controlled vocabulary that can still answer real-world questions inside the mapping itself.
So what does that controlled vocabulary actually buy us? Quite a lot. JSON Logic is a useful reference because it shows how a structured rule system can support branching, comparison, array processing, and string-oriented evaluation inside a JSON rule format. In practice, that means I can define behavior such as: if the sender domain matches a partner, extract one set of fields; if the message has multiple line items, map them as a collection; if a value is missing, fall back to another field; if text contains a marker, route it differently. That is the difference between a static field map and a system that can support a stable email JSON schema across messy inbound variation.
A small MailWebhook Custom JSON mapper makes that concrete. The Custom JSON mapper uses a JsonLogic-style DSL inside the final map.custom_json step. The following block is real mapper syntax, using the same args format you would put inside a route configuration. It can express a sender-domain decision and still emit a simple field for the receiving app:
{
"version": "v1",
"vars": [
{
"name": "sender",
"expr": {
"string.lower": { "var": "message.from[0].email" }
}
},
{
"name": "sender_domain",
"expr": {
"regex.replace": {
"value": { "var": "vars.sender" },
"pattern": "^.*@([^>\\s]+)$",
"with": "\\1"
}
}
},
{
"name": "kv",
"expr": {
"call.extract.key_value_pairs": {
"mode": "auto"
}
}
}
],
"output": {
"sender_domain": { "var": "vars.sender_domain" },
"external_reference": {
"if": [
{ "==": [{ "var": "vars.sender_domain" }, "vendor.example"] },
{ "var": "vars.kv.values.vendor_reference" },
{ "var": "vars.kv.values.order_id" }
]
}
}
}
Read from top to bottom, the mapper lowercases the sender, derives sender_domain, extracts key/value fields from the message, and chooses the trusted vendor field only for vendor.example. Other senders fall back to the normal order_id field. The downstream system receives one external_reference field, while the rule stays visible as data.
You might be wondering: does a fixed operator set really go far enough? In my experience, yes - when the operators are chosen well. A team usually needs a practical mix of conditional evaluation, equality and ordering checks, collection handling, and basic string work to cover a large share of production transformation cases. That is enough to power common patterns in an email to JSON API, including sender-based branching, fallback extraction, normalization, and conditional output shaping. The key is that each mapping remains legible. I can review the rule and see the decision path without tracing through open-ended script behavior.
There is also an engineering payoff here that leaders should not miss. A fixed operator vocabulary creates more predictable execution than custom scripting because the platform knows in advance which actions may occur during evaluation. That predictability supports downstream stability, especially when other systems depend on structured email JSON output or on a deterministic payload contract. At the same time, teams should stay aware that implementations can differ in details such as truthiness behavior and iterator context, which is one reason platform consistency matters when you operationalize these mappings at scale. (json-logic-js GitHub Repository)
The real insight is simple: operator-based evaluation gives mappings enough intelligence to handle variation without turning the platform into a general scripting environment. For technical executives, that means flexibility with fewer surprises in delivery and support. For staff engineers, it means the transformation layer can express meaningful logic while still staying inspectable, testable, and bounded by the platform’s rule model. When I see this done well, the result is not just cleaner mappings. It is a more reliable operating model for conditional email routing, stable payload generation, and long-term maintainability in systems that have to absorb constant input variability.
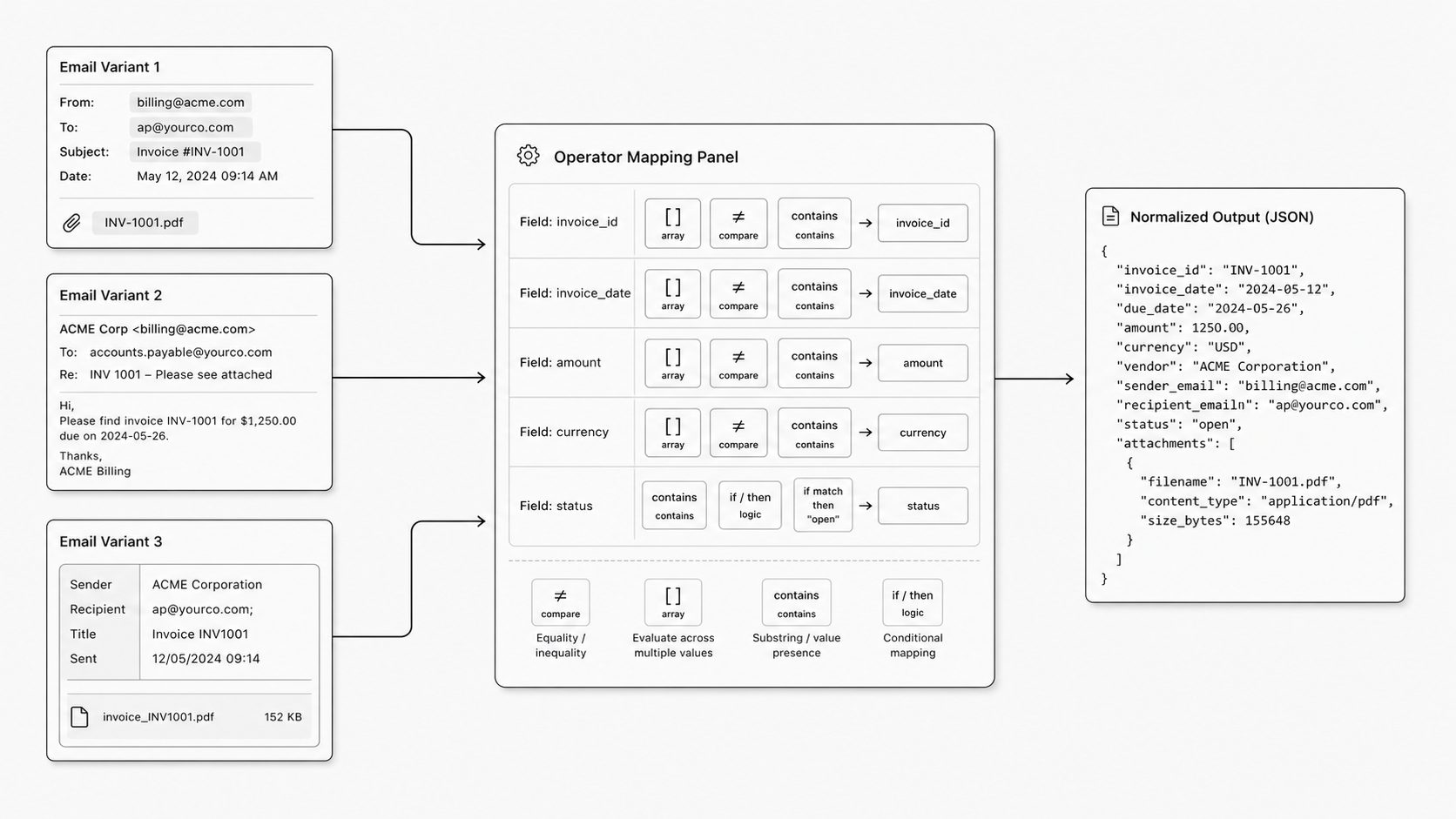
Where product-specific helpers extend the rule model without breaking it
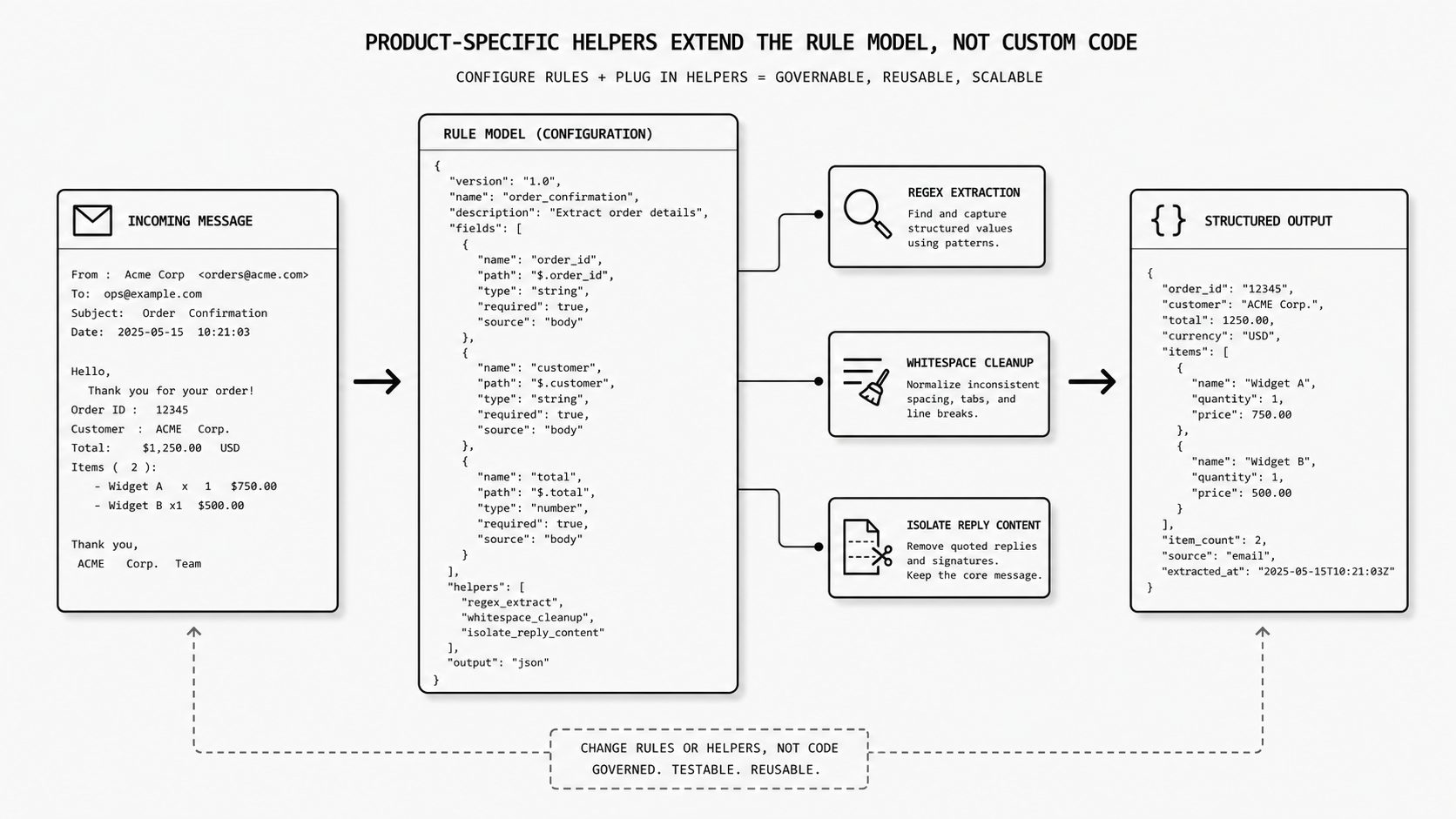
This is the point where many teams get nervous. They accept a rule model for basic mapping, then the real-world edge cases show up. Now the inbound message has inconsistent spacing, the field label shifts, the body includes extra signatures, or the value you need lives inside a block of messy text. That is usually when someone says, “fine, we need custom code.” I think that is the wrong turning point. A well-designed system can grow by adding targeted helpers for domain work like extraction, cleanup, and pattern matching while still keeping the rule model intact.
Here is how I think about it. The base rule engine gives you the general structure for evaluation. JSON Logic is a useful reference because its operation set already includes string-oriented capabilities, which shows that structured rules do not have to stop at simple field copying. But domain-heavy products often need more than that. An email parsing API, for example, may need built-in support for regex-style extraction, message body cleanup, header-aware selection, or pulling a value from a repeated text pattern. Those are not random conveniences. They reflect the actual shape of the problem the product is trying to solve.
Reply isolation is a good example because quoted history is a recurring email problem. Given message.text like this:
Looks good to me.
On June 12, 2026, Ada wrote:
> Please confirm the contract update.
The helper call can sit inside vars:
{
"name": "reply_segments",
"expr": {
"call.extract.reply_segments": {
"sources": ["text"],
"split_quoted_by_depth": true
}
}
}
Then the final output can expose only the fields the receiver needs:
{
"reply_text": { "var": "vars.reply_segments.text.reply_content" },
"has_quoted_content": { "var": "vars.reply_segments.text.has_quoted_content" }
}
That can emit a compact payload fragment:
{
"reply_text": "Looks good to me.",
"has_quoted_content": true
}
The caller invokes one named helper with bounded arguments and reads documented result fields. The parsing behavior stays inside the product boundary, and the mapping still looks like configuration a reviewer can follow.
That design choice matters because it changes how flexibility is added. Instead of opening a full scripting surface, the product extends the same rule language with a few carefully scoped capabilities. I still review a mapping as a structured definition. I still know the platform is evaluating a known set of behaviors. I still have a better chance of preserving a stable email JSON schema even when incoming messages vary by sender, layout, and formatting.
You might be wondering: when do helpers feel legitimate, and when do they start to feel like hidden code? My test is simple. If the helper captures a repeatable domain task in a way that stays readable to the team, it strengthens the model. If it introduces open-ended behavior that only a specialist can reason about, it weakens it. That connects back to Fowler’s domain-specific language framing: a language should fit a particular problem area. (Domain-Specific Languages - Martin Fowler) That is exactly why product helper enrichment can be so effective. The rule system stays small in concept, but more capable in the places where users actually struggle.
In practice, this is what helps an email to JSON API stay governable at scale. One helper might normalize whitespace before extraction. Another might isolate the latest reply content. Another might apply a pattern to pull an order ID from semi-structured text. The mapping becomes more expressive, but it does not turn into an anything-goes programming layer. For executives, that means change stays inside a reviewable surface. For staff engineers, it means the transformation layer can absorb domain mess without creating a second application stack to maintain.
The payoff is bigger than convenience. Product-specific helpers let the platform meet messy reality without abandoning the discipline of a rule model. That is the sweet spot I look for - enough built-in enrichment to handle extraction and cleanup work that shows up every day, with clear limits that keep behavior inspectable. When that balance is right, the team gets practical adaptability, and leadership gets a system that can evolve without quietly becoming another custom-code estate.
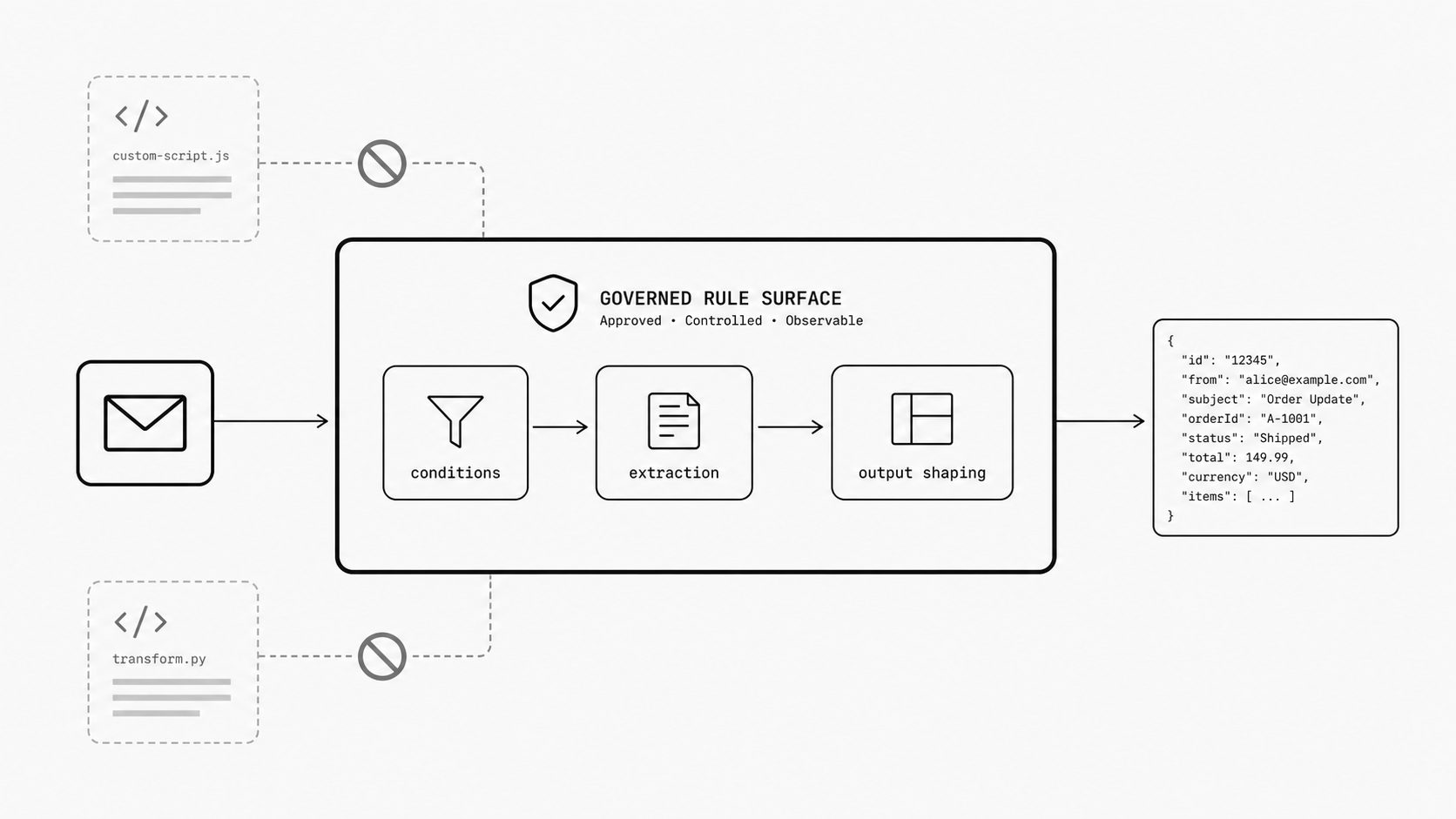
How I think about governance when leaders want flexibility without script sprawl
When leaders ask for more flexibility, the hidden second request is usually for speed that still stays reviewable months later. Platforms often drift when one edge case at a time pushes teams from a bounded rule model into a broader scripting surface that is harder to inspect, secure, and hand off across teams. (Bounded Context - Martin Fowler)
Good governance starts by naming the boundary. Fowler’s bounded context framing is useful here because it treats a model and its language as belonging to a defined problem area. For email transformation, that context is narrow: read the normalized message, metadata, and prior variables; evaluate approved operators; call approved email-specific helpers; emit JSON.
That turns governance into a practical review question: can the next requirement fit inside the approved rule surface, or does it require a new execution primitive?
If the request says, “use vendor_reference for vendor.example and otherwise use order_id,” the model has what it needs. It can read the sender, normalize a domain, compare values, and choose an output field. If the request says, “strip quoted replies before writing ticket.body,” a named helper can cover that domain task. Both changes stay inside the same language, which means reviewers can inspect the rule, test example messages, and understand the emitted JSON without learning a new runtime.
A different class of request deserves more scrutiny: “run arbitrary JavaScript to compute a field,” “call a private CRM during mapping,” or “install a sender-specific library.” Those are new primitives. They change the runtime contract because the platform now has to govern credentials, network access, timeouts, side effects, retries, and logs around behavior that no longer looks like a data rule. The team may still support the business need. Treat it as a product or architecture decision instead of a quick mapping edit.
That is the governance payoff of a JSONLogic-style model. It gives engineers a tractable control surface and gives leaders a review vocabulary they can explain: which inputs are readable, which operators are allowed, which helpers exist, and which outputs are promised. For the next inbound parsing or routing request, ask whether the behavior fits the approved rule model before opening a new pocket of custom runtime logic. That keeps extensions legible, bounded, and easier to own over time.
The core idea is straightforward: you do not need to choose between brittle mappings and unrestricted scripting. A well-designed JSONLogic-style rule model can carry a surprising amount of transformation work when it combines structured definitions, a capable operator vocabulary, and narrowly scoped domain helpers. That gives teams enough expressive power to handle variation in inbound email without making every edge case a new code path.
For technical executives, the value is governance with usable flexibility. For staff engineers, the value is a transformation layer that stays inspectable, testable, and operationally predictable. If you are evaluating how an email parsing API should evolve, this is the architectural question I would keep in focus: can the next requirement fit inside a bounded rule surface, or are you about to create another scripting environment to secure, debug, and own indefinitely? The better answer is usually the one that keeps change visible as data rather than dispersing business logic across custom code.