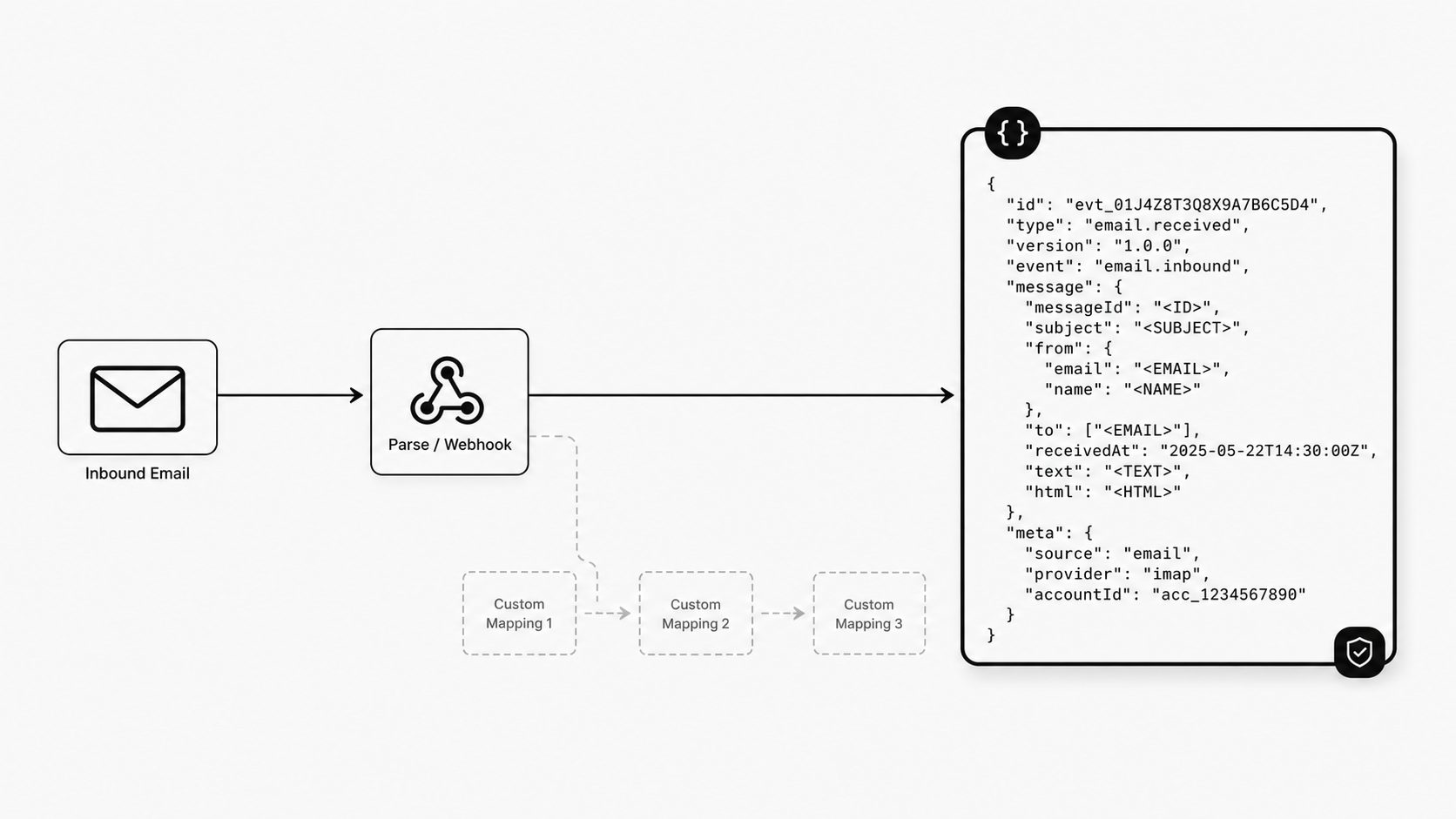
Inbound email starts messy. Headers vary, bodies vary, attachments vary, and edge cases arrive earlier than most teams expect. That is exactly why I prefer a stable JSON contract as the starting point for integration design. Before a team adds custom transformation rules, it needs a machine-friendly shape that downstream systems can trust, validate, monitor, and replay without guesswork.
This matters now because many buyers assume flexibility is the main requirement on day one. I think the bigger requirement is dependability. For backend engineers and platform architects, the safest path is usually to establish one stable payload model first, make its identity and version explicit, keep its parts clearly separated, and only then add customization where real evidence justifies it. That default posture lowers integration risk and gives every consumer a calmer foundation to build on.
What the generic payload looks like
Here is a compact example based on MailWebhook’s built-in generic schema. The field names matter because this is the stable contract downstream systems can build against: schema identifies the contract, event describes the occurrence, message holds message-level facts, and body plus meta carry content and operational context.
{
"schema": {
"name": "mailwebhook.generic",
"version": "1"
},
"event": {
"id": "abaa87a3-e2a6-4d23-9d49-e8113933714a",
"project_id": "dca29061-c4a7-4687-a8dd-24d2f26548c7",
"route_id": "aec0b8cc-b524-48c5-b7ef-763b8dc8271f",
"created_at": "2026-06-05T10:04:42Z"
},
"message": {
"message_id": "0100019e62e45e38-example@email.example",
"message_id_type": "original",
"subject": "Invoice INV-1048 for May services",
"date": "2026-06-05T09:42:18Z",
"from": [
{
"name": "Acme Supplies",
"email": "billing@acme.example"
}
],
"to": [
{
"email": "invoices@example.com"
}
],
"headers": {
"message-id": "<0100019e62e45e38-example@email.example>",
"subject": "Invoice INV-1048 for May services",
"from": "Acme Supplies <billing@acme.example>",
"to": "invoices@example.com",
"content-type": "multipart/mixed"
}
},
"body": {
"attachments": [
{
"filename": "invoice-inv-1048.pdf",
"content_type": "application/pdf",
"size_bytes": 184233
}
],
"text": "Please find invoice INV-1048 attached for May services.",
"html": "<p>Please find invoice <strong>INV-1048</strong> attached for May services.</p>"
},
"meta": {
"source": "imap",
"raw_size_bytes": 9899,
"received_at": "2026-06-05T09:42:20Z"
}
}
That four-part shape is the point of the generic contract. A consumer can validate the schema before it reads the message, route or replay from event facts, process message-level fields from message, and read content plus attachments from body without mixing those concerns together.
Why I start with one stable shape
When I look at an email parsing API, I do not start by asking how flexible the mapping can become. I start by asking a simpler question: can every downstream system trust the shape on day one? That sounds small, yet it decides whether the integration feels calm or fragile six months later. In practice, teams often begin with one stable envelope that always carries the same top-level signals, because predictable metadata gives every consumer a reliable place to stand. AWS EventBridge, for example, documents a consistent event structure with fixed top-level metadata such as version, id, source, detail-type, time, and detail. (Amazon EventBridge event structure)
You might be wondering: why not jump straight to custom mapping if each buyer has unique needs? My answer is that uniqueness usually shows up later than people expect, while contract drift shows up earlier. A stable JSON contract is easier to validate, test, monitor, and hand off between services because the first parsing step produces a predictable shape. That matters even more in inbound email parsing, where source material is naturally messy. Subjects vary, headers vary, bodies vary, attachments vary. The more chaotic the input, the more value I get from a stable JSON payload structure on the output side.
I also start here because version-aware consumers are easier to operate than guess-heavy consumers. Stripe’s webhook versioning guidance explains that endpoint versions affect how objects are rendered and whether deserialization succeeds during upgrades. I take that as a practical lesson for any structured email JSON output: if downstream systems can identify the contract clearly and handle changes intentionally, upgrades become planned work instead of surprise breakage. (Stripe webhook versioning)
So what does this actually change for a backend engineer or platform architect? It changes the default decision. Instead of asking every consuming team to interpret a custom shape, I can give them one dependable envelope and let them focus on business logic. Parsers know where to look. Validators know what to expect. Monitoring can key off stable fields. Documentation gets shorter because the contract has fewer moving parts.
The payoff is simple: one stable shape lowers integration risk because every consumer can rely on predictable metadata and version-aware handling from the start. When I choose that path first, I make the system easier to adopt, easier to test, and easier to evolve within minutes of implementation planning.
How downstream systems know what they received
I have seen a simple integration fail for a very avoidable reason: the payload arrived, the data looked familiar, and the receiving system still had to guess what it had been handed. That guess is where fragile integrations begin. When I send a machine-friendly payload, I want the contract to introduce itself right away with explicit identity and version fields, because downstream services should not need to inspect body content, optional fields, or edge-case patterns just to understand the message type. In event-driven systems, this is already a proven habit. CloudEvents defines core context attributes such as id, source, type, and specversion, which gives consumers a direct way to classify and process an event before they touch the event data itself. (CloudEvents)
You might be wondering: does this really matter if the payload shape already looks consistent? I think it does, especially once more than one service, queue, or team is involved. A stable shape helps, but identity signaling tells every consumer how to interpret that shape. In a well-behaved email JSON schema, I want a downstream system to answer three questions immediately: what kind of payload is this, which contract version produced it, and what rules should I apply next. (Stripe API versioning)
That clarity changes everyday engineering work in useful ways. Reviewers can inspect logs and know what was emitted without opening the full payload. Replay tools can route old messages to the right parser because the contract identity travels with the event. Platform teams can support controlled evolution because a version value gives them an explicit boundary for compatibility decisions. Stripe’s API versioning guidance is a practical reminder here: version changes affect how objects are rendered, and Stripe recommends testing version upgrades before adoption because deserialization behavior can change across versions. I read that as a broader integration lesson. If version context changes behavior, version context belongs in the contract, where systems can reason about it clearly.
This also helps with governance without making the payload feel heavy. I do not need a giant taxonomy. I need a few direct signals that remove ambiguity. For a stable email webhook payload schema, that usually means a contract name or type, a contract version, and the event or message identifier that lets me trace the payload through logs and retries. Once those fields are present, consumers can validate faster, monitoring rules become easier to write, and documentation becomes easier to trust because the contract says what it is in plain terms instead of asking readers to infer meaning from examples.
Here is where teams often get into trouble: they postpone identity signaling because everyone still “knows” the payload. That works only while the system is small and the context is fresh in people’s heads. Over time, more consumers appear, replay needs grow, and old assumptions fade. At that point, explicit schema identity stops being a nice detail and starts acting like operational memory for the platform.
The payoff is calm downstream behavior. When the payload names itself and declares its version, consumers can parse, validate, route, and replay with less guesswork and less hidden coupling. That is why I treat schema identity signaling as part of dependable integration design, not as extra metadata. It gives every system a clean first step: understand what arrived, then process it with confidence. For teams that want a stable JSON contract email systems can live with over time, that first step is where reliability begins.
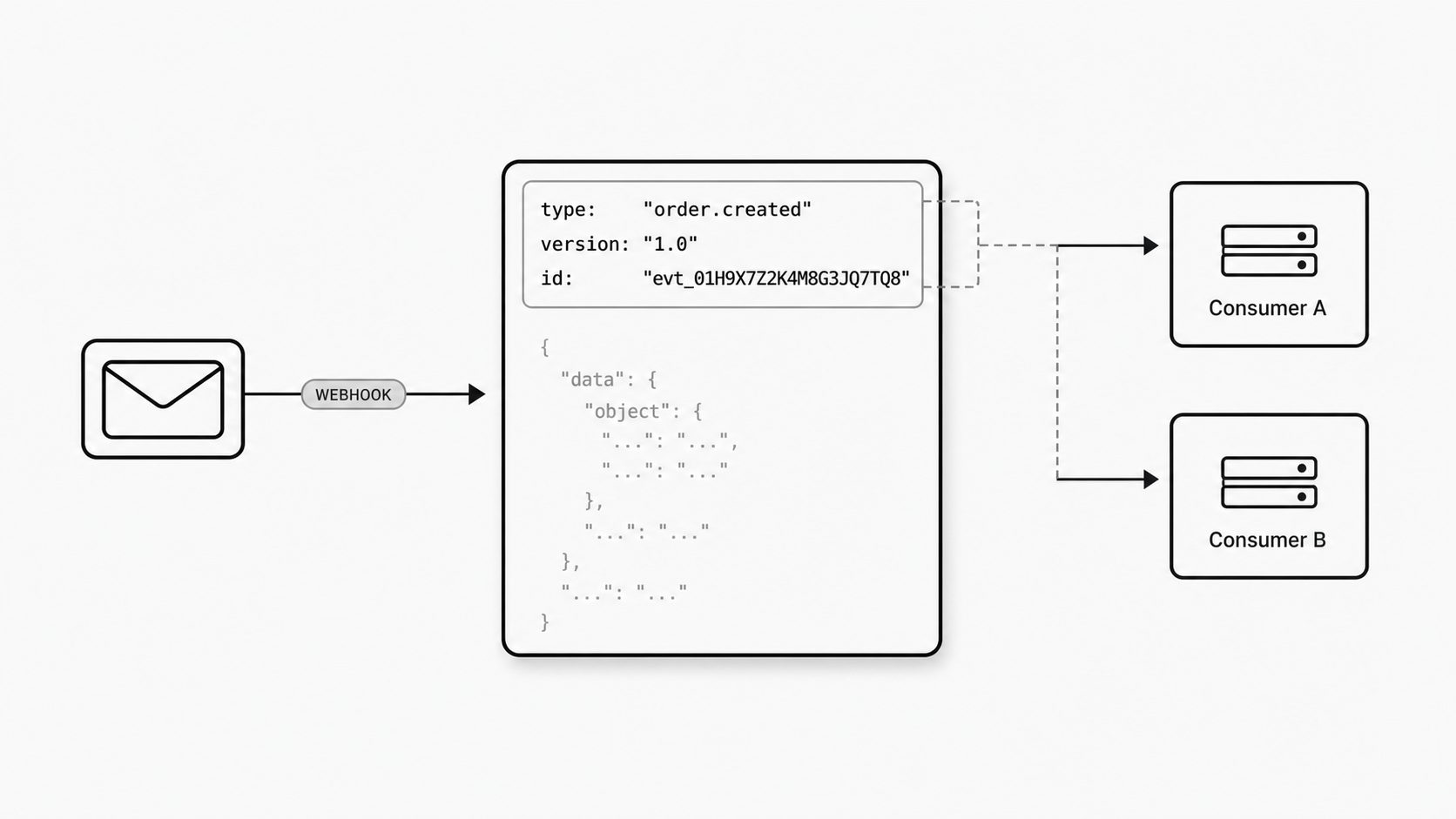
Why I separate event facts from message content
I learned this lesson the hard way: when an inbound email webhook puts everything into one flat blob, small questions turn into slow investigations. What triggered the event? Which fields describe the message itself? Which values are only there for transport or tracing? Those are different kinds of facts, and I want them to live in different places. AWS EventBridge models this clearly by keeping top-level event metadata separate from the domain payload inside detail, which gives consumers a clean boundary between routing information and business data. That same habit matters in an email JSON schema. When event facts and message content are separated, the contract becomes easier to inspect, easier to validate, and easier to trust over time. (Amazon EventBridge event structure)
You might be wondering: what does that separation actually look like in practice? I think of it as giving each layer one job. Event facts describe the occurrence itself, such as identifiers, timestamps, processing context, and contract-level metadata. Message content holds the email-specific material, such as sender, recipients, subject, headers, text body, HTML body, and attachments. A third area can hold supporting metadata that helps operations without changing the meaning of the message. This kind of boundary mirrors a broader machine-readable design principle: JSON Schema Draft 2020-12 is built around explicit schema structure and validation rules, which is exactly the mindset I want in a predictable email webhook payload schema. (JSON Schema Draft 2020-12)
Why does that matter for backend engineers and platform architects? Because boundaries reduce accidental coupling. If a downstream service only needs routing or replay data, it should not need to scan through message bodies to find it. If a content extraction service only needs the email body and headers, it should not have to sort through transport concerns first. Clear partitioning shortens those code paths and makes intent obvious during reviews.
I also like this approach because it improves validation discipline. A contract becomes easier to reason about when each section has a defined purpose and its own expected fields. That helps teams write validation rules that are more precise. It also helps them detect bad assumptions early. For example, if an engineer accidentally treats transport metadata as message content, the contract shape itself makes that mistake more visible.
There is an operational benefit too. Logs become easier to scan when event facts are grouped together. Debugging gets faster because I can inspect identifiers, timestamps, and processing context without opening the full message body first. In noisy inbound email parsing pipelines, that is a real advantage. The input is already messy enough. I do not want my structured email JSON output to add more ambiguity on the other side.
Here is the deeper point: separation creates a contract that stays readable for both machines and people. Machines get stable locations for validation and extraction. Humans get a payload they can scan without mentally re-sorting every field. That is a small design choice with long-term effects, especially when more services, alerts, and replay workflows start depending on the same payload.
The payoff is clarity under pressure. When I separate event facts from message content, I make the contract easier to inspect, safer to validate, and calmer to operate. That is why I treat partitioned structure as part of dependable integration design. In a stable JSON contract email systems can rely on, every field should have an obvious home and a clear reason to exist.
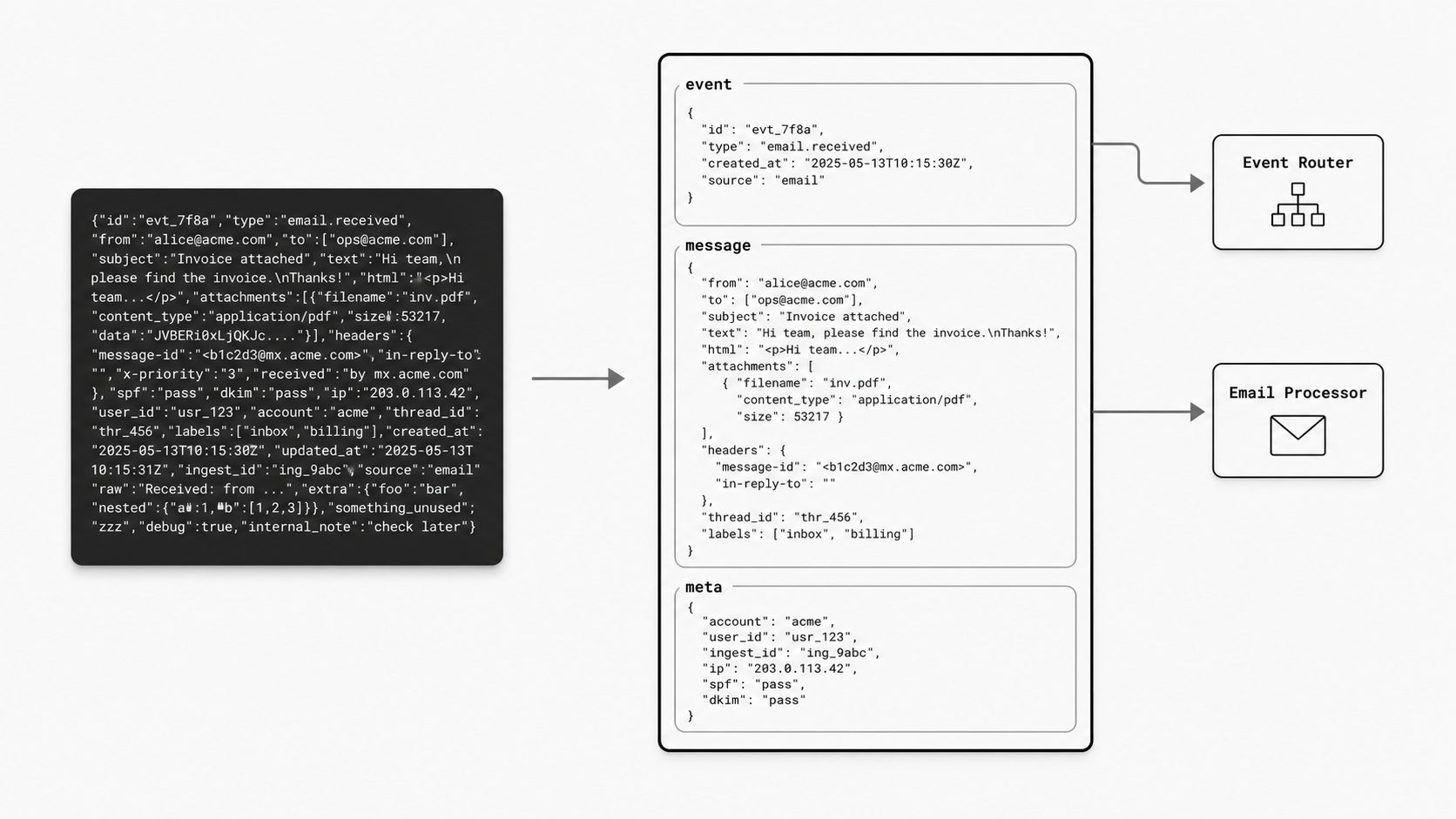
Why the default contract earns its place
The default contract earns its place because it gives every integration the same first move: receive a known shape, validate it, log it, replay it, and only then decide what the application should do with it. In my experience, the first risk in an integration is rarely a missing special rule. The first risk is losing a clear, testable payload shape before the team has learned how the data behaves in production. That matters even more in an email webhook flow, where source material is noisy and edge cases show up fast. GitHub’s webhook guidance puts real weight on delivery history and redelivery, which tells me dependable integrations need observable events and replay discipline from the start. Stripe’s webhook versioning guidance makes a similar point from another angle: safer change management comes from staged testing around version changes, not from assuming every consumer will absorb shape changes cleanly. (Viewing webhook deliveries - GitHub Docs)
You might be wondering: if teams eventually need specialized fields, why insist on the generic contract first? Because a stable contract gives me one place to observe failures, compare payloads, replay deliveries, and see which downstream needs are real. Until I have that visibility, extra output shapes can hide the signal I need most. Every branch creates another shape to test, another assumption to debug, and another migration path to own over time.
This is where many teams overestimate complexity. They picture a future with many consumers and assume the answer is immediate specialization. I take the opposite path. I start with a dependable email to JSON API contract that stays stable enough for logging, validation, and replay, then I watch where consumers actually struggle. GitHub documents both viewing deliveries and redelivering them, which is a practical reminder that troubleshooting improves when the original event remains visible and recoverable. If the default contract remains the source of truth, that recovery loop stays simpler because every consumer can refer back to the same event.
There is also a governance reason this default matters. Stripe describes webhook version upgrades as something to test in a controlled way, including support for trying a newer version before changing the endpoint behavior broadly. I read that as a useful operating model for any inbound parse webhook. Stable first, change second. Learn the contract in the open. Then introduce targeted variation where the value is proven. That sequence keeps the integration easier to reason about for backend engineers and platform architects who have to support it after launch.
So what makes the default contract strong enough to start with? Three things. It exposes the fields all consumers need first. It keeps failures replayable without translating them through local preferences. It separates true business meaning from formatting choices that only one consumer cares about. Once those basics are in place, later variation is smaller, clearer, and safer to add on top of a stable source contract.
The payoff is not slower delivery. The payoff is calmer delivery. By letting the default contract do the first job, I keep the integration observable, replayable, and easier to upgrade with intent. That gives teams a cleaner base for an email parsing API, and it helps them evolve the contract later with better evidence and less operational guesswork.
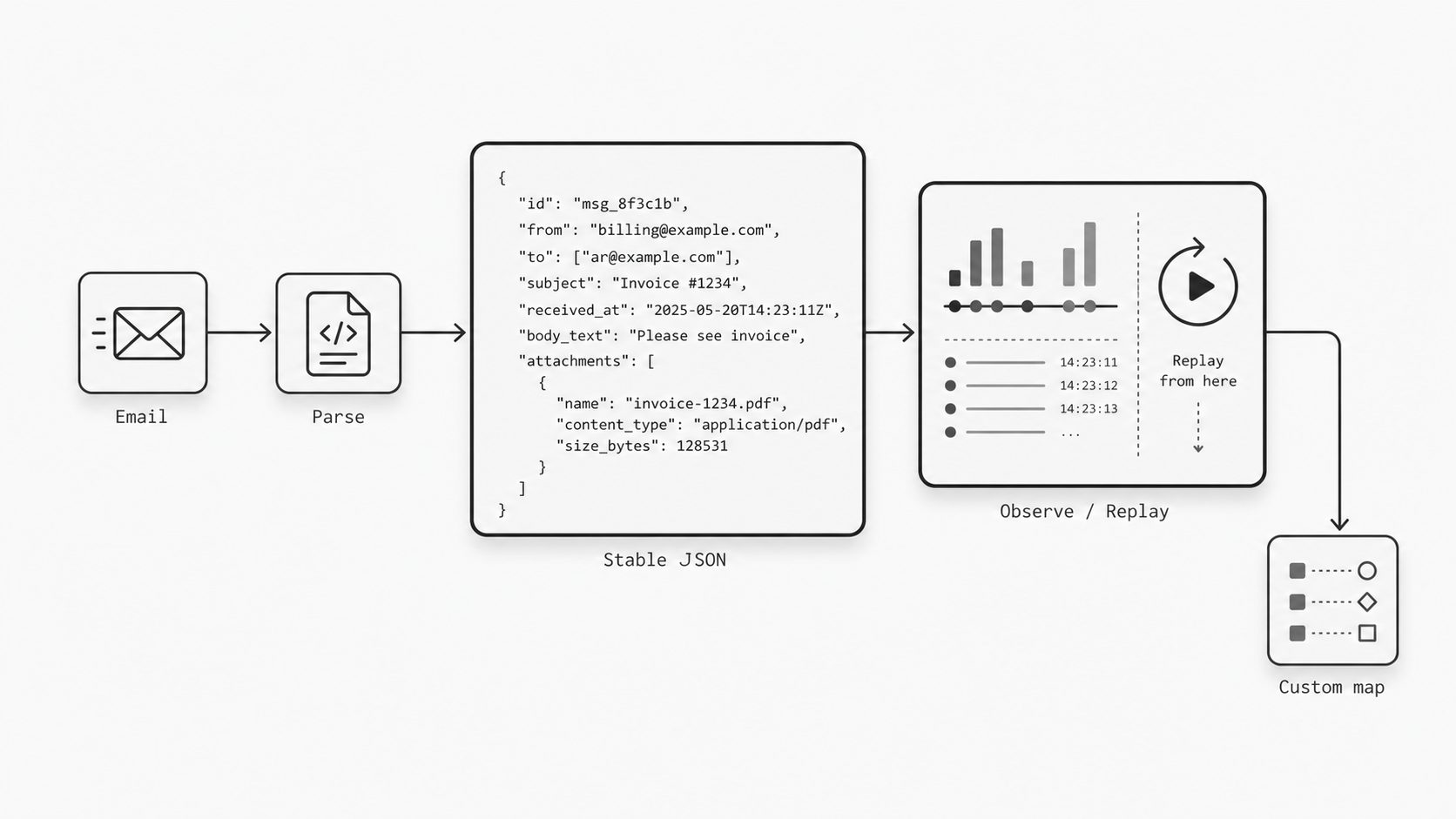
When I position a generic mapper as the cleanest default, I am not arguing against customization forever. I am arguing for sequence. First, give teams a stable source contract they can understand and operate with confidence. Then, once usage patterns are visible and downstream needs are proven, add transformation carefully and intentionally.
That approach is what makes inbound email integration feel dependable instead of fragile. A clear contract shape, explicit identity, readable separation of concerns, and a default-first mindset all push the system toward easier validation, easier replay, and safer change over time. For teams that care about reliable integration architecture, generic JSON is not the compromise option. It is the operationally strong starting point.