Custom webhook payload mapping matters when downstream systems need email data in their own exact language. As more technical teams connect inbound email to bespoke applications, the real question is no longer whether email can be parsed into JSON. It is whether that JSON can arrive ready for action, with the right field names, structure, derived values, and context already in place.
In this post, I explain the signals that make custom mapping the right next step. I look at why output logic should be built as an intentional sequence, how far a mapper should be allowed to reach for context, and what teams take on when they turn email output into a business-specific contract. The goal is simple: make the email handoff feel less like raw input and more like a dependable product surface.
If you are starting from scratch, begin with Webhook JSON Payload Structure: Why a Stable Contract Is the Right Default so the first handoff has a dependable baseline. For the broader system view, this topic fits inside the four-stage inbound email processing architecture: custom mapping is the transformation stage, after normalization and routing and before delivery.
Three signals that custom mapping is the right next step
Custom mapping earns its place when translation work becomes repeated, risky, or accountable. Those are the three signals I look for before shaping an email webhook payload around a receiving application.
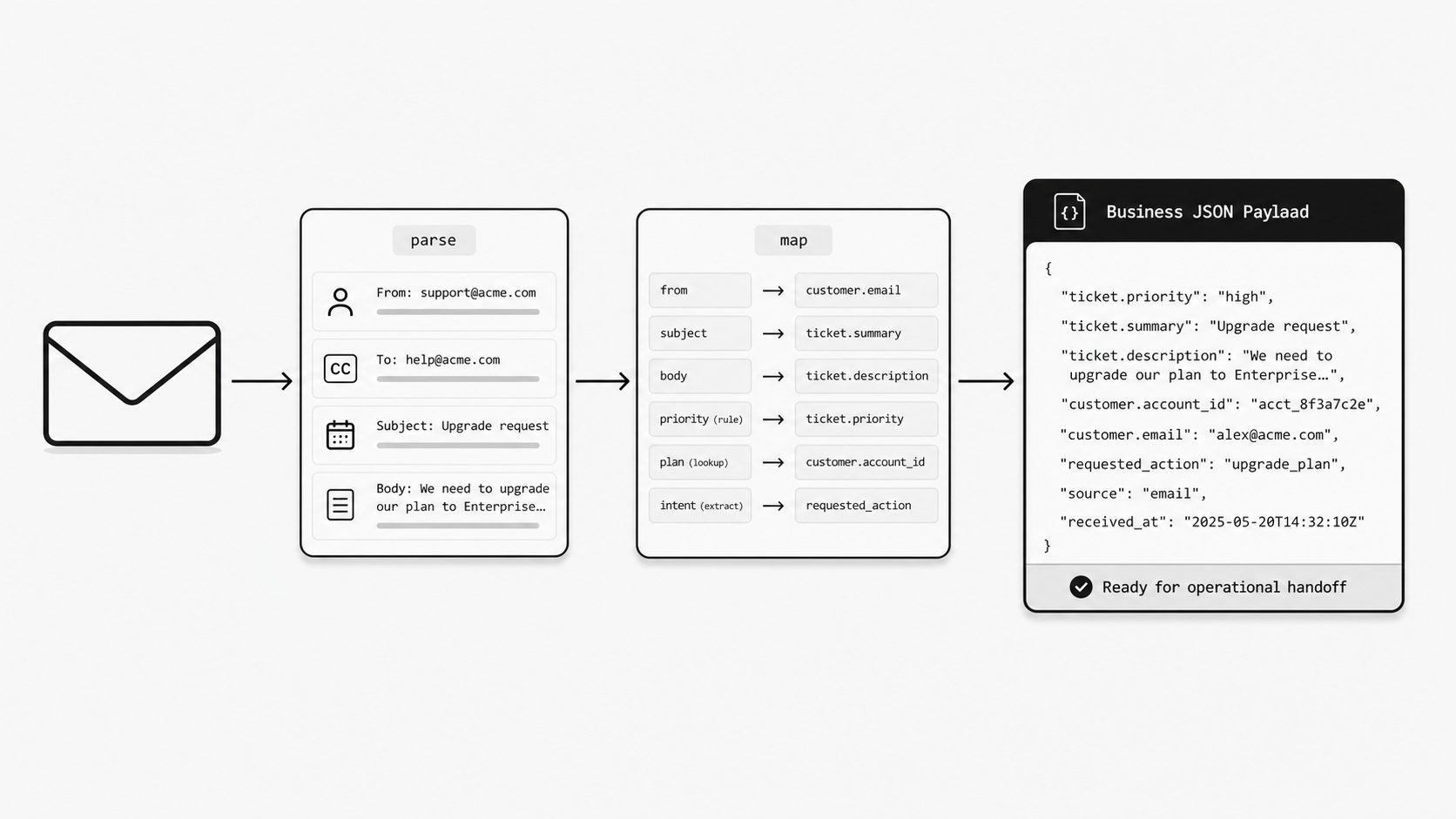
The first signal is repeat translation. If every consumer renames the same fields, splits the same values, reshapes the same arrays, or rechecks the same required data, the handoff is asking each downstream system to solve the same problem. That work belongs closer to the email webhook, where the mapping can be owned once and tested against real messages.
The second signal is workflow risk. When exact values trigger routing, approvals, record creation, or exception handling, loose structure becomes expensive. A support system may need ticket.priority. A claims workflow may need customer.account_id. An intake engine may need requested_action. If those fields arrive under different names, types, or nesting patterns, the receiving system has to guess at business meaning during production work.
The third signal is accountability. If a downstream team would open an incident when a field disappears, changes type, or lands late, the payload is already acting like a product surface. At that point, teams need a clear owner for field names, required values, validation behavior, and version changes. Custom mapping makes that ownership explicit because the output is designed around the business handoff and maintained as a shared interface.
Once those signals show up, business-shaped payload design becomes the better choice. I am talking about output that mirrors the destination model closely enough that the receiving application can treat the payload as ready for action. If a service desk wants ticket.priority, customer.account_id, and requested_action, then sending meta.priorityLabel, sender, and a free-form body summary may still be operationally noisy. The integration keeps forcing the destination team to translate one vocabulary into another.
The practical test is simple: if the destination team still has to explain what each field “really means,” the handoff still needs shaping around the business workflow. When custom webhook payload mapping reflects business intent directly, the receiving system gets data it can use with less code, less guesswork, and clearer ownership.
Here is where custom output starts to feel like a system, not a template
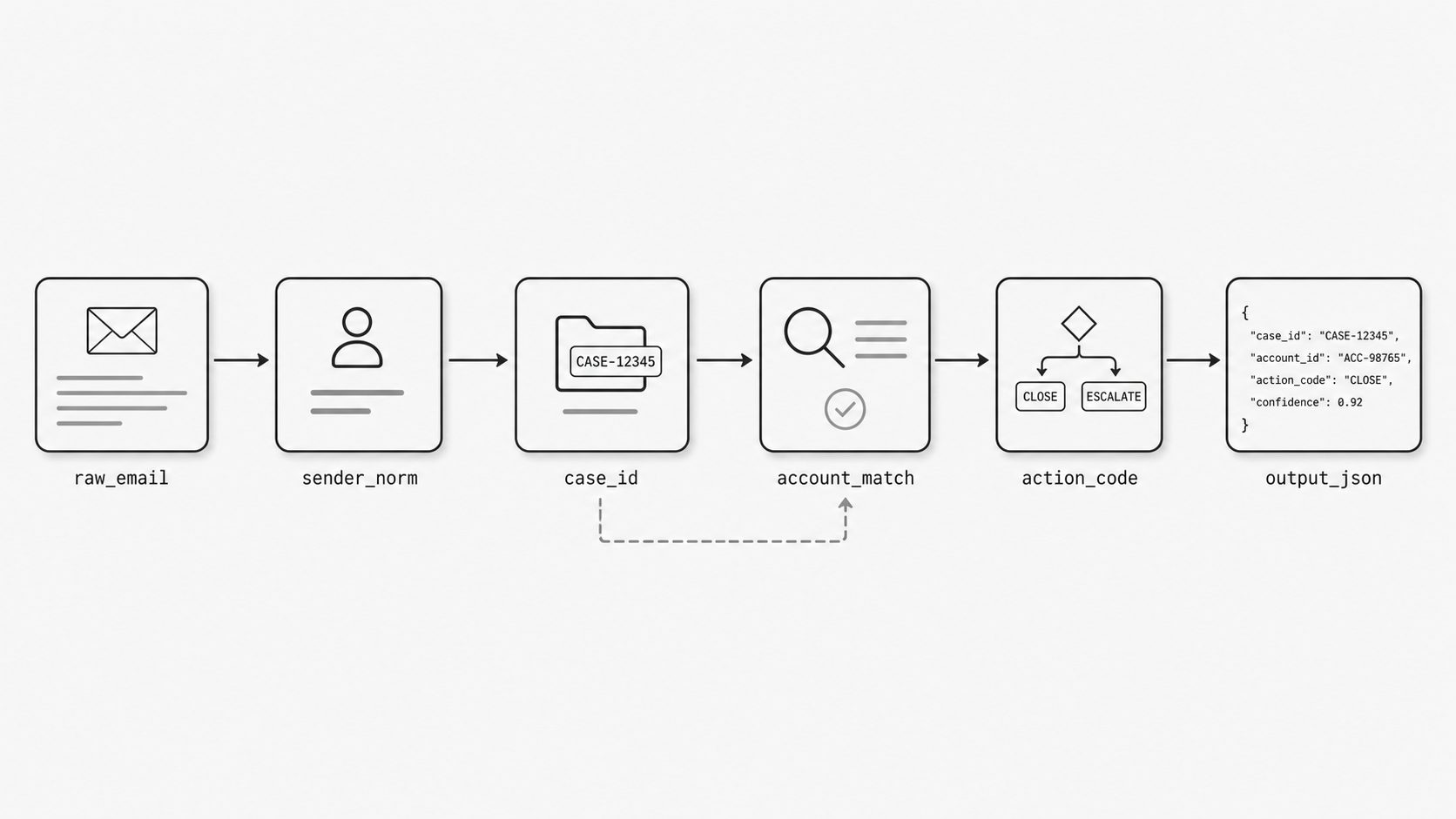
I see a clear turning point in custom mapping work. At first, a team writes a few field rules and it feels like formatting. Then the logic grows. One value depends on a cleaned sender address. Another depends on a date pulled from the subject line. A routing code depends on both, plus a check against message metadata. That is the moment the work stops acting like a template and starts acting like a small system. When teams handle inbound email parsing for bespoke workflows, that shift matters because the output is no longer a flat copy of extracted fields. It becomes a chain of decisions where one result shapes the next. (JSONata Documentation: Programming)
This is why I like to think in ordered steps. I do not want one giant expression trying to do every transformation at once. I want a sequence that a team can read. First normalize the sender. Then extract the business identifier. Then derive the account match. Then compute the action code. Then assemble the final JSON. That approach lowers review friction because each step has a clear purpose, and each later step can reuse earlier work instead of recalculating it.
Here is a small before-and-after example. The raw email has useful facts. The mapped output puts those facts into the receiving application’s shape.
Raw email fields:
{
"message": {
"from": [
{
"email": "OPS@acme.example"
}
],
"subject": "Priority support request for ACME-7421"
},
"body": {
"text": "Please escalate this account issue. Account: ACME-7421."
},
"meta": {
"received_at": "2026-06-12T10:15:00Z"
}
}
Custom mapped output:
{
"customer": {
"account_id": "ACME-7421"
},
"ticket": {
"priority": "high",
"requested_action": "escalate"
},
"source": {
"sender_email": "ops@acme.example",
"received_at": "2026-06-12T10:15:00Z"
}
}
A platform-specific mapper would use its own expression syntax. At the article level, the important part is the order of the values:
1. sender_email
Lowercase message.from[0].email.
2. account_id
Read the account pattern from body.text.
3. urgency
Set "high" when the subject or body mentions priority.
Otherwise set "normal".
4. final output
customer.account_id = account_id
ticket.priority = urgency
ticket.requested_action = "escalate" when the body asks for escalation.
source.sender_email = sender_email
source.received_at = meta.received_at
Those names are doing real work. sender_email, account_id, and urgency give reviewers a place to check the business logic before it becomes the webhook payload.
The idea is grounded in how transformation languages already work. JSONata supports variable binding and expression composition, which means intermediate results can be defined and reused during a transformation. I think that matters beyond syntax. It reinforces a design habit: name the important intermediate values, keep the order intentional, and make the path from raw message to final payload visible.
You might be wondering: why does this matter so much for technical leaders? Because unreadable mapping logic creates operational risk. If the only way to understand an output field is to mentally trace one dense expression, the team has hidden business logic inside a fragile artifact. When the destination system changes, the risk is not just that one field breaks. The risk is that nobody knows which downstream values were quietly depending on it. Ordered variable derivation makes those dependencies easier to inspect because the sequence exposes them.
I have found this especially useful when an inbound parse webhook feeds a custom intake or case workflow. A message may arrive with partial structure, mixed formatting, and business terms scattered across subject, body, headers, and metadata. In that kind of flow, deriving values in order helps the team separate extraction from interpretation. One step finds candidate values. A later step chooses the trusted one. Another step converts it into the receiving system’s expected format. That is a much cleaner operating model than packing every assumption into one final output rule.
It also improves maintenance. When a team needs to answer a simple question like, “Where did this field come from?” they should be able to follow the chain quickly. Named intermediate values create that trail. They also make testing easier because each stage can be validated with realistic examples before the final payload is assembled.
The practical insight is simple: if your custom output depends on layered business logic, treat the mapping like a sequence, not a blob. Name the intermediate values that carry business meaning. Keep their order deliberate. Reuse prior results instead of recomputing them. That gives your team a transformation that is easier to review, easier to change, and easier to trust when production data gets messy. In my experience, that is when custom output starts creating real product value. The handoff becomes more stable because the logic is easier to see, and the team gains a clearer path from raw email to decision-ready JSON.
What should a custom mapper be allowed to look at?
I have seen teams limit a mapper to the email body and then wonder why the output still feels thin. The answer is usually simple. Real business meaning is rarely stored in one place. An inbound email parsing flow may need the subject for a case number, the sender domain for account trust, attachment names for document type, envelope metadata for routing, and prior computed values for the final decision. When a custom mapper can only see part of that picture, the downstream team ends up rebuilding context somewhere else. That defeats the whole point of using an email parsing API to create a clean handoff.
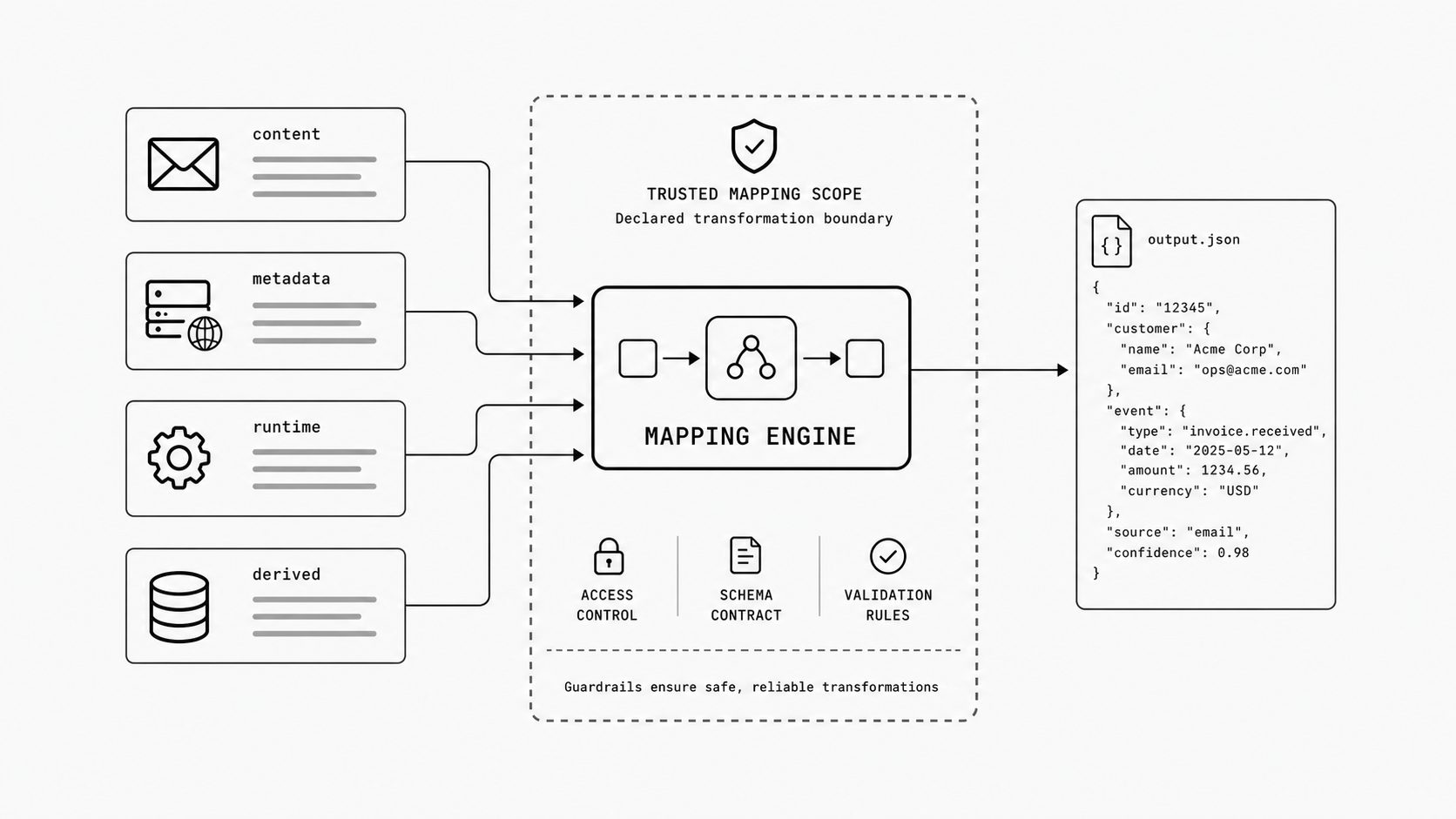
So I ask a basic design question early: what should the mapper be allowed to look at? My answer is broad, with guardrails. It should be able to read the raw message content, parsed fields, transport and header metadata, runtime settings, and any variables already derived earlier in the flow. That scope gives the transformation enough context to produce useful output without turning the receiving application into a second parsing engine.
Here is why this matters in practice. Most bespoke applications do not make decisions from body text alone. They act on context. A ticketing workflow may care whether the message came through a support alias or a partner alias. A claims intake system may need a policy number pulled from the subject, a sender check against a trusted domain, and an attachment count to decide whether the record is ready for review. A finance workflow may need runtime information such as the environment, tenant, or rule set version that was active when the transformation ran.
That means a custom mapper should have access to four input layers. First, the message itself - subject, body, attachments, and extracted entities. Second, metadata - headers, envelope details, timestamps, and delivery attributes. Third, runtime context - configuration values, environment settings, or workflow parameters passed into the transformation. Fourth, prior derived values - the intermediate results your team already computed earlier in the mapping sequence. When those layers are available together, the mapper can make decisions once and place them directly into the output JSON.
A concrete routing example makes that scope easier to picture. Say the receiving case system needs one field, case.routing_key, and that value decides the first queue.
message layer:
message.subject = "Claim P-8842 documents attached"
body.attachments[0].filename = "claim-p-8842.pdf"
metadata layer:
meta.route_alias = "claims-vip@example.com"
runtime context:
runtime.tenant = "north-america"
prior variables:
policy_id = "P-8842"
sender_trust = "trusted_partner"
case.routing_key =
runtime.tenant & "." &
(meta.route_alias = "claims-vip@example.com" ? "vip_claims" : "claims") & "." &
policy_id & "." &
sender_trust & "." &
(count(body.attachments) > 0 ? "docs_ready" : "needs_docs")
The emitted output field would be:
{
"case": {
"routing_key": "north-america.vip_claims.P-8842.trusted_partner.docs_ready"
}
}
That one field uses the message layer for attachment readiness, metadata for the route alias, runtime context for the tenant, and prior variables for the policy and sender trust decision. The receiver gets a queue-ready value instead of rebuilding the same context after delivery.
I think this is where teams get the most leverage from a parse incoming email API. The platform is already the point where raw input becomes structured data. If it can combine content with context there, the receiving system gets a payload that is much closer to action-ready. The handoff becomes easier to test because the logic lives in one place with a visible input scope.
There is also an operational reason to be thoughtful here. Richer transformation scope can add logic, and more logic can tempt teams to do too much work inline. GitHub’s webhook guidance recommends acknowledging deliveries quickly and processing payloads asynchronously in the background. I think that is a useful design signal for any webhook-driven integration. Give the mapper enough context to shape the payload well, then let downstream processing happen in a way that does not put reliable receipt at risk. (GitHub Webhook Best Practices)
You might be wondering: does broad scope make the mapper harder to govern? It can, if every possible field is treated as fair game. I prefer a declared scope. Be explicit about which metadata fields are trusted, which runtime values are injectable, and which derived variables are safe to reference. That keeps the transformation readable and gives reviewers a clear boundary around where output values are coming from.
The practical rule I use is this: let the mapper see everything that meaningfully improves the handoff, then define that scope on purpose. If your output depends on who sent the message, how it arrived, what rules were active, and what earlier logic already concluded, the mapper should be able to use those signals directly. That is how custom output becomes genuinely useful for technical teams integrating with bespoke applications. The final JSON carries more business intent, the receiver does less reconstruction, and the overall email to JSON API flow becomes easier to trust in production.
Custom output ownership: what your team commits to
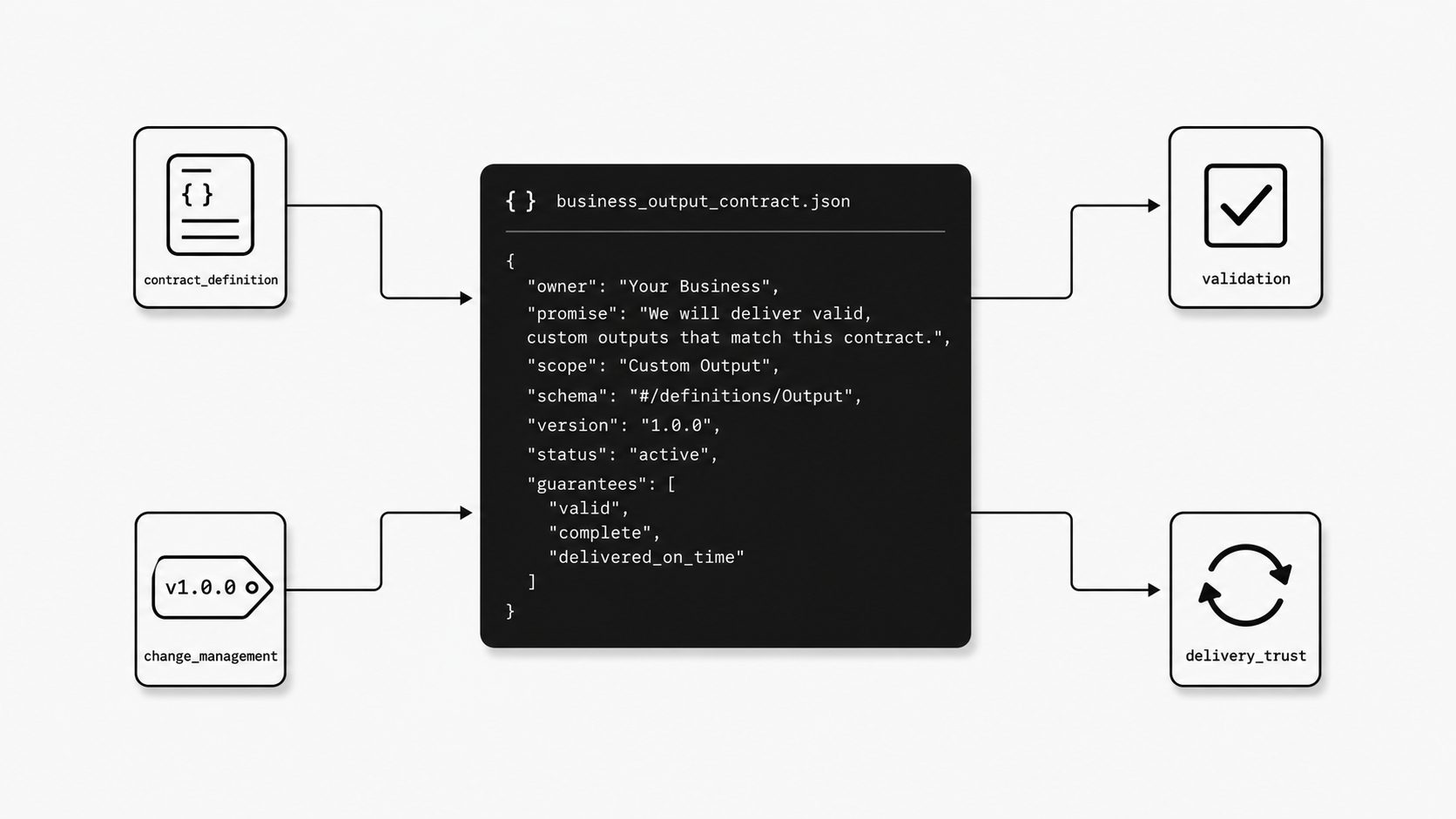
I think this is the conversation many teams skip because the custom mapper looks so helpful at first. Everyone is excited that the email webhook can now emit a payload that fits the receiving system perfectly. The demo works. The fields line up. The downstream app needs less translation code. Then I ask the question I want every technical leader to say out loud: who owns this contract the first time the destination system changes, a sender changes format, or a failed delivery has to be replayed? (JSON Schema Validation Specification)
That question matters because a custom handoff is no longer just output formatting. It becomes an operating promise. Once another application starts depending on your structured email JSON output, your team owns field names, required values, validation behavior, versioning decisions, and failure handling around that contract. (Stripe Webhooks)
In my experience, this is where mature teams separate enthusiasm from readiness. A custom contract creates real value because it can give a bespoke application exactly the shape it expects. Still, that precision creates obligations. If your team defines an email JSON schema for a downstream workflow, the schema needs to stay stable enough that consumers can trust it release after release. When it changes, the change needs intent, review, and communication. Otherwise the team has simply moved integration fragility from the consumer side to the producer side.
I usually frame ownership in four plain responsibilities.
First, own the contract definition. Someone has to decide which fields are required, which are optional, which values are allowed, and what each property means in business terms.
Second, own validation. A stable JSON contract for email only helps when invalid or partial output is handled consistently. That can mean rejecting a payload, marking it incomplete, or routing it for review. The important point is that the behavior is deliberate.
Third, own change management. Bespoke contracts tend to accumulate hidden dependencies because downstream teams build workflows, alerts, and reports on top of them. Even a small rename can break real work.
Fourth, own delivery trust. Stripe recommends verifying webhook signatures, and it documents automatic retries with exponential backoff for failed deliveries in live mode. I see that as a useful model for any inbound email webhook handoff. If a team wants downstream systems to trust custom output, it should also be clear how authenticity is checked and what happens when delivery fails.
You might be wondering: does this mean custom output is only for large teams with heavy process? I do not think so. I think it means teams should enter with open eyes. The right question is not whether custom mapping is possible. The right question is whether the team is willing to own the lifecycle of the contract after launch.
A simple test I use is this: if the receiving system would open an incident when a field disappears, changes type, or arrives late, then the output already behaves like a product surface. Product surfaces need owners.
So here is the sentence I want teams to say before they commit: we are not just customizing output - we are accepting responsibility for a business-critical handoff. Once that is explicit, better decisions follow. Teams document the contract. They define validation rules. They plan version changes. They verify the sender and prepare for retries. And the custom mapper stops being a clever convenience layer and starts becoming a dependable interface the business can build on.
That clarity is the real advantage of custom output ownership. It does not slow the work down. It tells you whether the team is ready to make the handoff trustworthy.
The pattern across all of this is straightforward: custom output becomes worth it when the destination system has a strong opinion about what usable data looks like. At that point, shaping JSON around business meaning can reduce downstream code, expose transformation logic more clearly, and make webhook handoffs easier to trust. But the benefit only holds if teams are deliberate about structure, derivation order, input scope, and long-term ownership.
That is why I see custom mapping as a product decision as much as an integration feature. When done well, it turns inbound email into a cleaner operational interface for bespoke applications. When done casually, it just relocates complexity. The teams that get the most value are usually the ones that recognize the difference early and design the handoff accordingly.