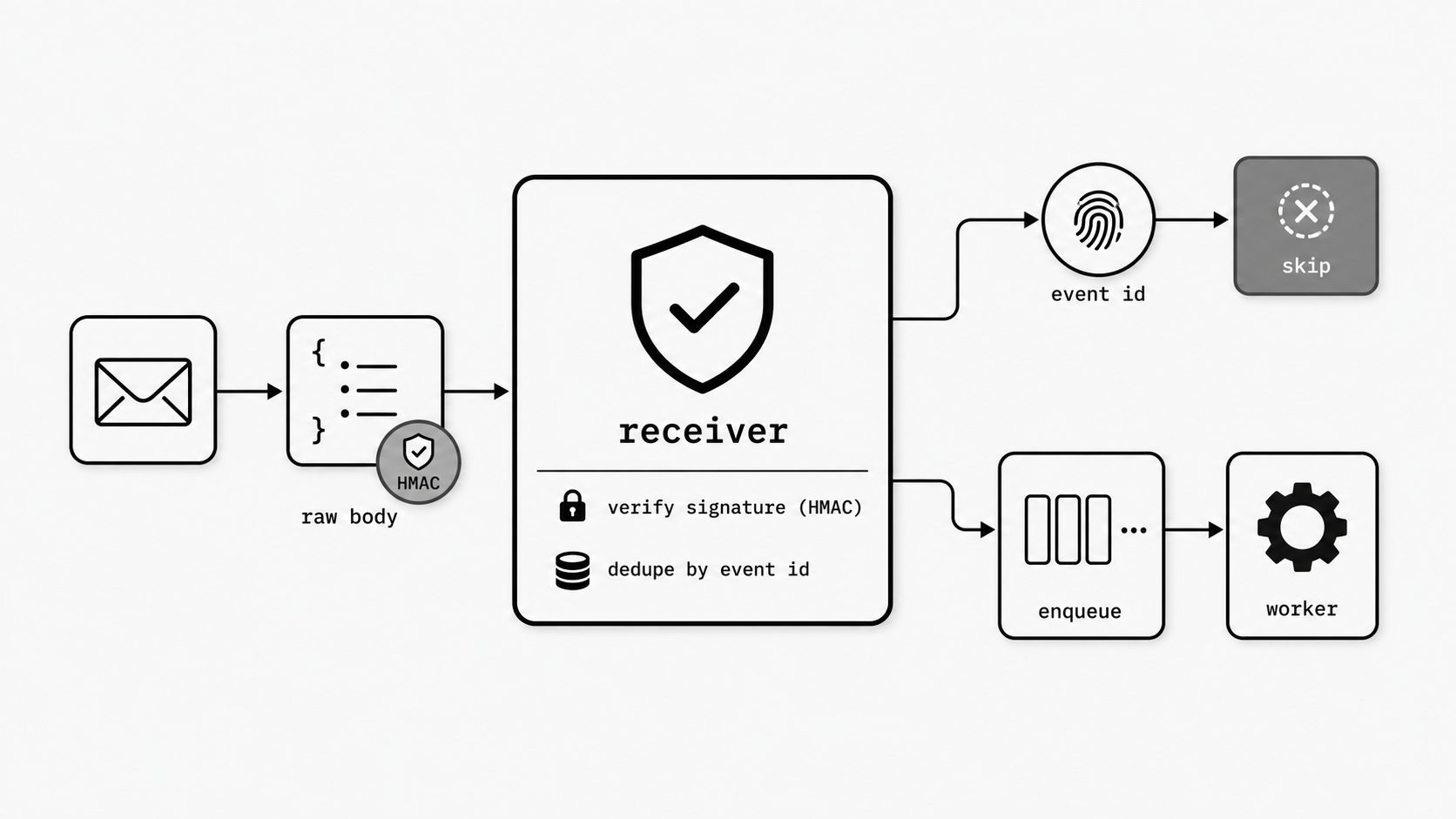
If you are building an inbound email workflow, the hard part usually is not receiving the POST request. It is receiving it correctly under real conditions: preserving the raw body for verification, rejecting forged requests, handling duplicate deliveries safely, and getting out of the request path fast enough that retries do not become your next incident. That is the gap this guide is meant to close.
In an earlier architecture post, I broke the inbound email pipeline into stages. This article moves one layer closer to the code you actually ship: the webhook receiver your application exposes to accept inbound email events from MailWebhook. I will keep the implementation practical and language-specific, with complete working examples in Node.js, Python, and Go.
Across all three stacks, the pattern stays the same. Capture the request exactly as it arrived. Verify X-MailWebhook-Signature against the timestamp-prefixed raw body, using the key identified by kid. Use X-Idempotency-Key to prevent duplicate side effects. Then acknowledge quickly and hand the payload to background processing. Once that order is clear, the framework details become much easier to reason about.
What the webhook payload looks like
Before the receiver code matters, it helps to see the shape of the event your endpoint accepts. With the Generic JSON route pipeline, MailWebhook sends a mailwebhook.generic@1 payload. It keeps delivery metadata, message metadata, body content, and attachment metadata in stable top-level sections.
{
"schema": {
"name": "mailwebhook.generic",
"version": "1"
},
"event": {
"id": "6ff49aa1-7050-4ad1-95d9-2711f2ca7e88",
"project_id": "dca29061-c4a7-4687-a8dd-24d2f26548c7",
"route_id": "2f3713bf-88cc-46c6-aaa3-ea9d6e9d20f3",
"created_at": "2026-05-22T14:18:32Z"
},
"message": {
"message_id": "<invoice-inv-1048@acme.example>",
"message_id_type": "original",
"subject": "Invoice INV-1048 for May services",
"date": "2026-05-22T14:16:57Z",
"from": [
{
"name": "Acme Supplies",
"email": "billing@acme.example"
}
],
"to": [
{
"email": "invoices@example.com"
}
],
"headers": {
"message-id": "<invoice-inv-1048@acme.example>",
"from": "Acme Supplies <billing@acme.example>"
}
},
"body": {
"text": "Please find invoice INV-1048 attached for May services.",
"attachments": [
{
"id": "9f5a1ded-538d-4f5f-a7a9-d3eacf9e58a0",
"filename": "invoice-inv-1048.pdf",
"content_type": "application/pdf",
"size": 184233,
"is_inline": false
}
]
},
"meta": {
"source": "imap",
"raw_size_bytes": 215423,
"received_at": "2026-05-22T14:18:32Z"
}
}
The exact body you emit depends on the route pipeline. Generic JSON uses schema, event, message, body, and meta. Custom JSON routes can emit a different object entirely. The delivery contract that stays available across both modes is the signed raw JSON body plus delivery headers such as X-MailWebhook-Signature and X-Idempotency-Key. Use event.id as useful Generic JSON context, and use X-Idempotency-Key as the receiver’s duplicate-delivery key.
What a reliable inbound email receiver looks like
I have seen teams lose hours on an email webhook issue that looked random at first. The endpoint returned 200. The payload looked fine in logs. Yet signature checks failed, retries stacked up, and some messages vanished into a gray area between “accepted” and “actually handled.” The root problem is usually simpler than it seems: the receiver does too much, too late, and in the wrong order. A reliable inbound email webhook starts with a small promise - accept the request in the exact form it arrived, respond fast, and avoid any work that can break delivery before you have safely captured the event. (Express API Reference - express.raw)
So what does that look like in practice? I think of the receiver as a narrow front door for your email to webhook flow. Its job is not to parse business meaning, update records, call five downstream systems, or decide whether the sender matters. Its first job is to accept the POST safely.
That means four things.
First, read the raw request body before any mutation. This matters because signature verification depends on the exact bytes that arrived. In Express, express.raw() gives you the body as a Buffer, which is exactly what you want on a signed webhook route. In Python stacks built on Werkzeug, request.get_data() gives access to the incoming body, and the docs also warn that reading request data loads it into memory, which is why request size limits belong in the design from day one. In Go, the standard library notes that reading Request.Body after writing to the response may not be possible in some cases, so the safe pattern is to capture the body first and then decide how to respond. (Werkzeug Documentation - Dealing with Request Data)
Second, accept the content type you actually expect, and fail gently when it is wrong. For most email webhook tutorial examples, that means JSON over application/json, but the real point is consistency. Your endpoint should validate that the payload is shaped like your expected email JSON schema, handle missing fields without panicking, and return a clear client error for malformed input instead of crashing the process. When the contract is stable, the rest of the pipeline gets much easier to reason about.
Third, return a fast 2xx once the request is verified and durably handed off. This is where many teams blur transport work with business work. If your receiver waits on parsing attachments, database joins, spam rules, or downstream APIs, you turn a simple mail webhook into a timeout risk. The safer pattern is short and boring: capture raw body, verify, do a minimal schema check, enqueue or persist, then acknowledge. Everything heavier can happen after that.
Fourth, treat unexpected payloads as normal operating conditions. Real systems receive duplicates, partial payloads, oversized bodies, and occasional junk traffic. A good receiver logs enough to debug, rejects what it cannot trust, and keeps the process alive. You might be wondering: is that too defensive for a basic email to webhook endpoint? I do not think so. This small discipline is what keeps a simple receiver reliable once real traffic starts showing up.
If you only keep one mental model from this section, keep this one: a strong receiver is a byte-preserving, fast-acknowledging buffer between the outside world and your real application logic. That design gives you cleaner signature verification, fewer retry storms, and a much safer path into the language-specific code we will cover next. In other words, before Node.js, Python, or Go details matter, the winning pattern is already set - capture first, validate carefully, acknowledge quickly, and process later. (Go net/http Package Documentation)
Complete endpoint examples
These examples show the same receiver pattern in each stack for Generic JSON route output. They claim X-Idempotency-Key in Redis before any business side effect runs, so duplicate delivery stays safe across processes and deploys. If your route emits Custom JSON, keep the same signature and idempotency handling, then swap in a validator for your mapped payload.
import crypto from "node:crypto";
import express from "express";
import { createClient } from "redis";
const app = express();
const port = Number(process.env.PORT || 3000);
const claimTtlSeconds = 60 * 60 * 24 * 7;
const signingKid = process.env.MAILWEBHOOK_SIGNING_KID || "default";
const webhookSecret = process.env.MAILWEBHOOK_SECRET || "";
const signingSecrets = new Map([
[signingKid, Buffer.from(webhookSecret, "utf8")],
]);
const redisClient = createClient({
url: process.env.REDIS_URL || "redis://localhost:6379/0",
});
if (!webhookSecret) {
throw new Error("MAILWEBHOOK_SECRET is required");
}
redisClient.on("error", (error) => {
console.error("Redis client error", error);
});
function parseSignatureHeader(signatureHeader) {
if (!signatureHeader) {
return null;
}
const parts = new Map();
for (const part of signatureHeader.split(",")) {
const [rawKey, ...rawValue] = part.trim().split("=");
if (!rawKey || rawValue.length === 0) continue;
parts.set(rawKey, rawValue.join("="));
}
const timestamp = Number(parts.get("t"));
const kid = parts.get("kid");
const macBase64 = parts.get("v1");
if (!Number.isInteger(timestamp) || !kid || !macBase64) {
return null;
}
return { timestamp, kid, macBase64 };
}
function verifySignature(rawBody, signatureHeader, toleranceSeconds = 300) {
const parsed = parseSignatureHeader(signatureHeader);
if (!parsed) {
return false;
}
const now = Math.floor(Date.now() / 1000);
if (Math.abs(now - parsed.timestamp) > toleranceSeconds) {
return false;
}
const secret = signingSecrets.get(parsed.kid);
if (!secret) {
return false;
}
const expected = crypto
.createHmac("sha256", secret)
.update(String(parsed.timestamp))
.update(".")
.update(rawBody)
.digest();
const received = Buffer.from(parsed.macBase64, "base64");
return (
received.length === expected.length &&
crypto.timingSafeEqual(received, expected)
);
}
async function claimDelivery(idempotencyKey) {
if (!idempotencyKey) {
return false;
}
const result = await redisClient.set(
`mailwebhook:delivery:${idempotencyKey}`,
"claimed",
{
NX: true,
EX: claimTtlSeconds,
},
);
return result === "OK";
}
function getGenericEventId(event) {
return typeof event?.event?.id === "string" ? event.event.id : null;
}
function isGenericMailWebhookPayload(value) {
return (
value &&
typeof value === "object" &&
value.schema?.name === "mailwebhook.generic" &&
value.schema?.version === "1" &&
typeof value.event?.id === "string" &&
typeof value.message?.message_id === "string" &&
Array.isArray(value.message?.from) &&
Array.isArray(value.body?.attachments) &&
typeof value.meta?.source === "string"
);
}
async function processInboundEmail(event, idempotencyKey) {
console.log("Processing inbound email delivery", {
idempotencyKey,
eventId: getGenericEventId(event),
});
}
app.post(
"/webhooks/inbound-email",
express.raw({ type: "application/json", limit: "2mb" }),
async (req, res) => {
try {
if (!Buffer.isBuffer(req.body)) {
return res.status(415).json({ error: "expected application/json" });
}
const signature = req.header("x-mailwebhook-signature");
const idempotencyKey = req.header("x-idempotency-key");
if (!verifySignature(req.body, signature)) {
return res.status(401).json({ error: "invalid signature" });
}
if (!idempotencyKey) {
return res.status(400).json({ error: "missing idempotency key" });
}
let event;
try {
event = JSON.parse(req.body.toString("utf8"));
} catch {
return res.status(400).json({ error: "invalid JSON" });
}
if (!isGenericMailWebhookPayload(event)) {
return res.status(400).json({ error: "invalid Generic JSON payload" });
}
if (!(await claimDelivery(idempotencyKey))) {
return res.status(200).json({ duplicate: true });
}
setImmediate(() => {
processInboundEmail(event, idempotencyKey).catch((error) => {
console.error("Inbound email processing failed", error);
});
});
return res.status(202).json({ accepted: true });
} catch (error) {
console.error("Inbound email receiver failed", error);
return res.status(503).json({ error: "receiver unavailable" });
}
},
);
async function main() {
await redisClient.connect();
app.listen(port, () => {
console.log(`Inbound email webhook receiver listening on ${port}`);
});
}
main().catch((error) => {
console.error("Failed to start inbound email receiver", error);
process.exit(1);
});
import base64
import binascii
import hashlib
import hmac
import json
import os
import threading
import time
from typing import Any
from flask import Flask, Response, jsonify, request
from redis import Redis
from redis.exceptions import RedisError
app = Flask(__name__)
claim_ttl_seconds = 60 * 60 * 24 * 7
webhook_secret = os.environ.get("MAILWEBHOOK_SECRET", "")
signing_kid = os.environ.get("MAILWEBHOOK_SIGNING_KID", "default")
signing_secrets = {signing_kid: webhook_secret.encode("utf-8")}
redis_client = Redis.from_url(
os.environ.get("REDIS_URL", "redis://localhost:6379/0"),
decode_responses=True,
)
if not webhook_secret:
raise RuntimeError("MAILWEBHOOK_SECRET is required")
def parse_signature_header(signature_header: str | None) -> dict[str, str] | None:
"""Parse a MailWebhook signature header into its key/value attributes."""
if not signature_header:
return None
parts: dict[str, str] = {}
for item in signature_header.split(","):
if "=" not in item:
continue
key, value = item.strip().split("=", 1)
parts[key] = value
if not {"t", "kid", "v1"} <= parts.keys():
return None
return parts
def verify_signature(
raw_body: bytes,
signature_header: str | None,
tolerance_seconds: int = 300,
) -> bool:
"""Verify a MailWebhook timestamped HMAC signature against raw bytes."""
parts = parse_signature_header(signature_header)
if parts is None:
return False
try:
timestamp = int(parts["t"])
except ValueError:
return False
if abs(int(time.time()) - timestamp) > tolerance_seconds:
return False
secret = signing_secrets.get(parts["kid"])
if secret is None:
return False
expected = hmac.new(
secret,
f"{timestamp}.".encode("utf-8") + raw_body,
hashlib.sha256,
).digest()
try:
received = base64.b64decode(parts["v1"], validate=True)
except (binascii.Error, ValueError):
return False
return hmac.compare_digest(received, expected)
def claim_delivery(idempotency_key: str | None) -> bool:
"""Claim a MailWebhook delivery idempotency key atomically in Redis."""
if not idempotency_key:
return False
return bool(
redis_client.set(
f"mailwebhook:delivery:{idempotency_key}",
"claimed",
nx=True,
ex=claim_ttl_seconds,
)
)
def generic_event_id(event: dict[str, Any]) -> str | None:
"""Return the Generic JSON event ID when this payload includes one."""
generic_event = event.get("event")
if not isinstance(generic_event, dict):
return None
event_id = generic_event.get("id")
return event_id if isinstance(event_id, str) else None
def is_generic_mailwebhook_payload(value: Any) -> bool:
"""Return True when the parsed JSON has the required Generic JSON shape."""
if not isinstance(value, dict):
return False
schema = value.get("schema")
event = value.get("event")
message = value.get("message")
body = value.get("body")
meta = value.get("meta")
return (
isinstance(schema, dict)
and schema.get("name") == "mailwebhook.generic"
and schema.get("version") == "1"
and isinstance(event, dict)
and isinstance(event.get("id"), str)
and isinstance(message, dict)
and isinstance(message.get("message_id"), str)
and isinstance(message.get("from"), list)
and isinstance(body, dict)
and isinstance(body.get("attachments"), list)
and isinstance(meta, dict)
and isinstance(meta.get("source"), str)
)
def process_inbound_email(event: dict[str, Any], idempotency_key: str) -> None:
"""Run the application-specific email workflow outside the request path."""
app.logger.info(
"Processing inbound email delivery %s event=%s",
idempotency_key,
generic_event_id(event),
)
@app.post("/webhooks/inbound-email")
def inbound_email_webhook() -> tuple[Response, int]:
if request.mimetype != "application/json":
return jsonify({"error": "expected application/json"}), 415
raw_body = request.get_data(cache=False)
signature = request.headers.get("x-mailwebhook-signature")
idempotency_key = request.headers.get("X-Idempotency-Key")
if not verify_signature(raw_body, signature):
return jsonify({"error": "invalid signature"}), 401
if not idempotency_key:
return jsonify({"error": "missing idempotency key"}), 400
try:
event = json.loads(raw_body)
except json.JSONDecodeError:
return jsonify({"error": "invalid JSON"}), 400
if not is_generic_mailwebhook_payload(event):
return jsonify({"error": "invalid Generic JSON payload"}), 400
try:
claimed = claim_delivery(idempotency_key)
except RedisError:
app.logger.exception("Idempotency store unavailable")
return jsonify({"error": "idempotency store unavailable"}), 503
if not claimed:
return jsonify({"duplicate": True}), 200
worker = threading.Thread(
target=process_inbound_email,
args=(event, idempotency_key),
daemon=True,
)
worker.start()
return jsonify({"accepted": True}), 202
package main
import (
"context"
"crypto/hmac"
"crypto/sha256"
"encoding/base64"
"encoding/json"
"errors"
"fmt"
"io"
"log"
"mime"
"net/http"
"os"
"strconv"
"strings"
"time"
"github.com/redis/go-redis/v9"
)
const claimTTL = 7 * 24 * time.Hour
type Person struct {
Name string `json:"name,omitempty"`
Email string `json:"email"`
}
type Attachment struct {
ID string `json:"id"`
Filename string `json:"filename"`
ContentType string `json:"content_type"`
Size int64 `json:"size"`
IsInline bool `json:"is_inline"`
ContentID string `json:"content_id,omitempty"`
SHA256 string `json:"sha256,omitempty"`
}
type GenericPayload struct {
Schema struct {
Name string `json:"name"`
Version string `json:"version"`
} `json:"schema"`
Event struct {
ID string `json:"id"`
ProjectID string `json:"project_id"`
RouteID string `json:"route_id"`
CreatedAt string `json:"created_at"`
} `json:"event"`
Message struct {
MessageID string `json:"message_id"`
MessageIDType string `json:"message_id_type"`
Subject string `json:"subject"`
Date string `json:"date"`
From []Person `json:"from"`
To []Person `json:"to"`
} `json:"message"`
Body struct {
Text string `json:"text,omitempty"`
HTML string `json:"html,omitempty"`
Attachments []Attachment `json:"attachments"`
} `json:"body"`
Meta struct {
Source string `json:"source"`
RawSizeBytes int64 `json:"raw_size_bytes"`
ReceivedAt string `json:"received_at"`
} `json:"meta"`
}
func (p GenericPayload) Valid() bool {
return p.Schema.Name == "mailwebhook.generic" &&
p.Schema.Version == "1" &&
p.Event.ID != "" &&
p.Message.MessageID != "" &&
p.Message.From != nil &&
p.Body.Attachments != nil &&
p.Meta.Source != ""
}
type ClaimStore struct {
redis *redis.Client
}
func NewClaimStore(redisURL string) (*ClaimStore, error) {
options, err := redis.ParseURL(redisURL)
if err != nil {
return nil, err
}
client := redis.NewClient(options)
if err := client.Ping(context.Background()).Err(); err != nil {
return nil, err
}
return &ClaimStore{redis: client}, nil
}
func (s *ClaimStore) Claim(ctx context.Context, idempotencyKey string) (bool, error) {
if idempotencyKey == "" {
return false, nil
}
return s.redis.SetNX(
ctx,
fmt.Sprintf("mailwebhook:delivery:%s", idempotencyKey),
"claimed",
claimTTL,
).Result()
}
type SignatureParts struct {
Timestamp int64
Kid string
MacBase64 string
}
func parseSignatureHeader(signatureHeader string) (SignatureParts, bool) {
parts := make(map[string]string)
for _, item := range strings.Split(signatureHeader, ",") {
key, value, ok := strings.Cut(strings.TrimSpace(item), "=")
if !ok || key == "" {
continue
}
parts[key] = value
}
timestamp, err := strconv.ParseInt(parts["t"], 10, 64)
if err != nil || parts["kid"] == "" || parts["v1"] == "" {
return SignatureParts{}, false
}
return SignatureParts{
Timestamp: timestamp,
Kid: parts["kid"],
MacBase64: parts["v1"],
}, true
}
func verifySignature(
rawBody []byte,
signatureHeader string,
secretsByKid map[string][]byte,
tolerance time.Duration,
) bool {
parts, ok := parseSignatureHeader(signatureHeader)
if !ok {
return false
}
now := time.Now()
signedAt := time.Unix(parts.Timestamp, 0)
if signedAt.Before(now.Add(-tolerance)) || signedAt.After(now.Add(tolerance)) {
return false
}
secret, ok := secretsByKid[parts.Kid]
if !ok {
return false
}
received, err := base64.StdEncoding.DecodeString(parts.MacBase64)
if err != nil {
return false
}
mac := hmac.New(sha256.New, secret)
mac.Write([]byte(strconv.FormatInt(parts.Timestamp, 10)))
mac.Write([]byte("."))
mac.Write(rawBody)
expected := mac.Sum(nil)
return hmac.Equal(received, expected)
}
func processInboundEmail(event GenericPayload, idempotencyKey string) {
log.Printf(
"processing inbound email delivery %s event=%s",
idempotencyKey,
event.Event.ID,
)
}
func inboundEmailHandler(secretsByKid map[string][]byte, store *ClaimStore) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodPost {
http.Error(w, "method not allowed", http.StatusMethodNotAllowed)
return
}
mediaType, _, err := mime.ParseMediaType(r.Header.Get("Content-Type"))
if err != nil || mediaType != "application/json" {
http.Error(w, "expected application/json", http.StatusUnsupportedMediaType)
return
}
rawBody, err := io.ReadAll(http.MaxBytesReader(w, r.Body, 2<<20))
if err != nil {
http.Error(w, "request body too large", http.StatusRequestEntityTooLarge)
return
}
signature := r.Header.Get("x-mailwebhook-signature")
if !verifySignature(rawBody, signature, secretsByKid, 5*time.Minute) {
http.Error(w, "invalid signature", http.StatusUnauthorized)
return
}
idempotencyKey := r.Header.Get("X-Idempotency-Key")
if idempotencyKey == "" {
http.Error(w, "missing idempotency key", http.StatusBadRequest)
return
}
var event GenericPayload
if err := json.Unmarshal(rawBody, &event); err != nil {
http.Error(w, "invalid JSON", http.StatusBadRequest)
return
}
if !event.Valid() {
http.Error(w, "invalid Generic JSON payload", http.StatusBadRequest)
return
}
claimed, err := store.Claim(r.Context(), idempotencyKey)
if err != nil {
http.Error(w, "idempotency store unavailable", http.StatusServiceUnavailable)
return
}
if !claimed {
w.WriteHeader(http.StatusOK)
_, _ = w.Write([]byte(`{"duplicate":true}`))
return
}
go processInboundEmail(event, idempotencyKey)
w.WriteHeader(http.StatusAccepted)
_, _ = w.Write([]byte(`{"accepted":true}`))
}
}
func main() {
signingKid := os.Getenv("MAILWEBHOOK_SIGNING_KID")
if signingKid == "" {
signingKid = "default"
}
secret := os.Getenv("MAILWEBHOOK_SECRET")
if secret == "" {
log.Fatal(errors.New("MAILWEBHOOK_SECRET is required"))
}
secretsByKid := map[string][]byte{signingKid: []byte(secret)}
redisURL := os.Getenv("REDIS_URL")
if redisURL == "" {
redisURL = "redis://localhost:6379/0"
}
claimStore, err := NewClaimStore(redisURL)
if err != nil {
log.Fatal(err)
}
http.HandleFunc("/webhooks/inbound-email", inboundEmailHandler(secretsByKid, claimStore))
fmt.Println("Inbound email webhook receiver listening on :3000")
log.Fatal(http.ListenAndServe(":3000", nil))
}
How to verify that the webhook is authentic
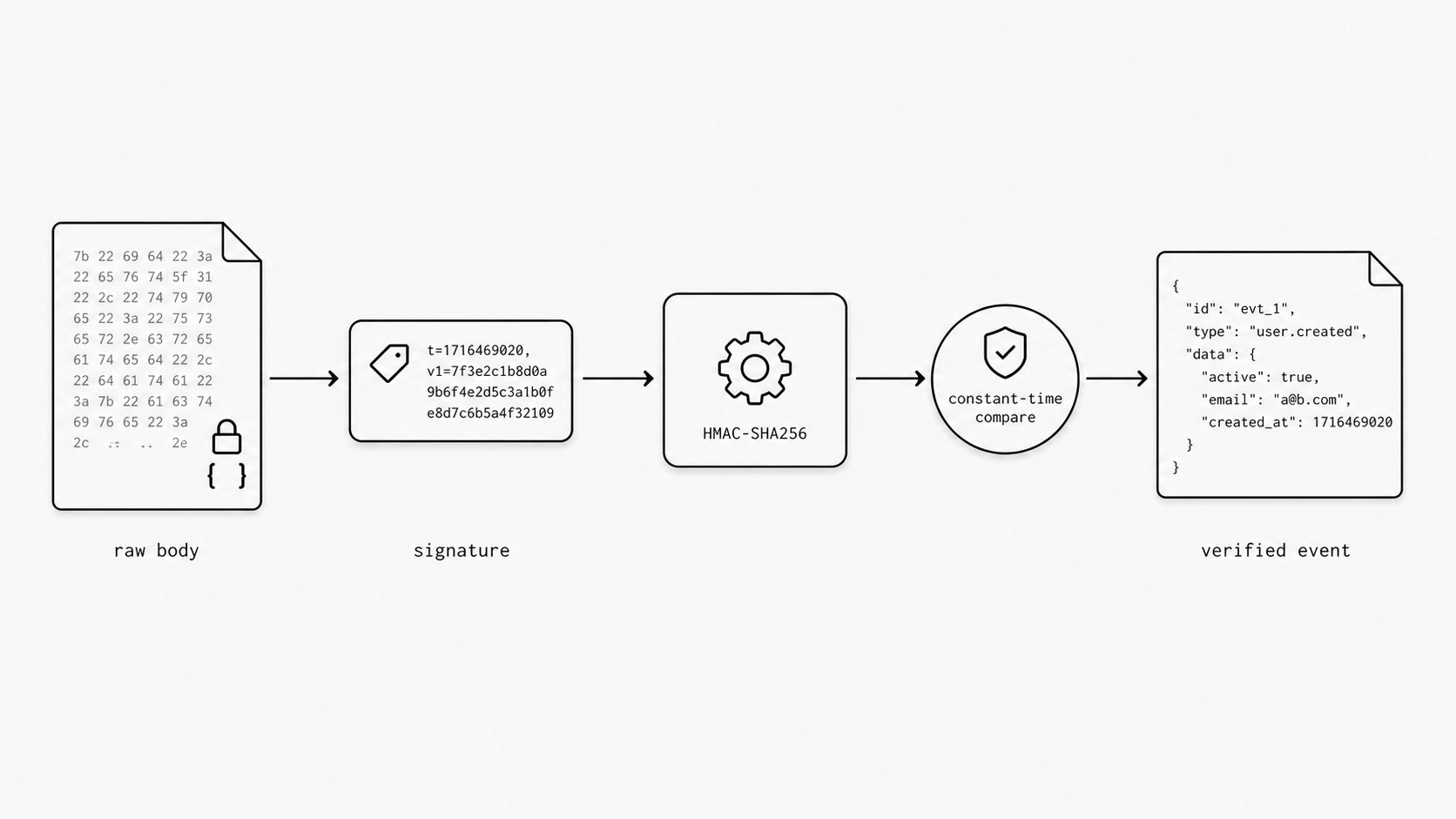
Here is where a lot of teams get a false sense of safety. The request hit the right URL. It contains JSON that looks valid. It even includes fields you expect from your email webhook tutorial. None of that proves the sender is real. If you skip verification, your endpoint is trusting any client that can reach it. If you verify the wrong bytes, you can still reject real events by mistake.
MailWebhook signs the exact request body bytes with a timestamped HMAC header:
X-MailWebhook-Signature: t=<unix>, kid=<kid>, v1=<base64(hmac_sha256(t+"."+body, secret))>
That means authenticating a webhook comes down to a small sequence that has to stay exact: read the raw body, parse t, kid, and v1, look up the signing secret by kid, compute the HMAC over t + "." + raw_body, base64-decode v1, and compare the raw digest bytes with a constant-time helper from the standard library. (Stripe Docs - Resolve webhook signature verification errors)
So what does that look like in code? I keep it simple and consistent across languages.
In Node.js, I read the raw request body as a Buffer, parse the structured signature header, compute an HMAC-SHA256 digest with crypto.createHmac, and compare the received digest to the expected digest with crypto.timingSafeEqual. Node documents crypto.timingSafeEqual for timing-safe comparison, which is exactly what you want when you validate webhook signatures. (Node.js Crypto API - crypto.timingSafeEqual)
In Python, the shape is almost identical. Read the body as raw bytes, parse the signature attributes, compute the digest with hmac.new(..., hashlib.sha256), and compare with hmac.compare_digest. Python’s standard library explicitly recommends compare_digest for this kind of verification because it reduces timing-attack exposure compared with ordinary equality checks. (Python Standard Library - hmac)
In Go, the standard library gives you the same building blocks with less ceremony. You create the MAC with hmac.New(sha256.New, secret), write the timestamp prefix and raw body bytes into it, then compare the received and expected MACs with hmac.Equal. Go’s crypto/hmac package documents hmac.Equal as the comparison helper for MAC values, which makes it the right default for webhook HMAC verification. (Go crypto/hmac Package Documentation)
import crypto from "node:crypto";
function parseMailWebhookSignature(signatureHeader) {
if (!signatureHeader) {
return null;
}
const parts = new Map();
for (const part of signatureHeader.split(",")) {
const [rawKey, ...rawValue] = part.trim().split("=");
if (!rawKey || rawValue.length === 0) continue;
parts.set(rawKey, rawValue.join("="));
}
const timestamp = Number(parts.get("t"));
const kid = parts.get("kid");
const macBase64 = parts.get("v1");
if (!Number.isInteger(timestamp) || !kid || !macBase64) {
return null;
}
return { timestamp, kid, macBase64 };
}
export function verifyMailWebhookSignature(
rawBody,
signatureHeader,
secretsByKid,
{ toleranceSeconds = 300 } = {},
) {
const parsed = parseMailWebhookSignature(signatureHeader);
if (!parsed) {
return false;
}
const now = Math.floor(Date.now() / 1000);
if (Math.abs(now - parsed.timestamp) > toleranceSeconds) {
return false;
}
const secret = secretsByKid.get(parsed.kid);
if (!secret) {
return false;
}
const expected = crypto
.createHmac("sha256", secret)
.update(String(parsed.timestamp))
.update(".")
.update(rawBody)
.digest();
const received = Buffer.from(parsed.macBase64, "base64");
return (
received.length === expected.length &&
crypto.timingSafeEqual(received, expected)
);
}
import base64
import binascii
import hashlib
import hmac
import time
from collections.abc import Mapping
def parse_mailwebhook_signature(signature_header: str | None) -> dict[str, str] | None:
"""Parse a MailWebhook signature header into its key/value attributes."""
if not signature_header:
return None
parts: dict[str, str] = {}
for item in signature_header.split(","):
if "=" not in item:
continue
key, value = item.strip().split("=", 1)
parts[key] = value
if not {"t", "kid", "v1"} <= parts.keys():
return None
return parts
def verify_mailwebhook_signature(
raw_body: bytes,
signature_header: str | None,
secrets_by_kid: Mapping[str, bytes],
tolerance_seconds: int = 300,
) -> bool:
"""Return True when the raw body matches a timestamped MailWebhook HMAC."""
parts = parse_mailwebhook_signature(signature_header)
if parts is None:
return False
try:
timestamp = int(parts["t"])
except ValueError:
return False
if abs(int(time.time()) - timestamp) > tolerance_seconds:
return False
secret = secrets_by_kid.get(parts["kid"])
if secret is None:
return False
expected = hmac.new(
secret,
f"{timestamp}.".encode("utf-8") + raw_body,
hashlib.sha256,
).digest()
try:
received = base64.b64decode(parts["v1"], validate=True)
except (binascii.Error, ValueError):
return False
return hmac.compare_digest(received, expected)
package webhooks
import (
"crypto/hmac"
"crypto/sha256"
"encoding/base64"
"strconv"
"strings"
"time"
)
type SignatureParts struct {
Timestamp int64
Kid string
MacBase64 string
}
func ParseMailWebhookSignature(signatureHeader string) (SignatureParts, bool) {
parts := make(map[string]string)
for _, item := range strings.Split(signatureHeader, ",") {
key, value, ok := strings.Cut(strings.TrimSpace(item), "=")
if !ok || key == "" {
continue
}
parts[key] = value
}
timestamp, err := strconv.ParseInt(parts["t"], 10, 64)
if err != nil || parts["kid"] == "" || parts["v1"] == "" {
return SignatureParts{}, false
}
return SignatureParts{
Timestamp: timestamp,
Kid: parts["kid"],
MacBase64: parts["v1"],
}, true
}
func VerifyMailWebhookSignature(
rawBody []byte,
signatureHeader string,
secretsByKid map[string][]byte,
tolerance time.Duration,
) bool {
parts, ok := ParseMailWebhookSignature(signatureHeader)
if !ok {
return false
}
now := time.Now()
signedAt := time.Unix(parts.Timestamp, 0)
if signedAt.Before(now.Add(-tolerance)) || signedAt.After(now.Add(tolerance)) {
return false
}
secret, ok := secretsByKid[parts.Kid]
if !ok {
return false
}
received, err := base64.StdEncoding.DecodeString(parts.MacBase64)
if err != nil {
return false
}
mac := hmac.New(sha256.New, secret)
mac.Write([]byte(strconv.FormatInt(parts.Timestamp, 10)))
mac.Write([]byte("."))
mac.Write(rawBody)
expected := mac.Sum(nil)
return hmac.Equal(received, expected)
}
The deeper lesson is language-independent. Signature verification depends on the exact bytes that arrived over HTTP. Stripe’s webhook documentation warns that changing the body before verification can cause the signature check to fail, which matches what backend teams run into across many signed webhook systems. That is why I treat the raw body as a protected input. Parse JSON after verification, not before. Log carefully. Avoid middleware on this route that reformats whitespace, changes encoding, or rebuilds the payload.
A clean implementation usually follows this order:
- Read the raw body bytes.
- Extract the signature header.
- Parse
t,kid, andv1fromX-MailWebhook-Signature. - Reject stale timestamps outside your replay tolerance.
- Look up the signing secret identified by
kid. - Compute HMAC-SHA256 over
t + "." + raw_body. - Base64-decode
v1and compare the raw digest bytes with a timing-safe helper. - Reject with 401 or 403 if verification fails.
- Only then parse and process the event.
You might be wondering: do I really need the constant-time compare if the secret is strong? I do. The standard libraries in Node.js, Python, and Go already give you the safe helper, so there is no reason to fall back to a plain string comparison when you validate webhook payloads.
If you want one practical rule for this section, use this one: authenticity lives or dies on byte preservation and safe comparison. Once you lock that in, the rest of the implementation becomes repeatable across Node.js, Python, and Go. That gives your email to webhook example a much stronger foundation, because you are no longer trusting the shape of the payload alone - you are proving it was signed with the key identified by the kid in the MailWebhook signature header. In the next implementation step, that verified event becomes safe to pass into replay protection and processing logic.
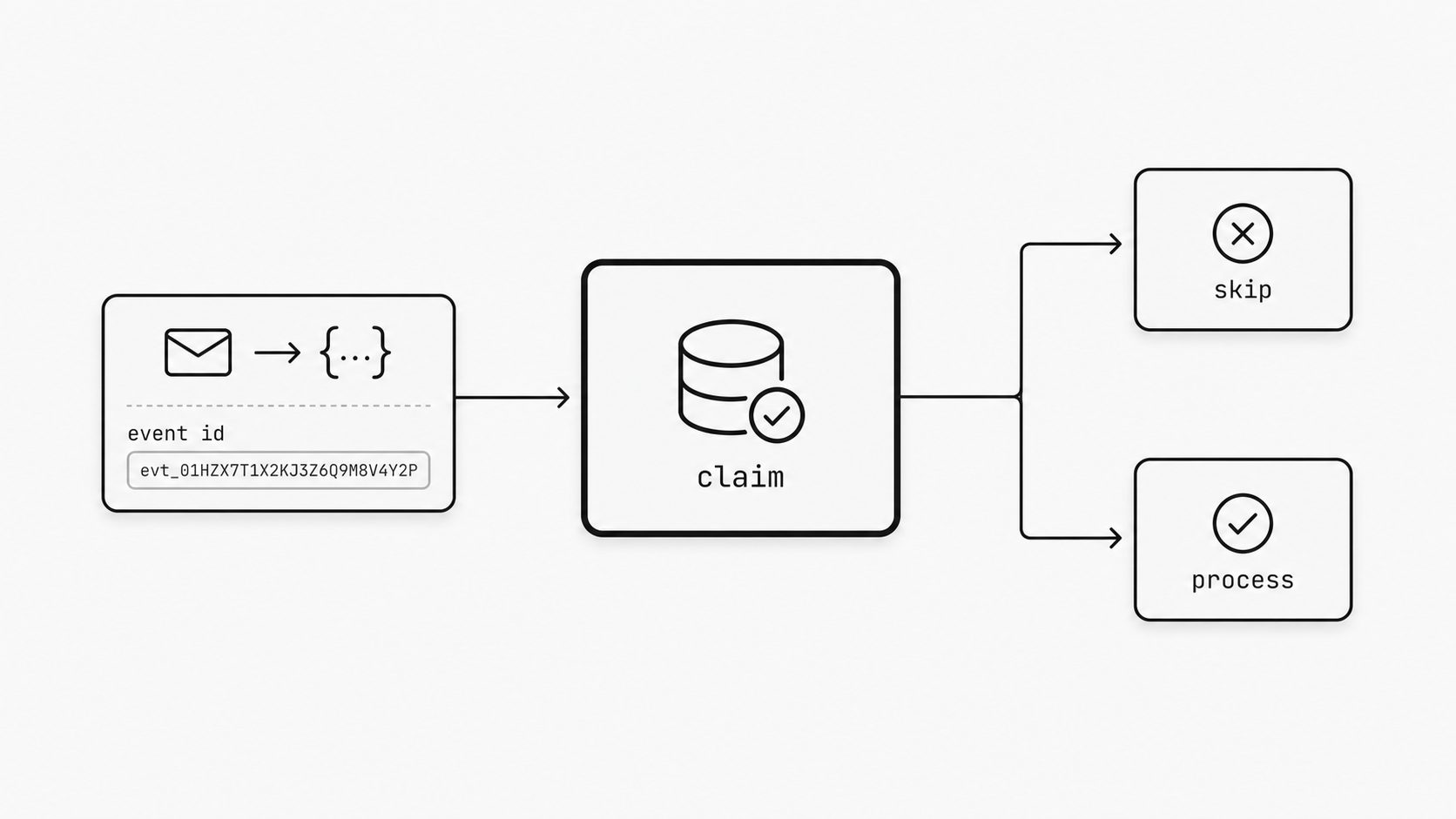
How to handle duplicate email events safely
A signed request is only half the story. Real webhook systems can deliver the same message more than once, so safe handlers must recognize replays and avoid repeating the same business action. MailWebhook sends X-Idempotency-Key with each delivery. That header is the right control field for duplicate detection because it is part of the delivery contract. (Stripe Docs - Idempotent requests)
In practice, the rule is simple: verify the webhook, read X-Idempotency-Key, and try to claim that key exactly once before any business logic runs. If the claim succeeds, processing continues. If the claim fails because the key already exists, return success without rerunning side effects. The first-seen record has to live in storage that can safely handle concurrency. Redis is a common fit because SET supports NX, which writes a key only when it does not already exist. PostgreSQL also works well because a unique constraint prevents duplicate values from being inserted into the constrained column. Across Node.js, Python, and Go, the syntax changes, but the pattern stays the same: one atomic insert or one conditional write keyed by X-Idempotency-Key. (Redis Commands - SET)
For Generic JSON payloads, event.id is still useful for logs and support workflows. For Custom JSON routes, the body may not include that field at all unless you map it in. The idempotency header is the stable receiver-level key.
If PostgreSQL is your preferred idempotency store, Webhook Idempotency Verification with PostgreSQL, Node.js, Python, and Go expands this pattern with SQL schema, atomic ON CONFLICT claims, request fingerprints, and complete Node.js, Python, and Go receiver examples.
The atomic Redis claim is the part to copy carefully. The receiver should call this before any business side effect runs:
In Node.js, Redis returns "OK" only for the first delivery that claims the idempotency key.
export async function claimMailWebhookDelivery(redisClient, idempotencyKey) {
if (!idempotencyKey) return false;
const result = await redisClient.set(
`mailwebhook:delivery:${idempotencyKey}`,
"claimed",
{
NX: true,
EX: 60 * 60 * 24 * 7,
},
);
return result === "OK";
}
In Python, redis-py exposes the same behavior with nx=True.
from redis import Redis
def claim_mailwebhook_delivery(
redis_client: Redis,
idempotency_key: str | None,
) -> bool:
"""Claim a MailWebhook delivery idempotency key once using Redis SET NX."""
if not idempotency_key:
return False
return bool(
redis_client.set(
f"mailwebhook:delivery:{idempotency_key}",
"claimed",
nx=True,
ex=604800,
)
)
In Go, SetNX returns true only when this delivery wrote the key.
package webhooks
import (
"context"
"fmt"
"time"
"github.com/redis/go-redis/v9"
)
func ClaimMailWebhookDelivery(
ctx context.Context,
redisClient *redis.Client,
idempotencyKey string,
) (bool, error) {
if idempotencyKey == "" {
return false, nil
}
return redisClient.SetNX(
ctx,
fmt.Sprintf("mailwebhook:delivery:%s", idempotencyKey),
"claimed",
7*24*time.Hour,
).Result()
}
Use one operating rule: make delivery claiming atomic, and make every downstream action depend on that claim. That turns duplicate delivery into a normal infrastructure event instead of a business bug, because repeated requests can be recognized and handled safely without repeating side effects. (PostgreSQL Documentation - Constraints)
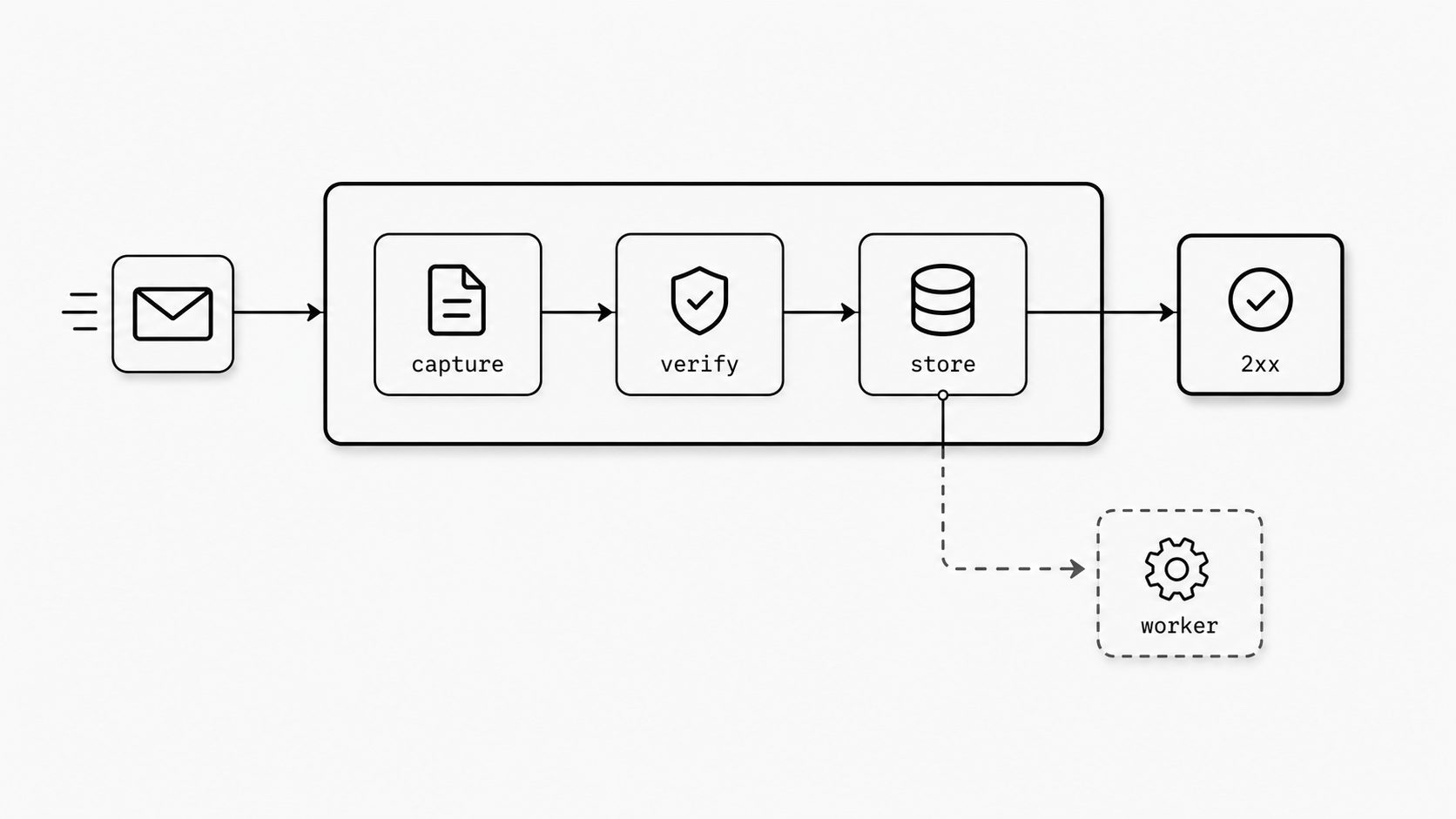
Why fast acknowledgment and background work matter
I have seen a simple email webhook turn into a reliability problem for one reason: the endpoint tried to finish the whole job before it answered the HTTP request. That feels safe at first. You want to be sure the message was processed. You want the database update, attachment handling, and routing logic to finish before you say “OK.” The trouble is that webhook delivery systems usually care first about whether your endpoint responded in time, not whether your full business workflow finished. When your receiver stays busy too long, retries become much more likely, and retries raise the odds of duplicate work, noisy logs, and confused incident reviews. In my experience, the fix is rarely exotic. A thin front door wins. Verify the request, make the event durable, and hand it off. Then let a worker do the heavy lifting after the response is already gone.
So what does that mean in practice for an inbound email webhook? I think of the receiver as a traffic cop, not a warehouse. Its job is to make a few fast decisions in a safe order: preserve the raw body, verify authenticity, claim the idempotency key, persist or enqueue the payload, and return a 2xx quickly. Everything else belongs behind that boundary. (Inbound Email Processing Architecture)
That boundary matters because the HTTP request is the most fragile part of the flow. If the process crashes during attachment parsing, if a downstream API stalls, or if your database is briefly slow, you do not want the sender to interpret that as “delivery failed” when you already had enough information to accept the event safely. A queue, durable table, or background job system gives you a cleaner contract. The receiver says, “I got it and stored it.” The worker says, “Now I will process it.” Those are two different promises, and separating them makes the system easier to reason about.
There is also a language-level reason to keep the response path short. Stripe documents that changing or parsing the request body before signature verification can break verification, which is a strong reminder that the raw request has to be handled carefully at the edge. Go’s net/http documentation also warns that depending on the HTTP protocol and intermediaries, it may not be possible to read from Request.Body after writing to the ResponseWriter, which supports a disciplined order of operations: read first, verify, store, respond, then let background code continue the real work. (Stripe Docs - Resolve webhook signature verification errors)
If I were sketching the handoff for Node.js, Python, or Go, the sequence would stay almost the same:
Capture the raw bytes. Verify the signature. Claim X-Idempotency-Key. Write the payload to durable storage or publish it to a queue. Return 202 Accepted or 200 OK. Then let a worker parse attachments, map senders, update records, or call the rest of your stack.
Here is the handoff in each language:
In Node.js, a Redis Stream is a small practical handoff point. The receiver can publish the verified event and return 202; a worker can consume from the stream on its own retry policy.
function getGenericEventId(event) {
return typeof event?.event?.id === "string" ? event.event.id : "";
}
export async function enqueueInboundEmail(redisClient, event, idempotencyKey) {
await redisClient.xAdd("mailwebhook:inbound-email", "*", {
idempotency_key: idempotencyKey,
event_id: getGenericEventId(event),
payload: JSON.stringify(event),
});
}
app.post(
"/webhooks/inbound-email",
express.raw({ type: "application/json", limit: "2mb" }),
async (req, res) => {
const signature = req.header("x-mailwebhook-signature");
const idempotencyKey = req.header("x-idempotency-key");
if (!verifySignature(req.body, signature)) {
return res.status(401).json({ error: "invalid signature" });
}
if (!idempotencyKey) {
return res.status(400).json({ error: "missing idempotency key" });
}
const event = JSON.parse(req.body.toString("utf8"));
if (!(await claimMailWebhookDelivery(redisClient, idempotencyKey))) {
return res.status(200).json({ duplicate: true });
}
await enqueueInboundEmail(redisClient, event, idempotencyKey);
return res.status(202).json({ accepted: true });
},
);
In Python, the same boundary is one xadd call after verification and idempotency. The worker can then read from mailwebhook:inbound-email without holding the original HTTP request open.
import json
from typing import Any
from flask import jsonify, request
from redis import Redis
redis_client = Redis.from_url("redis://localhost:6379/0")
def generic_event_id(event: dict[str, Any]) -> str:
"""Return the Generic JSON event ID for logging when present."""
generic_event = event.get("event")
if not isinstance(generic_event, dict):
return ""
event_id = generic_event.get("id")
return event_id if isinstance(event_id, str) else ""
def enqueue_inbound_email(
redis_client: Redis,
event: dict[str, Any],
idempotency_key: str,
) -> None:
"""Persist a verified inbound email event for asynchronous processing."""
redis_client.xadd(
name="mailwebhook:inbound-email",
fields={
"idempotency_key": idempotency_key,
"event_id": generic_event_id(event),
"payload": json.dumps(event),
},
)
@app.post("/webhooks/inbound-email")
def inbound_email_webhook():
raw_body = request.get_data(cache=False)
signature = request.headers.get("x-mailwebhook-signature")
idempotency_key = request.headers.get("X-Idempotency-Key")
if not verify_signature(raw_body, signature):
return jsonify({"error": "invalid signature"}), 401
if not idempotency_key:
return jsonify({"error": "missing idempotency key"}), 400
event = json.loads(raw_body)
if not claim_mailwebhook_delivery(redis_client, idempotency_key):
return jsonify({"duplicate": True}), 200
enqueue_inbound_email(redis_client, event, idempotency_key)
return jsonify({"accepted": True}), 202
In Go, XAdd gives the handler the same short request path. Read, verify, claim, enqueue, respond.
package webhooks
import (
"context"
"encoding/json"
"github.com/redis/go-redis/v9"
)
func EnqueueInboundEmail(
ctx context.Context,
redisClient *redis.Client,
event GenericPayload,
idempotencyKey string,
) error {
payload, err := json.Marshal(event)
if err != nil {
return err
}
return redisClient.XAdd(ctx, &redis.XAddArgs{
Stream: "mailwebhook:inbound-email",
Values: map[string]any{
"idempotency_key": idempotencyKey,
"event_id": event.Event.ID,
"payload": string(payload),
},
}).Err()
}
You might be wondering: does that make the system more complex? A little. It adds a queue or a jobs table. It adds a worker. Yet operationally it is usually simpler, because failures become isolated. The receiver can stay small and predictable. The worker can retry on its own rules. And when you debug an email to webhook path, you can see whether the problem happened at receipt time or during later processing, instead of mixing both into one long request path.
The practical payoff is straightforward: fast acknowledgment turns your receiver into a stable intake layer instead of a fragile all-in-one execution path. That lowers the chance of timeout-driven replays, keeps the signed request handling tight, and gives your team a cleaner place to scale heavy work like parsing, enrichment, and routing. If you are building an email webhook tutorial or production mail webhook endpoint, this is one of the highest-leverage design choices you can make early. I would rather operate two small steps with clear contracts than one oversized request path that has to be perfect every time.
The main takeaway is that a dependable inbound email receiver is not defined by how much work it can do inside one request. It is defined by doing the right small set of things in the right order: preserve bytes, verify authenticity, recognize replays, make the event durable, and return a fast success response.
For product context before implementing a receiver, Email Webhook API covers the endpoint-facing contract. The broader full mailbox-to-webhook workflow has its own page.
That pattern holds whether you implement it in Node.js, Python, or Go. The syntax changes, but the operational contract does not. If you keep the receiver thin and predictable, you get cleaner signature verification, safer replay handling, and a much more resilient path from inbound email to downstream business logic.